



 本文深入探讨Flink在流数据处理中的关键技术,包括数据流管道实现、状态管理、事件时间一致性、故障容错与有状态流处理。讲解了流与批处理的区别,以及Flink如何利用历史数据提升实时分析能力。
本文深入探讨Flink在流数据处理中的关键技术,包括数据流管道实现、状态管理、事件时间一致性、故障容错与有状态流处理。讲解了流与批处理的区别,以及Flink如何利用历史数据提升实时分析能力。
我只想踏踏实实的学技术,用技术。那就从官网开始,翻阅着官网,一页一页翻译思考实验表达,让理念落地,让抽象更加具体。
标题掌握Flink需要知道的:
- 如何实现流数据的处理管道?
- Flink如何实现管理状态以及为什么?
- 如何使用事件时间一致性计算准确的分析。
- 如何在持续的数据流上构建事件驱动型应用。
- FLink是如何实现故障容错机制、如何实现 精准一次的语义完成有状态的流数据处理。
这五个问题就是接下来文章的方向,也是Flink的重要特性。
Flink的数据流处理
流应该是数据自然的一种存在的状态,万事万物是不断变化的,而用数据描绘的万事万物同样也该处于不变变化之中的。所以像网站的访问购物数据,还有股票的呈现交易数据,这些都是以数据流的形式呈现的。
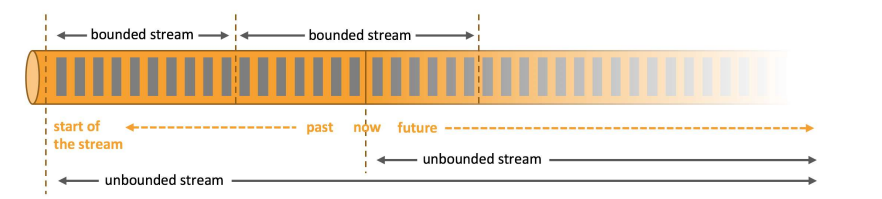
Batch processing: 批处理,处理的是有界数据流。就是图上的bounded stream有界流,它的界定有点类似高等数学中的有界区间【】,是数据流的有界区间。所以在批处理的过程中,可以注入整个数据集来处理获取结果。可以生成一些全局的统计和汇总的结果。同样的,将数据集截取出一部分区间,也是有界流。
如果能将数据流切分的足够细小,使其来而不知何方,或者去而不知何往,便也是无界数据流了。
Stream processing: 流数据处理,处理的无界数据流,Unbounded stream. 类似数学中的( )开区间,数据源源不断流过,所以就能在数据到达的时候持续的处理数据。
Flink构建的应用,通常都是由数据流以及用户自定义的转换操作单元组合起来的。这些数据流构建的有向图数据源头来自多种数据源,经转换后接入到不同的落地的接口中。
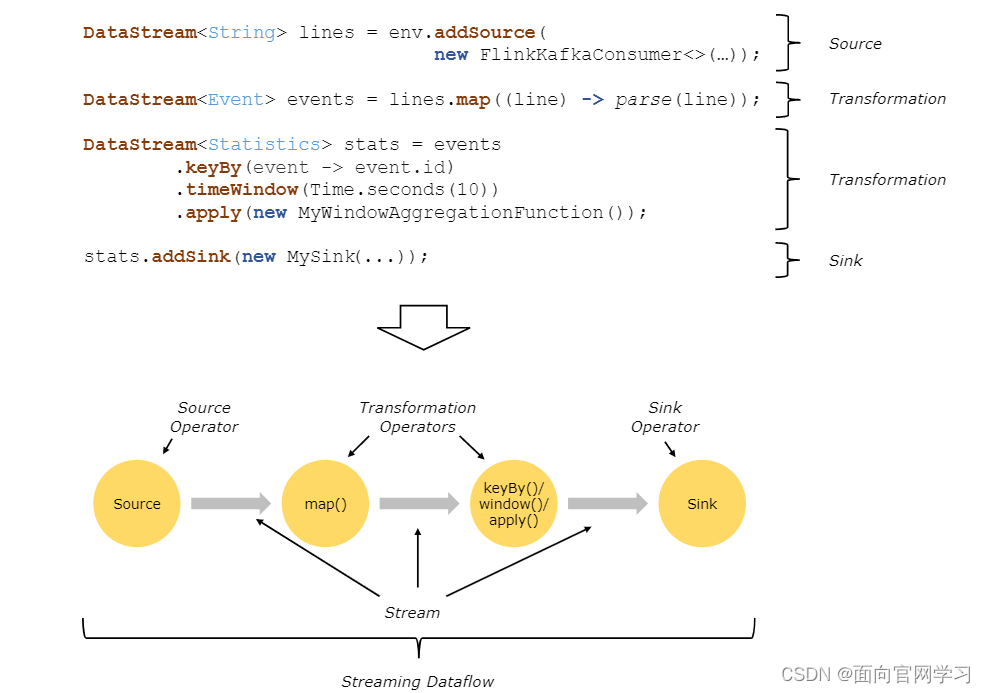
转换和操作单元可能是一对一或一对多的关系,Source和Sink的输入输出就是一个操作单元完成转换(数据加载和数据输出)。中间的数据处理部分的转换就是由两个操作单元构成的,map()数据散列 + keyBy() 数据聚合两个操作单元构成。
Flink实时流数据处理的不同:
有些消息队列的应用也能消费实时数据,比如Apache Kafka。而FLink是做到了不仅能处理实时数据,同样也能处理历史数据,就是上面提到的有界数据源。
或许一些人会觉得在实时数据分析中谈处理有界数据,历史数据,全量数据显得很鸡肋。因为那些事Hadoop,Hive在做的事情。但是事实上,重新处理历史数据非常重要。处理历史数据能发现事件的发生顺序,并用来识别风险或者推断事件能否或什么时候完成。
这样看来,关注事件发生的顺序比关注他们早或晚处理更加的重要。
有了这些历史积累的事件顺序经验,在实时数据流上就能更加快捷的发现问题,解决问题。
所以这样看来,历史数据成了Flink的一大亮点,就好像总听见人说我是写代码里面弹琴最好的,跳舞最好的。一个意思,但是Flink人家是相辅相成,也希望能看到我这博客的人圆融自己的人生,做相辅相成的事。
并行的数据流
Flink分布式的,快速对实时数据流进行转换的基础架构。
Flink的程序与生俱来拥有并行和分布式的能力。
在数据流处理过程中,一个数据流拥有多个数据流的分区,而一个操作单元又同时拥有多个子操作单元。并且这些子操作单元都是独立在不同容器下不同线程中的。
子操作单元的数量又叫操作单元的并行度,不同的操作单元的并行度是不同的。看图中,最后Sink的并行度是1,其他单元的并行度是2.
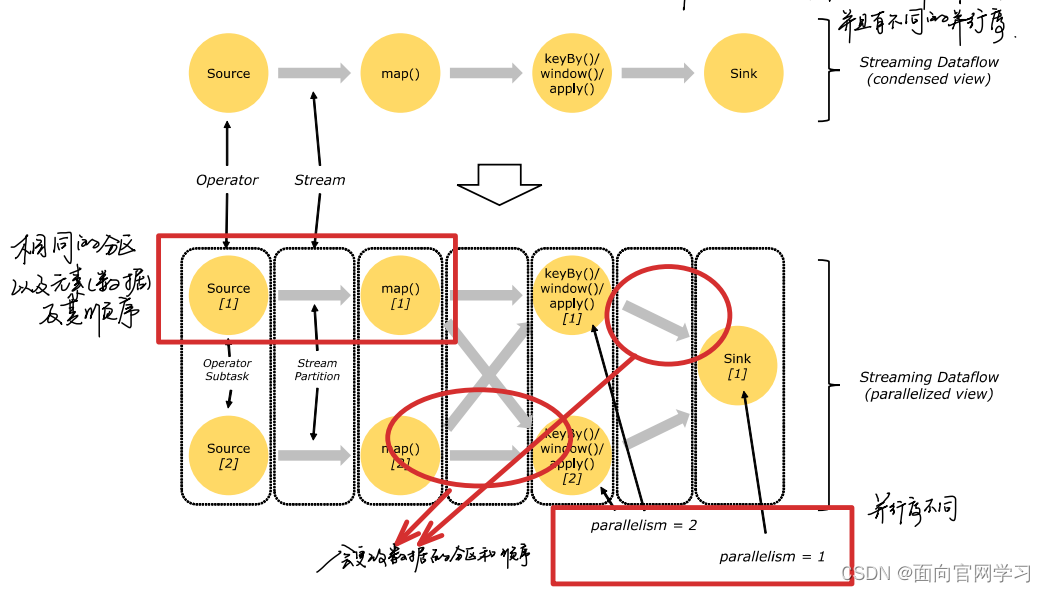
流在操作单元中传输有两种模式,一种模式是一对一的传输,另外一种重新分配的传输。
一对一的模式: 如上图source —> map之间的数据传输,传输两端数据流的分区和元素在流中顺序是不变的。
**重新分配的模式: ** 如上图 map-----> keyBy 或 keyBy ----> Sink ,和一对一不同,传输两端的流分区会发生改变。数据的顺序也同时会发生变化。而一个子操作单元数据到底传输到另一端的哪一个子操作单元上,取决于转换的方式。比如keyBy()重新分区取决于对数据key进行Hash操作的结果。不同key汇聚结果重新平衡后的结果是不确定的。这种正体现了重新分配模式的不确定性。
有状态的流的处理
Flink的流的操作是有状态的。
有状态是描述性的词汇,比如拿河流举例子,我们可以描述此刻河流的状态是浪比较大的,浪比较大就是一种状态。而这种状态并不是独立存在的,是前面很多阶段状态持续影响才产生现在的状态。就好像说社会上的你,并不单单是你,而是一切社会关系的总和一样。
数据流的状态的使用有很多方面,比如只计算每分钟事件的数量然后呈现在大屏上,也可以是信用卡欺诈检测生成的特征。
而我们的数据流处理过程的state更容易抽象描述成计算的中间结果和元数据,能更加的容易理解。
就比如我们WordCount的并行数据流的图:
在第三个操作单元为聚合操作,存在状态。其实更仔细的,第三个有状态的操作单元更像是一个key-value的小仓库,分成并行的两个部分,保存在本地的Stateful的部分是中间的临时结果,流过这个单元的相同键的数据会合并计算到对应的操作单元,之后再汇聚成最后的结果。
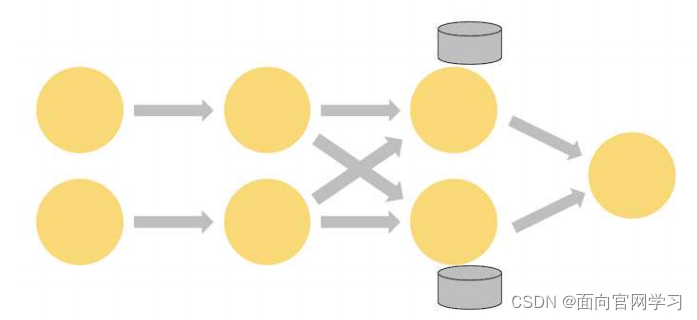
状态数据一般是保存在本地的,就像这样:

保存在磁盘,如果不太大可以保存在JVM中。这是保证Flink的流计算的高吞吐量和低延时的根本特性。
Flink的容错机制
Flink通过流的重播和状态的快照提供了容错的精确一次的语义。这些快照捕获分布式管道的整个状态,记录输入队列中的偏移量,以及作业图中由于接收到该点的数据而产生的状态(状态的变化)。 当出现故障时,源会被倒放,状态会恢复,处理也会恢复。 如上所述,这些状态快照是异步捕获的,不会妨碍正在进行的处理。
基本上对Flink流处理的基本概念,分布式并行的计算框架以及有状态的流的处理和容错机制等有了些大概的、关键性的概括和描述。其中加了很多自己的理解,希望各位能积极的留言批评指定。希望一起探讨获得更具象的概念去理解这些抽象的理念。
希望大家关注我的账号,每天抽出些时间跟随着我的脚步读下来,很多概念也就不断的扎根到脑海中,我相信总会在未来的某一刻能迸发出火花,帮助我们解决面对的问题。

















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









