




1 前言:
自从去年2024年大学毕业之后到现在,前后从事过两段开发的工作了:
第一个是在网易做后端开发,第二个是在青塔科技做爬虫。然后呢,在今年的7月份算是裸辞在做独立开发者以及同时做青少年编程教育这个行业,并且也在手底下带教近30位同学,所以前段时间就想着给同学们做一款学习网站,这样的话,在课上可以跟着我学,放学之后呢,可以在家里看看技术,刷刷题,逛逛网站,可以让学习形成一个闭环,也算比较不错。
这个网站到目前为止其实已经做好了数月时间了,只是前段时间比较忙,一直没有去介绍。刚好最近比较轻松,所以就闲的没事。把这个网站介绍一下,也可以和各位同学互相交流一下。
目前这个网站项目做了如下的几个模块。那我会针对每一个模块的功能做详细的介绍,以及每一个模块的底层逻辑以及数据库的结构都会一一介绍。我们现在先把每一个模块给他讲一下,我的模块如下:
📖 基础模块:左侧展示文章的分类模块,右侧展示文章的具体内容,并且分类采用了手风琴组件效果,同时支持高效搜索文章!
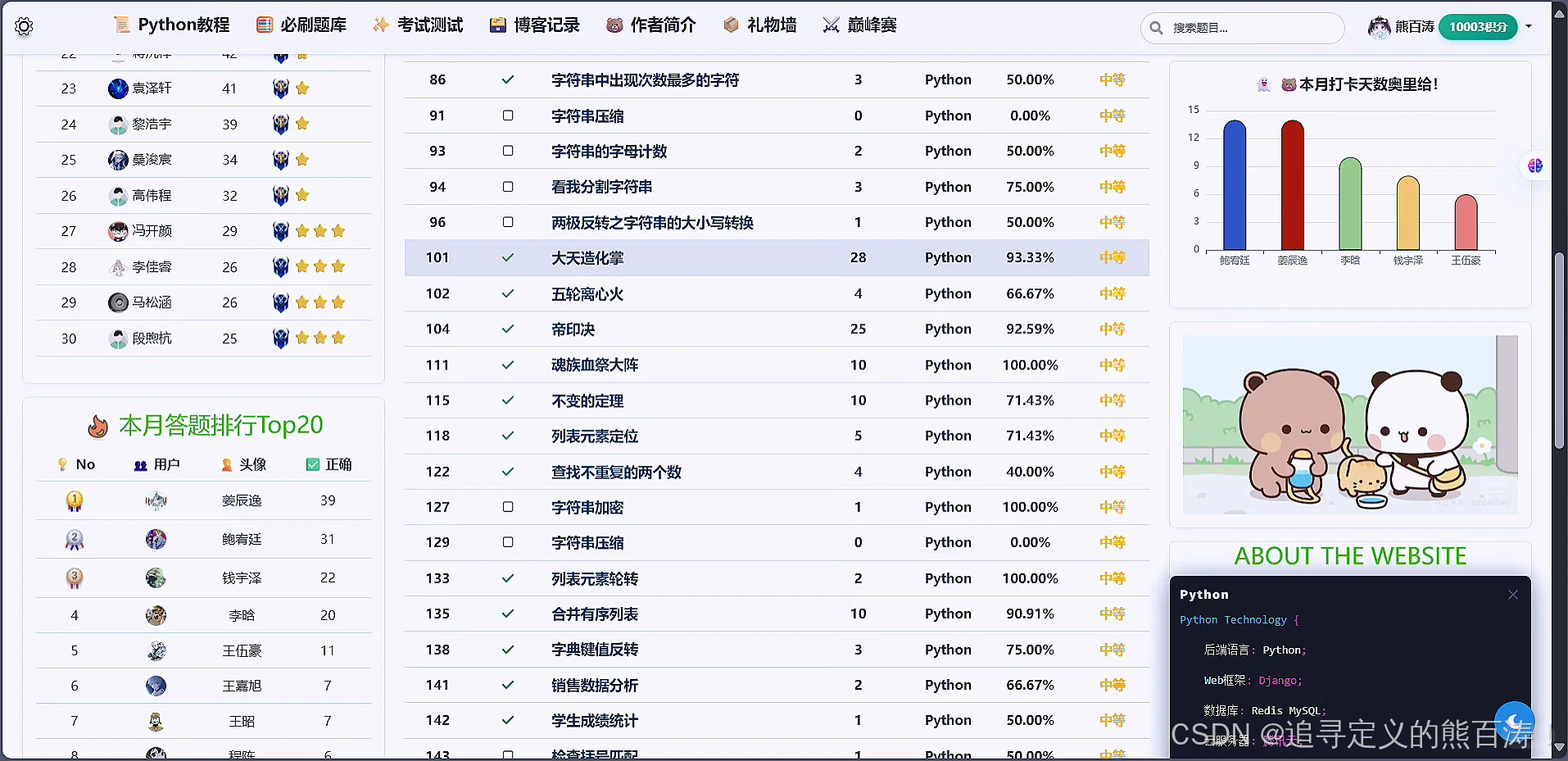
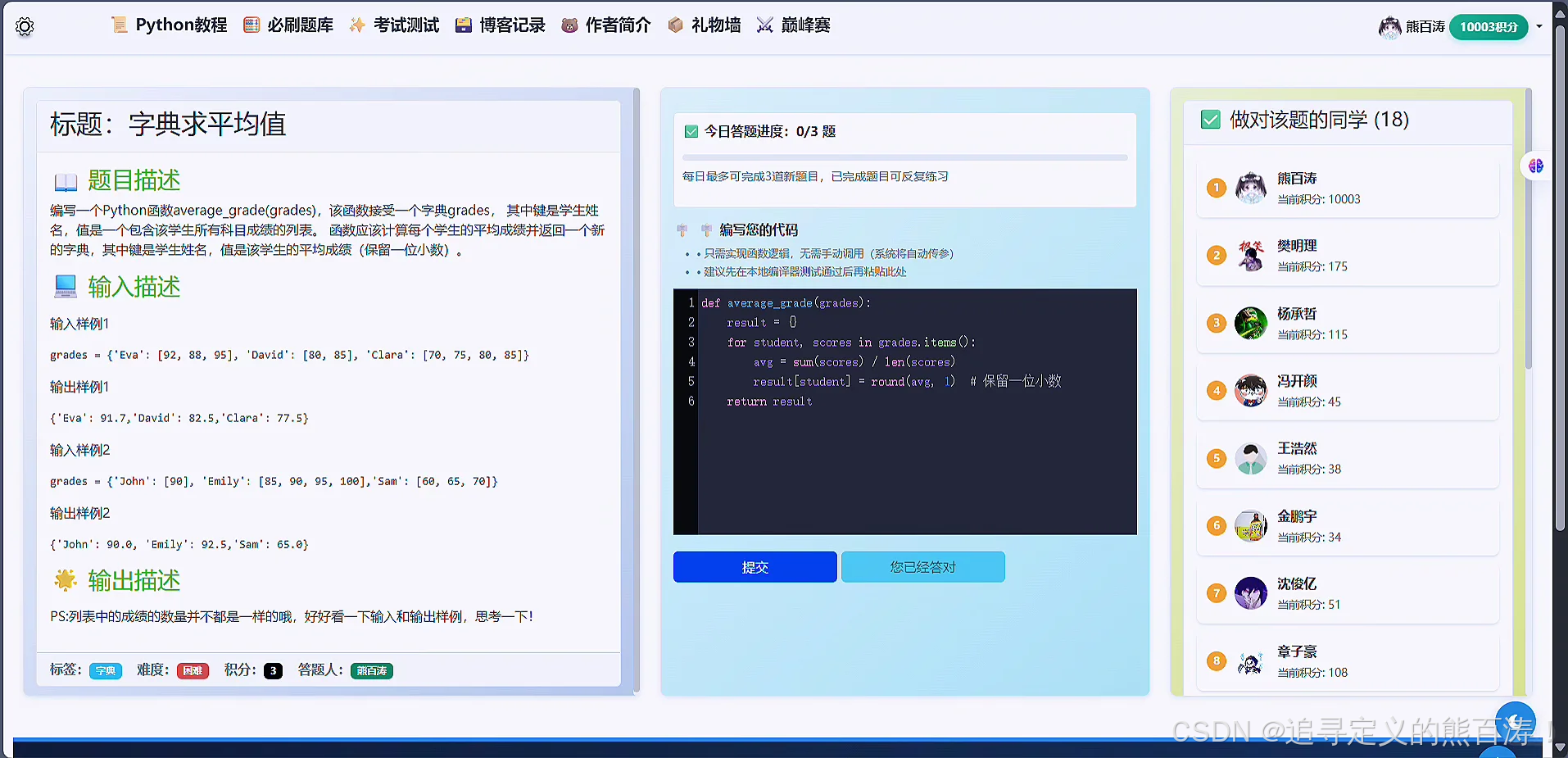
📖 题库模块:会展示数据库中的题目,并且按照分类正确率,难度等级,进行排名和筛选,左侧有成绩排行榜,右侧区域是汇集了积分排行榜,最新题目展示,学生热门报道展示,打卡天数可视化等展示等系列模块,答题可以获得积分,题目等级难度不同,积分不同,同时支持多维度搜索🔍!
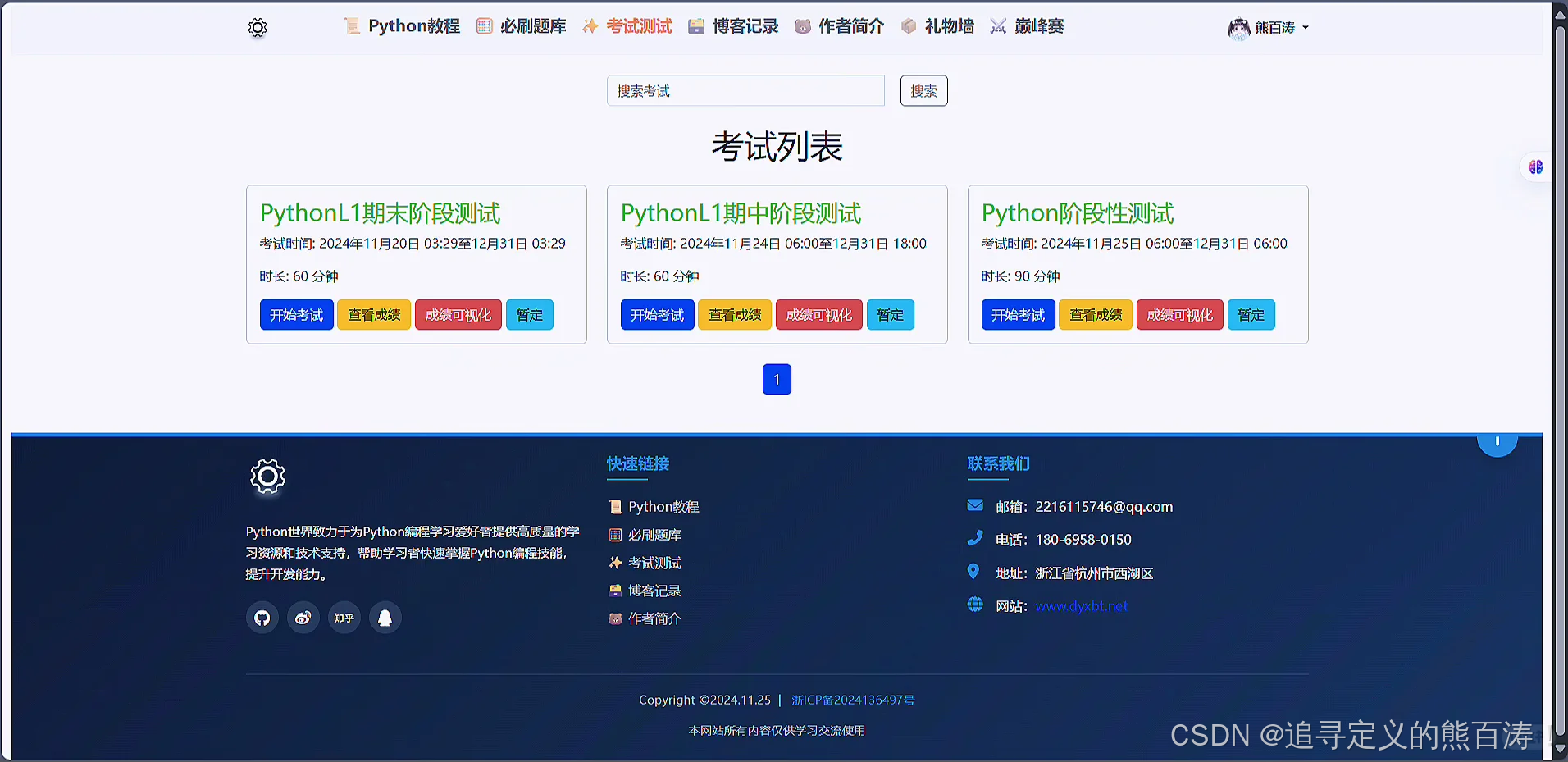
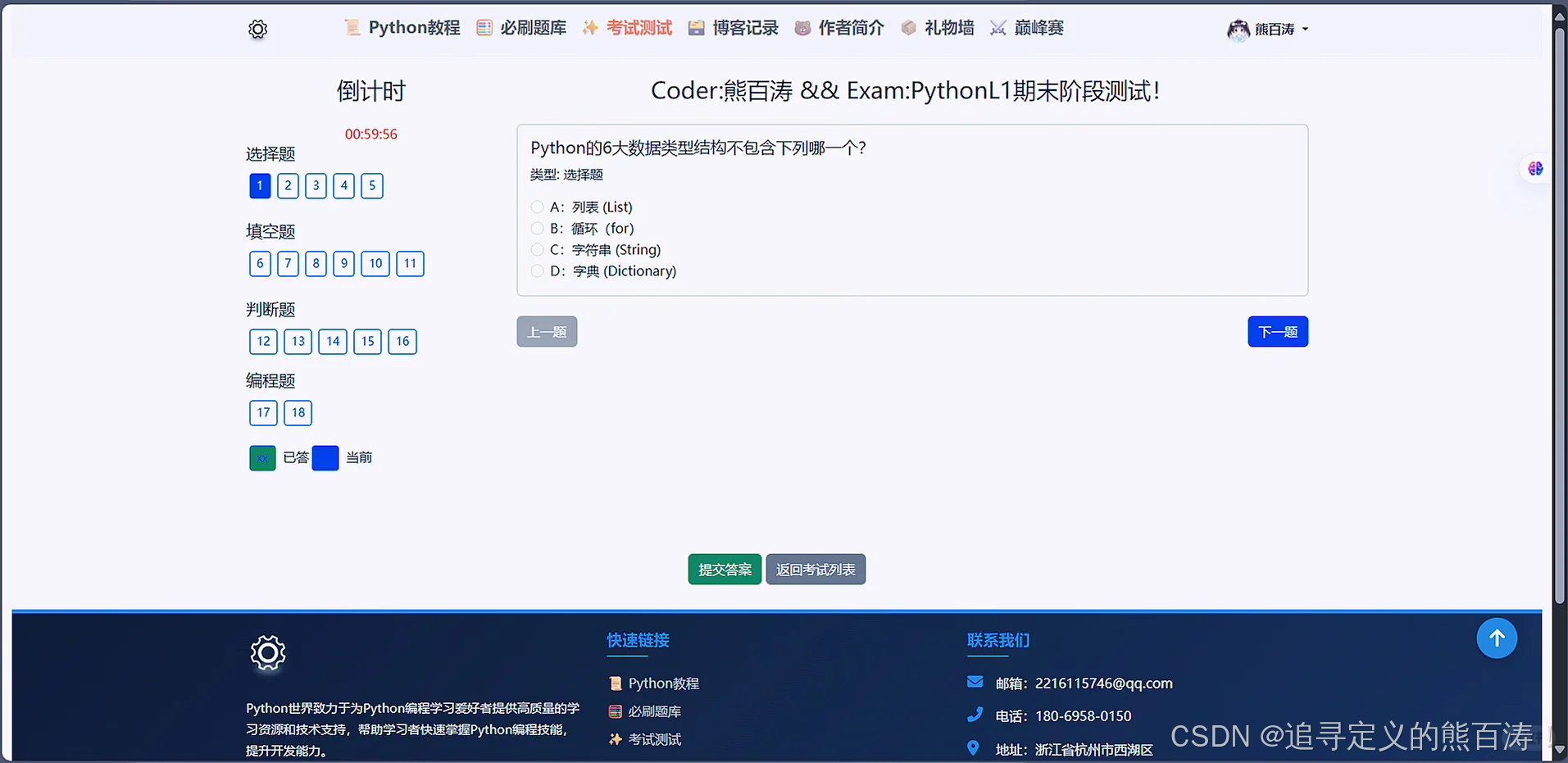
📖 考试模块:有可以考试的内容,管理员可以设置考试的内容和时间以及有权限查看所有成绩,普通用户没有权限查看.
📖 博客模块:是放置一些关于编程技术的博客,同样在右侧会显示热门博客和最近博客,并且允许用户全文搜索,旨在拓展同学们的眼界,了解更多的编程技术!
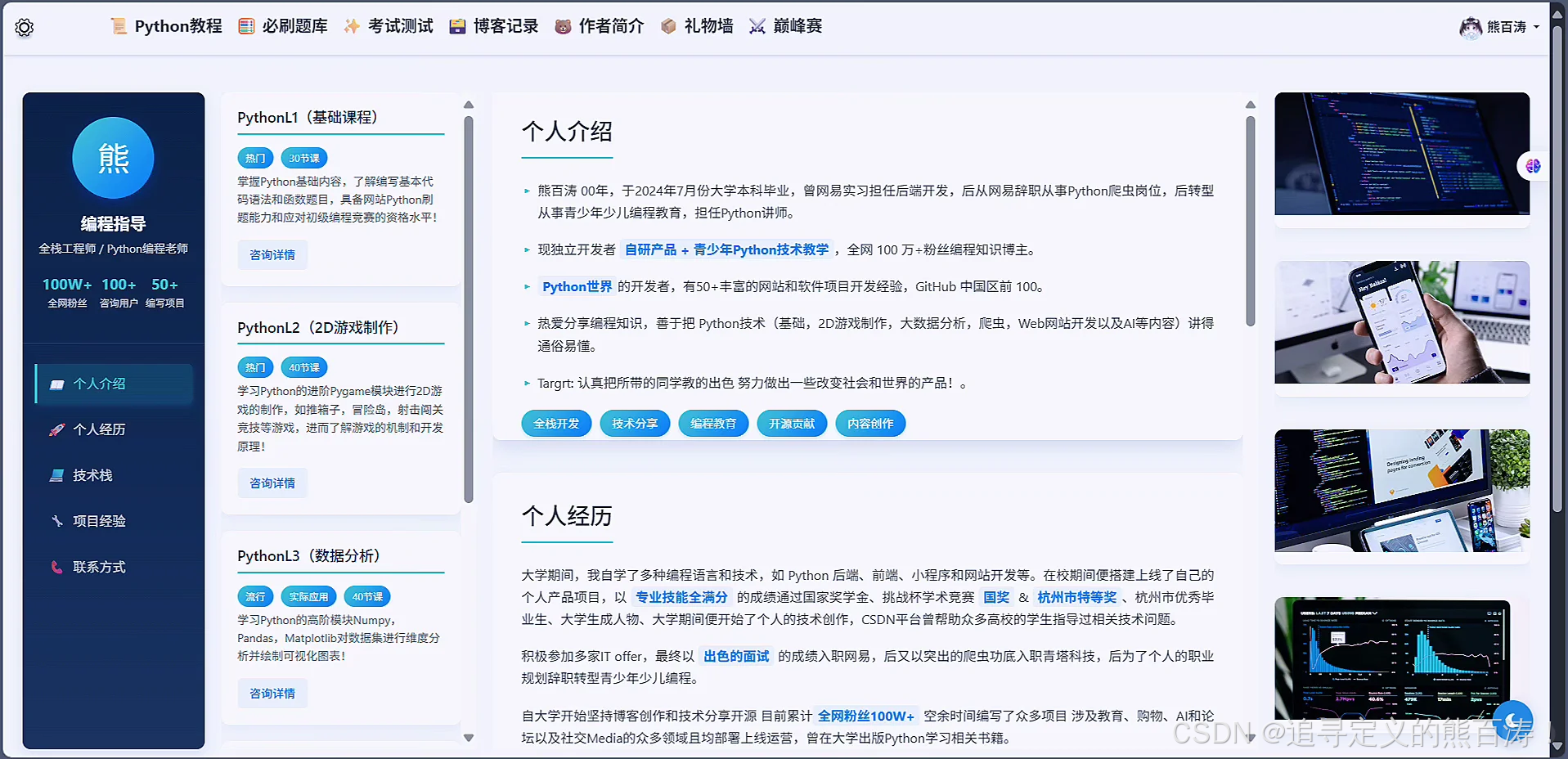
📖 作者简介模块:是展示作者本人信息.
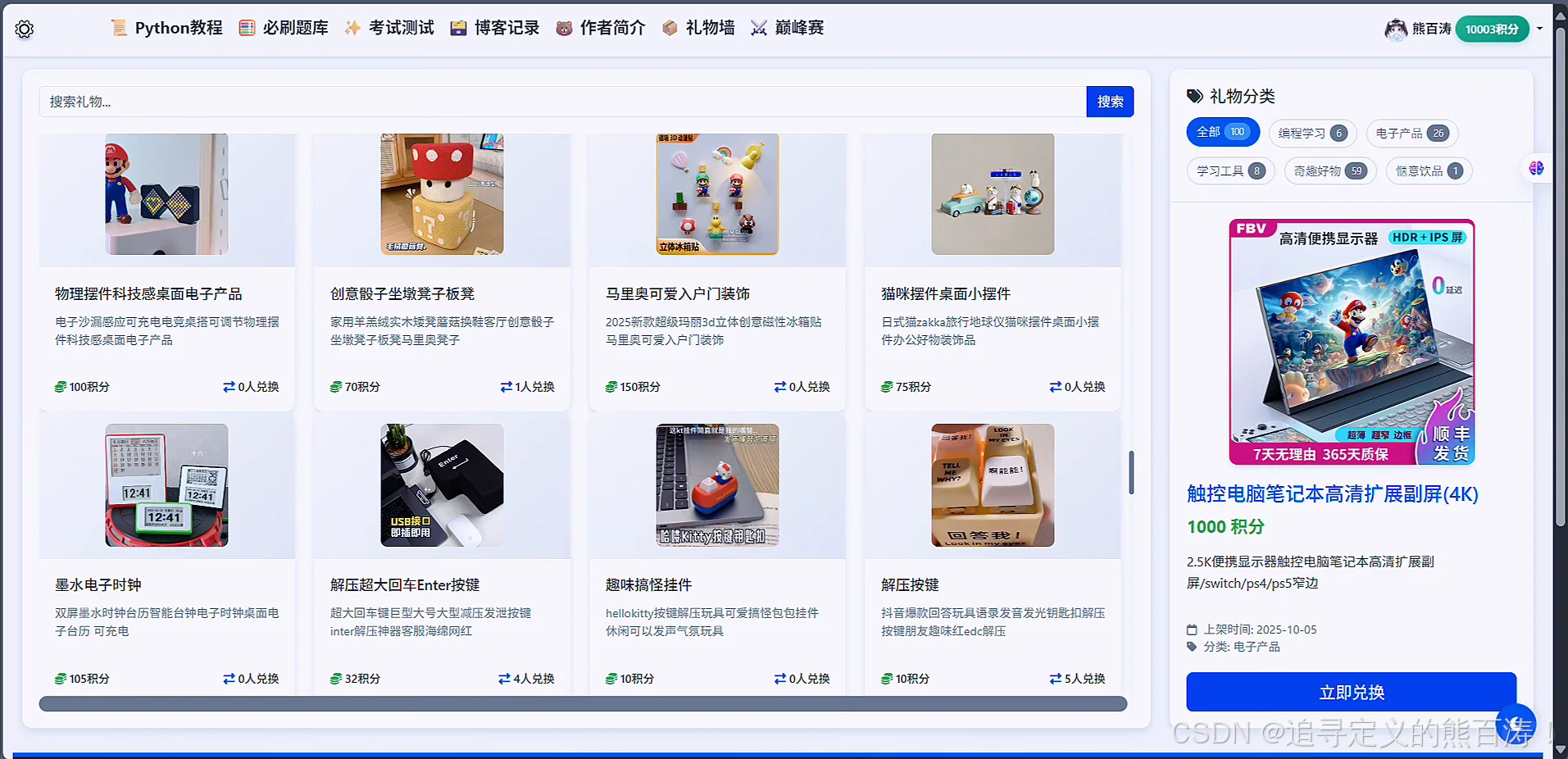
📖 礼物墙模块:用户消耗积分可以兑换礼物的.
📖 巅峰赛模块:展示相对较灵活复杂题目,同学可以挑战进阶 获取高额积分,同时学生也可以互相评论交流.
OK, 好的,这就是大致的每一个模块实现的功能,可能还有一些功能比较琐碎,我就没有去介绍了。重点呢是介绍了大概的模块。那么接下来我们就针对核心的两个模块进行一个展示。其他的呢,我们就不做赘述了。毕竟这个项目的工作量也是挺多的,我也陆陆续续投入了不少的工作量,我们就拿核心的来一个介绍,就介绍一下必刷题库以及相关的教程,还有礼物墙的兑换等等其他的呢,我们就不再做我介绍了。好的,现在进入到我们的技术部分。
2 网站技术剖析:
2.1 数据库架构解析:
2.1.1 项目数据库表字段结构
from django.db import models
from ckeditor.fields import RichTextField
from django.utils.safestring import mark_safe
from mdeditor.fields import MDTextField
class Group(models.Model):
name = models.CharField(max_length=100,verbose_name='战队名称')
signature = models.TextField(verbose_name='战队宣言', blank=True, default='')
def __str__(self):
return self.name
class Meta:
verbose_name = '战队总览'
verbose_name_plural = '战队总览'
class User(models.Model):
ROLE_CHOICES = [
(0, '普通'),
(1, '组长'),
]
username = models.CharField(verbose_name='用户名', max_length=32)
password = models.CharField(verbose_name='用户密码', max_length=64)
avatar = models.ImageField(upload_to='avatar', verbose_name='头像', default='avatar/avatar.jpg')
score = models.IntegerField(verbose_name='积分', default=0)
create_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True)
role = models.IntegerField(verbose_name='权限', choices=ROLE_CHOICES, default=0) # 新增的权限字段
group_war = models.ForeignKey('Group',on_delete=models.CASCADE,verbose_name='所属战队', null=True, blank=True)
# 新增字段
gender_choices = (
('男', '男'),
('女', '女'),
)
gender = models.CharField(
max_length=10,
verbose_name="性别选择",
choices=gender_choices,
default= '男'
)
address = models.CharField(verbose_name='居住地址', max_length=300, default='')
identity_choices = (
('学生', '学生'),
('家长', '家长'),
('其他', '其他'),
)
identity = models.CharField(
max_length=10,
verbose_name="身份选择",
choices=identity_choices,
default= '学生'
)
signature = models.TextField(verbose_name='个性签名', blank=True, default='')
grade_choices = (
('小学','小学'),
('初中','初中'),
('高中','高中'),
('大学','大学'),
('硕博','硕博'),
('其他/已毕业','其他/已毕业'),
)
grade = models.CharField(
max_length=30,
verbose_name='年级选择',
choices=grade_choices,
default= '小学'
)
def admin_sample(self):
return mark_safe('<img src="/media/%s" height="60" width="60" />' % (self.avatar,))
admin_sample.short_description = '用户头像'
admin_sample.allow_tags = True
def __str__(self):
return self.username
class Meta:
verbose_name = '用户总览'
verbose_name_plural = '用户总览'
class Problem(models.Model):
DIFFICUTY_CHOICES = (
('简单', '简单'),
('中等', '中等'),
('困难', '困难'),
)
title = models.CharField(
max_length=200,
verbose_name="题目标题"
)
description = RichTextField(verbose_name="题目描述")
input_description = RichTextField(verbose_name="输入描述")
output_description = RichTextField(verbose_name="输出描述")
score = models.IntegerField(verbose_name='获得积分', default=1, help_text='简单1分,中等2分,难3分')
difficulty = models.CharField(
max_length=10,
verbose_name="难度等级",
choices=DIFFICUTY_CHOICES,
)
tags = models.ForeignKey(
'Tag',
on_delete=models.CASCADE,
verbose_name="标签"
)
class Meta:
verbose_name = "题库编程题目"
verbose_name_plural = "题库编程题目"
def __str__(self):
return self.title
# 题库标签
class Tag(models.Model):
name = models.CharField(max_length=200, unique=True, verbose_name="题库标签名称")
def __str__(self):
return self.name
class Meta:
verbose_name = "题库编程题目标签"
verbose_name_plural = "题库编程题目标签"
class Blog(models.Model):
title = models.CharField(max_length=200, verbose_name="博客标题")
image = models.ImageField(verbose_name="封面", upload_to='Blog/')
content = MDTextField(verbose_name="博客内容")
create_time = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
tags = models.ForeignKey('BTag', on_delete=models.CASCADE, verbose_name="标签") # 使用 ManyToManyField 以支持多个标签
view_count = models.PositiveIntegerField(default=0, verbose_name="浏览次数")
author = models.CharField(max_length=100, verbose_name="发布者")
def __str__(self):
return self.title
class Meta:
verbose_name = "我的博客"
verbose_name_plural = "我的博客"
# 博客标签
class BTag(models.Model):
name = models.CharField(max_length=200, unique=True, verbose_name="标签名称")
def __str__(self):
return self.name
class Meta:
verbose_name = "我的博客标签"
verbose_name_plural = "我的博客标签"
class Points(models.Model):
title = models.CharField(max_length=200, verbose_name="标题")
content = MDTextField(verbose_name="内容")
create_time = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
parent = models.ForeignKey('self', on_delete=models.CASCADE, null=True, blank=True, related_name='children',verbose_name="父级")
view_count = models.PositiveIntegerField(default=0, verbose_name="浏览次数")
author = models.CharField(max_length=100, verbose_name="发布者")
def __str__(self):
return self.title
class Meta:
verbose_name = "基础知识"
verbose_name_plural = "基础知识"
# # 知识点标签
# class PTag(models.Model):
# name = models.CharField(max_length=200, unique=True, verbose_name="标签名称")
# def __str__(self):
# return self.name
# class Meta:
# verbose_name = "基础知识标签"
# verbose_name_plural = "基础知识标签"
# 提交记录
class Submission(models.Model):
user = models.ForeignKey(
User,
on_delete=models.CASCADE,
verbose_name="用户"
)
problem = models.ForeignKey(
Problem,
on_delete=models.CASCADE,
verbose_name="题目"
)
submission_time = models.DateTimeField(
auto_now_add=True,
verbose_name="提交时间",
)
code = models.TextField(verbose_name="提交代码")
result = models.BooleanField(verbose_name="是否正确")
class Meta:
verbose_name = "题库编程题目提交记录"
verbose_name_plural = "题库编程题目提交记录"
def __str__(self):
return f"{self.user.username} - {self.problem.id} - {self.result}"
# 公告
class Announcement(models.Model):
title = models.CharField(max_length=200, verbose_name="公告标题")
created_at = models.DateTimeField(auto_now_add=True, verbose_name="发布时间")
creator = models.CharField(max_length=100, verbose_name="发布人")
view_count = models.PositiveIntegerField(default=0, verbose_name="浏览次数")
content = MDTextField(verbose_name="公告内容")
class Meta:
verbose_name = "系统公告"
verbose_name_plural = "系统公告"
def __str__(self):
return self.title
# 测试用例
class TestCase(models.Model):
problem = models.ForeignKey(Problem, on_delete=models.CASCADE, related_name='test_cases', verbose_name="题目")
input_data = models.TextField(help_text='输入数据,每个参数之间用;隔开')
expected_output = models.TextField(help_text='预期输出结果')
class Meta:
verbose_name = '题库编程题目测试用例'
verbose_name_plural = '题库编程题目测试用例'
def __str__(self):
return f"{self.problem.title} - {self.input_data[:50]}..."
class Exam(models.Model):
title = models.CharField(max_length=200, verbose_name="考试名称")
start_time = models.DateTimeField(verbose_name="考试时间")
duration = models.PositiveIntegerField(verbose_name="考试时长(分钟)")
deadline = models.DateTimeField(verbose_name="截止做答日期", null=True, blank=True)
is_open = models.BooleanField(default=False, verbose_name="是否开放")
def __str__(self):
return self.title
class Meta:
verbose_name = "考试总览"
verbose_name_plural = "考试总览"
class Question(models.Model):
QUESTION_TYPE_CHOICES = (
('选择题', '选择题'),
('填空题', '填空题'),
('判断题', '判断题'),
('编程题', '编程题'),
)
exam = models.ForeignKey('Exam', on_delete=models.CASCADE, related_name='questions', verbose_name="考试")
title = models.CharField(max_length=200, verbose_name="题目标题")
question_type = models.CharField(max_length=20, choices=QUESTION_TYPE_CHOICES, verbose_name="题目类型")
options = models.JSONField(max_length=100,blank=True, null=True, verbose_name="选择题选项") # 用于存储选择题选项
# 答案相关字段
choice_answer = models.CharField(max_length=200, blank=True, null=True, verbose_name="选择题/填空题答案")
score = models.IntegerField(verbose_name='分值', blank=True, null=True)
is_true = models.BooleanField(default=False, verbose_name="判断题答案") # 适用于判断题
test_input = models.TextField(blank=True, null=True, verbose_name="编程题输入测试") # 适用于编程题
expected_output = models.TextField(blank=True, null=True, verbose_name="编程题预期输出") # 适用于编程题
def __str__(self):
return self.title
class Meta:
verbose_name = "考试题目内容"
verbose_name_plural = "考试题目内容"
class ExamScore(models.Model):
user = models.ForeignKey('User', on_delete=models.CASCADE, verbose_name="用户")
exam = models.ForeignKey('Exam', on_delete=models.CASCADE, verbose_name="考试")
score = models.PositiveIntegerField(verbose_name="分数")
created_at = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
def __str__(self):
return f"{self.user.username} - {self.exam.title} - {self.score}"
class Meta:
verbose_name = "考试成绩"
verbose_name_plural = "考试成绩"
class QuesCase(models.Model):
question = models.ForeignKey('Question', on_delete=models.CASCADE, related_name='test_cases',
verbose_name="考试问题")
input_data = models.TextField(help_text='输入数据,每个参数之间用;隔开')
expected_output = models.TextField(help_text='预期输出结果')
class Meta:
verbose_name = '考试编程题用例'
verbose_name_plural = '考试编程题用例'
def __str__(self):
return f"{self.question.title} - {self.input_data[:50]}..."
class ToolType(models.Model):
name = models.CharField(max_length=100, verbose_name="工具名称")
class Meta:
verbose_name = "工具类型"
verbose_name_plural = "工具类型"
def __str__(self):
return self.name
class ToolWebsite(models.Model):
name = models.CharField(max_length=100, verbose_name="网站名称")
description = models.TextField(blank=True, verbose_name="网站描述")
type = models.ForeignKey('ToolType',on_delete=models.CASCADE, related_name='Webtype',
verbose_name="网站类型")
logo = models.ImageField(upload_to="logos/", blank=True, null=True, verbose_name="网站Logo")
link = models.URLField(verbose_name="网站链接")
created_at = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
updated_at = models.DateTimeField(auto_now=True, verbose_name="更新时间")
class Meta:
verbose_name = "工具网站"
verbose_name_plural = "工具网站"
def __str__(self):
return self.name
class GiftType(models.Model):
name = models.CharField(max_length=100, verbose_name="礼物类型名称")
class Meta:
verbose_name = "礼物类型"
verbose_name_plural = "礼物类型"
def __str__(self):
return self.name
class Gift(models.Model):
name = models.CharField(max_length=100, verbose_name="礼物名称")
description = models.TextField(blank=True, verbose_name="礼物描述")
type = models.ForeignKey('GiftType', on_delete=models.CASCADE, related_name='Webtype',
verbose_name="礼物类型")
required_points = models.PositiveIntegerField(verbose_name="所需积分")
image = models.ImageField(upload_to="gift_images/", blank=True, null=True, verbose_name="礼物图片")
created_at = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
class Meta:
verbose_name = "礼物总览"
verbose_name_plural = "礼物总览"
def __str__(self):
return self.name
# 新增:礼物兑换记录表(核心新增模型)
class GiftExchange(models.Model):
STATUS_CHOICES = (
(False, '未发放'),
(True, '已发放'),
)
user = models.ForeignKey(
'User',
on_delete=models.CASCADE,
related_name='gift_exchanges',
verbose_name="兑换用户"
)
gift = models.ForeignKey(
'Gift',
on_delete=models.CASCADE,
related_name='exchanges',
verbose_name="兑换礼物"
)
exchange_time = models.DateTimeField(
auto_now_add=True,
verbose_name="兑换时间"
)
is_issued = models.BooleanField(
default=False,
choices=STATUS_CHOICES,
verbose_name="是否已发放"
)
class Meta:
verbose_name = "礼物兑换记录"
verbose_name_plural = "礼物兑换记录"
# 防止重复兑换(同一用户同一礼物只能兑换一次,可根据需求删除)
# unique_together = ('user', 'gift')
def __str__(self):
return f"{self.user.username} - {self.gift.name} - {'已发放' if self.is_issued else '未发放'}"
class PeakSeason(models.Model):
"""巅峰赛季"""
SEASON_STATUS = (
('upcoming', '即将开始'),
('ongoing', '进行中'),
('finished', '已结束'),
)
name = models.CharField(max_length=200, verbose_name="赛季名称")
description = MDTextField(verbose_name="赛季描述")
content = MDTextField(verbose_name="赛季详情内容") # Markdown格式
start_time = models.DateTimeField(verbose_name="开始时间")
end_time = models.DateTimeField(verbose_name="结束时间")
status = models.CharField(
max_length=10,
choices=SEASON_STATUS,
default='upcoming',
verbose_name="赛季状态"
)
views = models.PositiveIntegerField(default=0, verbose_name="浏览量") # 新增浏览量字段
is_top = models.BooleanField(default=False, verbose_name="是否置顶") # 新增置顶字段
score = models.PositiveIntegerField(default=100,verbose_name='奖励积分')
created_at = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
is_active = models.BooleanField(default=True, verbose_name="是否激活")
class Meta:
verbose_name = "巅峰赛季"
verbose_name_plural = "巅峰赛季"
ordering = ['-is_top', '-created_at'] # 修改排序规则:置顶的在前,然后按时间倒序
def __str__(self):
return self.name
def increase_views(self):
"""增加浏览量"""
self.views += 1
self.save(update_fields=['views'])
@property
def is_current(self):
"""判断是否为当前赛季"""
now = timezone.now()
return self.start_time <= now <= self.end_time and self.is_active
def get_content_as_html(self):
# 将markdown转换为HTML
return markdown.markdown(self.content, extensions=[
'markdown.extensions.extra',
'markdown.extensions.codehilite',
])
class PeakComment(models.Model):
"""巅峰赛评论"""
season = models.ForeignKey(
PeakSeason,
on_delete=models.CASCADE,
related_name='comments',
verbose_name="所属赛季"
)
user = models.ForeignKey(
User,
on_delete=models.CASCADE,
verbose_name="评论用户"
)
content = MDTextField(verbose_name="评论内容", max_length=1000)
parent = models.ForeignKey(
'self',
on_delete=models.CASCADE,
null=True,
blank=True,
related_name='replies',
verbose_name="父评论"
)
created_at = models.DateTimeField(auto_now_add=True, verbose_name="评论时间")
likes = models.PositiveIntegerField(default=0, verbose_name="点赞数")
is_active = models.BooleanField(default=True, verbose_name="是否显示")
class Meta:
verbose_name = "巅峰赛评论"
verbose_name_plural = "巅峰赛评论"
ordering = ['created_at']
def __str__(self):
return f"{self.user.username} - {self.content[:20]}"
@property
def is_reply(self):
"""判断是否为回复评论"""
return self.parent is not None
def get_replies(self):
"""获取所有回复"""
return self.replies.filter(is_active=True).order_by('created_at')
2.1.2 数据库字段分析:
这是一个Django的models.py文件,定义了一个在线编程竞赛系统的数据模型。下面我将逐类分析每个模型的作用和字段含义。
-
Group(战队):
-
字段:名称(name)、宣言(signature)。
-
用于表示用户组成的战队。
-
-
User(用户):
-
字段:用户名、密码、头像、积分、创建时间、权限(普通/组长)、所属战队(外键)、性别、居住地址、身份、个性签名、年级。
-
用户有权限角色,可以属于一个战队,有个人信息和积分。
-
-
Problem(编程题目):
-
字段:标题、描述(富文本)、输入描述、输出描述、积分、难度、标签(外键)。
-
题目有难度分类和标签,积分根据难度设定。
-
-
Tag(题目标签):
-
字段:名称。
-
用于对编程题目进行分类。
-
-
Blog(博客):
-
字段:标题、封面、内容(Markdown)、创建时间、标签(外键)、浏览次数、作者。
-
博客文章,支持Markdown格式,有标签和浏览次数。
-
-
BTag(博客标签):
-
字段:名称。
-
用于对博客文章进行分类。
-
-
Points(知识点):
-
字段:标题、内容(Markdown)、创建时间、父级(自关联,用于构建树形结构)、浏览次数、作者。
-
用于表示基础知识点的树形结构。
-
-
Submission(提交记录):
-
字段:用户(外键)、题目(外键)、提交时间、代码、结果(布尔值)。
-
记录用户对题目的代码提交和结果。
-
-
Announcement(公告):
-
字段:标题、发布时间、发布人、浏览次数、内容(Markdown)。
-
系统公告。
-
-
TestCase(测试用例):
-
字段:题目(外键)、输入数据、预期输出。
-
用于编程题的测试。
-
-
Exam(考试):
-
字段:考试名称、开始时间、考试时长、截止时间、是否开放。
-
表示一场考试。
-
-
Question(考试题目):
-
字段:考试(外键)、标题、题目类型(选择/填空/判断/编程)、选择题选项(JSON)、选择题/填空题答案、分值、判断题答案、编程题测试输入、编程题预期输出。
-
考试中的题目,支持多种题型。
-
-
ExamScore(考试成绩):
-
字段:用户(外键)、考试(外键)、分数、创建时间。
-
记录用户在某场考试中的得分。
-
-
QuesCase(考试编程题用例):
-
字段:问题(外键)、输入数据、预期输出。
-
用于考试中的编程题的测试用例。
-
-
ToolType(工具类型):
-
字段:名称。
-
对工具网站进行分类。
-
-
ToolWebsite(工具网站):
-
字段:名称、描述、类型(外键)、Logo、链接、创建时间、更新时间。
-
记录有用的工具网站。
-
-
GiftType(礼物类型):
-
字段:名称。
-
对礼物进行分类。
-
-
Gift(礼物):
-
字段:名称、描述、类型(外键)、所需积分、图片、创建时间。
-
积分商城中的礼物。
-
-
GiftExchange(礼物兑换记录):
-
字段:用户(外键)、礼物(外键)、兑换时间、是否已发放。
-
记录用户兑换礼物的记录和发放状态。
-
-
PeakSeason(巅峰赛季):
-
字段:赛季名称、描述、详情内容(Markdown)、开始时间、结束时间、状态、浏览量、是否置顶、奖励积分、创建时间、是否激活。
-
表示一个巅峰赛季,包含赛季详情和状态。
-
-
PeakComment(巅峰赛评论):
-
字段:赛季(外键)、用户(外键)、评论内容、父评论(自关联,用于回复)、评论时间、点赞数、是否显示。
-
用户对巅峰赛季的评论,支持回复。
-
这个数据库设计覆盖了一个在线编程竞赛系统的核心功能,包括用户管理、题目、考试、博客、知识点、工具网站、积分商城和巅峰赛季等模块。每个模型都定义了相应的字段和关联关系,并设置了Django管理后台的显示名称。
主要功能模块分析
1. 用户管理系统
User模型核心功能: - 用户身份验证(用户名/密码) - 权限管理(普通用户/组长) - 个人信息管理(头像、性别、地址、身份、年级等) - 积分系统 - 战队归属
2. 编程题库系统
Problem + Tag + Submission + TestCase - 题目分类(简单/中等/困难) - 富文本题目描述 - 提交记录追踪 - 自动化测试用例 - 积分奖励机制
3. 内容管理系统
Blog + BTag:博客系统 Points:知识库(树形结构) Announcement:公告系统
4. 考试评估系统
Exam + Question + ExamScore + QuesCase - 多题型支持(选择/填空/判断/编程) - 考试时间管理 - 成绩记录 - 编程题测试用例
5. 积分商城系统
GiftType + Gift + GiftExchange - 礼物分类 - 积分兑换 - 发放状态管理
6. 竞赛赛季系统
PeakSeason + PeakComment - 赛季管理 - 评论互动 - 置顶和状态管理
2.2 后端代码核心功能分析:
2.2.1 后端核心代码展示
import json,markdown
import uuid
from django.contrib import messages
from django.db.models import Count, Q, Case, When, F, OuterRef, Subquery, Max
from django.shortcuts import render, redirect, get_object_or_404
from app.all_form import RegisterForm, LoginForm, UserForm
from app.models import User, Submission, Problem, TestCase, Announcement, Blog, Exam, Points, QuesCase, ExamScore, \
ToolWebsite, ToolType, Gift, GiftType, BTag,GiftExchange
from utils_.main import *
from django.db.models.functions import TruncDate
from datetime import datetime
from django.shortcuts import render, get_object_or_404
from django.views.decorators.csrf import csrf_exempt
from django.utils.html import escape # 防XSS攻击
# Create your views here.
# 登入
@csrf_exempt
def login_(request):
'''登录'''
if request.method == 'GET':
form = LoginForm()
return render(request, 'login.html', {'form': form})
form = LoginForm(data=request.POST)
if form.is_valid():
username = form.cleaned_data['username']
user_object = User.objects.filter(
**form.cleaned_data
).first()
# 普通用户
if user_object:
request.session['user'] = {'username': user_object.username,
'id': user_object.id,
'avatar': user_object.avatar.url,
'role': user_object.get_role_display()} # 写入服务器的session,同时随机数存入了用户的cookie
messages.success(request, '登录成功')
return redirect('/edit_user/')
messages.success(request, '登录失败')
form.add_error('username', '用户名或密码错误!')
return render(request, 'login.html', {'form': form})
# 登出
def logout(request):
request.session.clear() # 清除session
return redirect('/login/')
@csrf_exempt
# 注册
def register(request):
'''注册'''
if request.method == 'GET':
form = RegisterForm()
return render(request, 'register.html', {'form': form})
form = RegisterForm(data=request.POST, files=request.FILES)
if form.is_valid():
form.cleaned_data.pop('comfirmpassword') # pop拿走以后就没有了
User.objects.create(
**form.cleaned_data
)
messages.success(request, '注册成功')
return redirect('/login/')
return render(request, 'register.html', {'form': form})
# 编辑用户信息
def edit_user(request):
user = User.objects.get(pk=request.session['user']['id'])
if request.method == 'POST':
form = UserForm(request.POST, request.FILES, instance=user)
if form.is_valid():
cleaned_data = form.cleaned_data
user = form.save(commit=False) # 暂不保存
# 处理密码:如果填写了新密码,则更新为明文;否则保持原密码
new_password = cleaned_data.get('password')
if new_password:
user.password = new_password # 直接赋值明文密码,不哈希
# 若未填写新密码,则不修改(保持原有值)
# 保存所有字段(包括新增字段)
user.save()
# 更新session中的用户信息(确保页面显示最新数据)
request.session['user'] = {
'id': user.id,
'username': user.username,
'avatar': user.avatar.url,
# 可补充其他需要的字段
}
messages.success(request, '用户信息修改成功!')
return redirect('index') # 跳转至首页或个人中心
else:
form = UserForm(instance=user)
return render(request, 'edit_user.html', {'form': form})
def index(request):
# 获取请求参数
tag = request.GET.get('tag', '')
search_query = request.GET.get('search', '').strip()
difficulty = request.GET.get('difficulty', '') # 难度筛选参数
# 计算每个用户答对的不同题目数量
user_rankings = (
Submission.objects.filter(
result=True,
user__role=0 # 过滤普通用户
)
.values('user', 'problem')
.distinct()
.values('user')
.annotate(correct_problem_count=Count('problem', distinct=True))
.order_by('-correct_problem_count')
)
user_all_rankings = (
Submission.objects.filter(
result=True,
)
.values('user', 'problem')
.distinct()
.values('user')
.annotate(correct_problem_count=Count('problem', distinct=True))
.order_by('-correct_problem_count')
)
# 获取答题正确数排名前50的普通用户
top_five_correct = user_rankings[:30]
top_five_correct_list = []
for user_stat in top_five_correct:
user = User.objects.get(id=user_stat['user'])
top_five_correct_list.append({
'user': user,
'correct': user_stat['correct_problem_count'],
'role_display': user.get_role_display()
})
# 获取本月答题排行Top30
first_day_of_month = timezone.now().replace(day=1, hour=0, minute=0, second=0, microsecond=0)
top_five_correct_this_month = (
Submission.objects.filter(result=True, user__role=0, submission_time__gte=first_day_of_month)
.values('user', 'problem')
.distinct()
.values('user')
.annotate(correct_problem_count=Count('problem', distinct=True))
.order_by('-correct_problem_count')[:20]
)
user_cache = {}
top_ten_this_month = []
for user_stat in top_five_correct_this_month:
user_id = user_stat['user']
if user_id not in user_cache:
user_cache[user_id] = get_object_or_404(User, id=user_id)
user = user_cache[user_id]
top_ten_this_month.append({'user': user, 'correct': user_stat['correct_problem_count']})
# 获取今日答题排行Top10
today = datetime.now().date()
top_five_correct_today = (
Submission.objects.filter(result=True, submission_time__date=today)
.values('user', 'problem')
.distinct()
.values('user')
.annotate(correct_problem_count=Count('problem', distinct=True))
.order_by('-correct_problem_count')[:10]
)
top_ten_today = []
for user_stat in top_five_correct_today:
user = User.objects.get(id=user_stat['user'])
top_ten_today.append({'user': user, 'correct': user_stat['correct_problem_count']})
# 获取当前用户信息
user = User.objects.get(id=request.session['user']['id'])
cent = user.score
# 当前用户排名
current_user_correct_count = 0
for rank, user_stat in enumerate(user_all_rankings, start=1):
if user_stat['user'] == user.id:
current_user_correct_count = user_stat['correct_problem_count']
# 当前用户积分排名
current_user_rank = User.objects.filter(score__gt=user.score).count() + 1
# 获取各难度级别上用户答对题目的数量
difficulty_correct_counts = Submission.objects.filter(
user=user, result=True
).values('problem_id', 'problem__difficulty').distinct()
difficulty_correct_counts_dict = {'简单': 0, '中等': 0, '困难': 0}
for item in difficulty_correct_counts:
difficulty_correct_counts_dict[item['problem__difficulty']] += 1
# 进度条计算
all_problems_mun = len(Problem.objects.all())
current_user_id = request.session['user'].get('id')
user_correct_problem_count = 0
for item in user_all_rankings:
if item['user'] == current_user_id:
user_correct_problem_count = item['correct_problem_count']
break
rate = round(user_correct_problem_count / all_problems_mun * 100, 2)
# 获取题目列表(带搜索、标签和难度过滤)
# 使用annotate预计算统计信息,提高性能
problems_query = Problem.objects.annotate(
submission_count=Count('submission'),
correct_user_count=Count('submission__user', distinct=True, filter=Q(submission__result=True))
).all()
# 应用搜索过滤
if search_query:
problems_query = problems_query.filter(
Q(title__icontains=search_query) |
Q(description__icontains=search_query) |
Q(difficulty__icontains=search_query)
)
# 应用标签过滤
if tag and tag != 'all':
problems_query = problems_query.filter(tags__name__contains=tag.strip('#'))
# 应用难度过滤
if difficulty and difficulty != 'all':
problems_query = problems_query.filter(difficulty=difficulty)
# 按积分排序
problems_query = problems_query.order_by('score')
# 为每个题目计算用户是否答对和正确率
for problem in problems_query:
problem.user_is_correct = Submission.objects.filter(
problem=problem,
result=True,
user=user
).exists()
# 计算正确率(使用预计算的字段)
if problem.submission_count == 0:
problem.correct_rate = 0
else:
problem.correct_rate = (problem.correct_user_count / problem.submission_count) * 100
# 统计题目的数量
all_problems = len(Problem.objects.all())
# 分页
paginator = Paginator(problems_query, 60) # 60个问题每页
page_number = request.GET.get('page')
page_obj = paginator.get_page(page_number)
# 获取所有标签
tags = Problem.objects.values_list('tags__name', flat=True).distinct()
tag = tag.replace('#', '')
# 打卡之星数据
first_day_of_month = timezone.now().replace(day=1, hour=0, minute=0, second=0, microsecond=0)
top_active_users = (
Submission.objects.filter(
result=True,
submission_time__gte=first_day_of_month,
user__role=0
)
.annotate(day=TruncDate('submission_time')) # 使用正确的TruncDate方法
.values('user', 'day')
.distinct()
.values('user')
.annotate(active_days=Count('day', distinct=True))
.order_by('-active_days')[:5]
)
# 生成结构化数据
active_days_data = []
active_student_names = []
COLORS = [
'#5470c6', '#a90000', '#91cc75', '#fac858', '#ee6666',
'#73c0de', '#3ba272', '#9a60b4', '#ea7ccc', '#ff9f7f'
]
for index, user_stat in enumerate(top_active_users):
user = User.objects.get(id=user_stat['user'])
active_days_data.append({
'value': user_stat['active_days'],
'itemStyle': {
'color': COLORS[index % len(COLORS)],
'borderRadius': [20, 20, 0, 0]
}
})
active_student_names.append(user.username)
# 获取最新发布的5个题目
latest_problems = Problem.objects.all().order_by('-id')[:5]
# 为最新题目添加用户是否答对的标记
for problem in latest_problems:
problem.user_is_correct = Submission.objects.filter(
problem=problem,
result=True,
user=user
).exists()
# 获取最近的5个热点新闻报道
latest_news = [
['王伍豪,叶戴宁,李晗等人拿下Python二级证书', 74, '2025-08-04'],
['张一天HIMCM大赛入选梯队名额,通过论文筛选', 294, '2025-08-04'],
['浩宸同学个人网站上线', 134, '2025-08-04'],
['子涵同学新加坡Div网页设计大赛拿下金奖', 88, '2025-07-20'],
['王伍豪,王嘉旭,叶戴宁等拿下Python一级证书', 43, '2025-06-30']
]
return render(request, 'index.html', {
'top_five_correct': top_five_correct_list,
'top_ten_this_month': top_ten_this_month,
'top_ten_today': top_ten_today,
'current_user_rank': current_user_rank,
'current_user_submissions_count': current_user_correct_count,
'difficulty_correct_counts': difficulty_correct_counts_dict,
'all_problems_mun': all_problems_mun,
'rate': rate,
'all_problems': all_problems,
'Problems': page_obj,
'tags': tags,
'tag': tag,
'user': user,
'active_days': active_days_data,
'active_student_names': active_student_names,
'cent': cent,
'user_correct_problem_count': user_correct_problem_count,
'search_query': search_query,
'latest_problems': latest_problems,
'latest_news': latest_news,
'difficulty': difficulty, # 传递难度筛选参数到模板
})
def get_daily_correct_count(request):
today = datetime.now().date()
count = Submission.objects.filter(
user_id=request.session['user']['id'],
result=True,
submission_time__date=today
).values('problem').distinct().count()
return JsonResponse({'count': count})
# 题目详情页
def problem_detail(request, problem_id):
# 获取特定的题目实例
problem = get_object_or_404(Problem, pk=problem_id)
# 获取该用户是否答对过此题
user = User.objects.get(id=request.session['user']['id'])
submission = Submission.objects.filter(
user=user, problem=problem, result=True
).first()
# 获取所有做对该题目的用户(去重)
correct_users = User.objects.filter(
submission__problem=problem,
submission__result=True
).distinct()
# 统计每个用户的做对次数
user_correct_counts = {}
for correct_user in correct_users:
count = Submission.objects.filter(
user=correct_user,
problem=problem,
result=True
).count()
user_correct_counts[correct_user.id] = count
user = User.objects.get(id=request.session['user']['id'])
cent = user.score
# 详情页面
return render(request, 'detail.html', {'problem': problem, 'submission': submission,'correct_users': correct_users,'user_correct_counts': user_correct_counts,'cent':cent})
# 提交代码
@csrf_exempt
def submit_code(request):
if request.method == 'POST':
# 获取当前用户答题数
user = User.objects.get(id=request.session['user']['id'])
code = request.POST.get('code', '')
id = request.POST.get('id', '')
problem = Problem.objects.get(id=id)
# 获取该问题的测试用例
test_cases = TestCase.objects.filter(problem=problem).all()
test_results = []
test_data = []
# 校验每个测试数据
for case in test_cases:
try:
res = evaluate_python_code(code, case)
except Exception as e:
print('error:', e)
res = False
if not res:
test_data.append({'input': case.input_data, 'output': case.expected_output})
test_results.append(res)
# 根据测试结果设置提交结果
# 检查当前用户是否答对过该题目
user_is_corret = Submission.objects.filter(problem=problem, result=True, user=user).exists()
if not user_is_corret:
# 保存提交记录
submission = Submission(
user=user,
problem=problem, # 假设只有一个问题
code=code,
)
if all(test_results):
submission.result = True
user.score += problem.score
user.save()
messages.success(request, '测试成功')
else:
submission.result = False
messages.success(request, '测试失败')
submission.save()
# test_data 测试信息 result 测试结果
return JsonResponse({'test_data': test_data, 'result': submission.result})
else:
if all(test_results):
result = True
messages.success(request, '测试成功')
else:
result = False
messages.success(request, '测试失败')
return JsonResponse({'test_data': test_data, 'result': result})
return render(request, 'detail.html')
# 公告
def announcement_detail(request, pk):
announcement = get_object_or_404(Announcement, pk=pk)
announcement.view_count = announcement.view_count + 1
announcement.save()
announcement.content = markdown.markdown(announcement.content, extensions=[
'markdown.extensions.extra',
'markdown.extensions.codehilite',
'markdown.extensions.toc',
])
return render(request, 'ann_detail.html', {'announcement': announcement})
# 博客
from django.db.models import Q # 需导入Q
def blog_list(request):
query = request.GET.get('q', '') # 搜索关键字
tag_id = request.GET.get('tag', '') # 标签筛选ID
# 基础查询集
blogs = Blog.objects.all().order_by('-create_time')
# 标签筛选
if tag_id:
blogs = blogs.filter(tags_id=tag_id)
# 搜索筛选
if query:
blogs = blogs.filter(
Q(title__icontains=query) | Q(content__icontains=query)
)
"""
# 分页
paginator = Paginator(blogs, 6) # 每页6篇
page_number = request.GET.get('page')
page_obj = paginator.get_page(page_number)
"""
# 传递所有标签到模板(用于标签云)
all_tags = BTag.objects.all()
# 最新和热门文章
latest_articles = Blog.objects.order_by('-create_time')[:4]
popular_articles = Blog.objects.order_by('-view_count')[:4]
return render(request, 'blog_list.html', {
# 'page_obj': page_obj,
'blogs': blogs,
'latest_articles': latest_articles,
'popular_articles': popular_articles,
'tags': all_tags, # 所有标签
})
# 博客详情
def blog_detail(request, blog_id):
# 获取特定博客文章
blog = get_object_or_404(Blog, id=blog_id)
# 获取相关博客(相同标签,排除当前博客,按创建时间倒序排列,最多取5条)
related_blogs = Blog.objects.filter(tags=blog.tags).exclude(id=blog.id).order_by('-create_time')[:3]
# 将 Markdown 内容转换为 HTML
blog.content = markdown.markdown(blog.content, extensions=[
'markdown.extensions.extra',
'markdown.extensions.codehilite',
'markdown.extensions.toc',
])
# 增加浏览次数
blog.view_count += 1
blog.save()
return render(request, 'blog_detail.html', {
'blog': blog,
'related_blogs': related_blogs
})
from django.utils import timezone
# 考试列表
def exam_list(request):
# 获取当前时间
now = timezone.now()
# 获取搜索关键词
query = request.GET.get('q', '')
# 查询考试列表,支持搜索 并且截止日期还没过
exams = Exam.objects.filter(title__icontains=query, is_open=True, deadline__gt=now).order_by('start_time')
# 分页设置
paginator = Paginator(exams, 6) # 每页显示 6 个考试
page_number = request.GET.get('page')
page_obj = paginator.get_page(page_number)
# 渲染模板,传递上下文
context = {
'page_obj': page_obj,
'request': request, # 传递请求以便在模板中使用
}
return render(request, 'exam_list.html', context)
from django.db import models
# 考试详情
def exam_detail(request, exam_id):
# 获取指定 ID 的考试
exam = get_object_or_404(Exam, id=exam_id)
# 获取该考试的所有题目
questions = exam.questions.all()
# 将分钟转换为秒数
duration_in_seconds = exam.duration * 60
# 按题目类型分类并排序
ordered_questions = questions.order_by(
Case(
When(question_type='选择题', then=1),
When(question_type='填空题', then=2),
When(question_type='判断题', then=3),
When(question_type='编程题', then=4),
output_field=models.IntegerField(),
)
)
# 按题目类型分类
choice_questions = questions.filter(question_type='选择题')
fill_blank_questions = questions.filter(question_type='填空题')
true_false_questions = questions.filter(question_type='判断题')
programming_questions = questions.filter(question_type='编程题')
# 渲染模板,传递上下文
context = {
'exam': exam,
'questions': ordered_questions,
'duration_in_seconds': duration_in_seconds,
'choice_questions': choice_questions,
'fill_blank_questions': fill_blank_questions,
'true_false_questions': true_false_questions,
'programming_questions': programming_questions,
}
return render(request, 'exam_detail.html', context)
# 检查编程题
def check_programming_question(code, id):
# 假设使用 Python 3 编写的 evaluate_python_code() 函数来检查代码
# 获取该问题的测试用例
test_cases = QuesCase.objects.filter(question_id=id).all()
test_results = []
test_data = []
# 校验每个测试数据
for case in test_cases:
try:
res = evaluate_python_code(code, case)
except Exception as e:
print('error:', e)
res = False
if not res:
test_data.append({'input': case.input_data, 'output': case.expected_output})
test_results.append(res)
return test_results
# 提交考试
@csrf_exempt # 视情况添加 CSRF 保护
def submit_exam(request):
if request.method == 'POST':
try:
data = json.loads(request.body) # 解析 JSON 数据
examid = data.pop('examid')
# 获取指定 ID的考试
exam = get_object_or_404(Exam, id=examid)
# 获取该考试的所有题目
questions = exam.questions.all()
# 按题目类型分类并排序
ordered_questions = questions.order_by(
Case(
When(question_type='选择题', then=1),
When(question_type='填空题', then=2),
When(question_type='判断题', then=3),
When(question_type='编程题', then=4),
output_field=models.IntegerField(),
)
)
# 处理答案数据
total_score = 0 # 用于累计总分数
for index, question in enumerate(ordered_questions):
question_id = 'question_' + str(index + 1) # 转换为字符串以便与 data 中的键匹配
if question_id in data:
user_answer = data[question_id]
# 根据题目类型判断答案是否正确,并累加得分
if question.question_type == '选择题' or question.question_type == '填空题':
if user_answer == question.choice_answer: # 假设 choice_answer 存储正确答案
total_score += question.score
elif question.question_type == '判断题':
answer_dict = {'false': False, 'true': True}
user_answer = answer_dict[user_answer]
if user_answer == question.is_true:
total_score += question.score
elif question.question_type == '编程题':
# 假设编程题的答案是存储的 expected_output 字段(简单示例)
tests = check_programming_question(user_answer, question.id)
if all(tests):
total_score += question.score
print(
f"题目 ID: {question_id}, 用户答案: {user_answer},答案:{question.choice_answer}, 累计得分: {total_score}")
# 保存考试成绩
user = User.objects.get(id=request.session['user']['id'])
ExamScore.objects.create(user=user, exam=exam, score=total_score)
return JsonResponse({'status': 'success', 'message': f'答案已提交您的总分{total_score}'})
except Exception as e:
return JsonResponse({'status': 'error', 'message': str(e)}, status=400)
return JsonResponse({'status': 'error', 'message': '无效请求'}, status=400)
def build_tree():
# 获取所有基础知识点,包括它们的id
points_list = Points.objects.all().order_by('id')
# 初始化一个列表来存储树结构
tree = []
# 遍历所有基础知识点
for point in points_list:
# 如果是一级标题(没有父级)
if point.parent is None:
# 创建一个字典来存储一级标题及其子标题
primary = {
'id': point.id,
'title': point.title,
'children': []
}
# 找到所有子标题
for child in point.children.all():
child_dict = {
'id': child.id,
'title': child.title
}
primary['children'].append(child_dict)
# 将一级标题添加到树结构中
tree.append(primary)
return tree
# 基础知识
def point_list(request):
# 构建树状结构
tree = build_tree()
print('tree: %s' % tree)
return render(request, 'point_list.html', {'tree': tree})
# 博客详情
def point_detail(request, blog_id):
# 获取特定博客文章
blog = get_object_or_404(Points, id=blog_id)
# 将 Markdown 内容转换为 HTML
blog.content = markdown.markdown(blog.content, extensions=[
'markdown.extensions.extra',
'markdown.extensions.codehilite',
'markdown.extensions.toc',
])
# 增加浏览次数
blog.view_count += 1
blog.save()
# 获取上一篇和下一篇文章
try:
prev_blog = Points.objects.filter(id__lt=blog.id).order_by('-id').first()
except Points.DoesNotExist:
prev_blog = None
try:
next_blog = Points.objects.filter(id__gt=blog.id).order_by('id').first()
except Points.DoesNotExist:
prev_blog = None
# 准备返回的数据
data = {
'title': blog.title,
'content': blog.content,
'view_count': blog.view_count,
'author': blog.author,
'create_time': blog.create_time.strftime('%Y-%m-%d %H:%M:%S'), # 格式化时间
}
# 如果存在上一篇文章,添加到返回的数据中
if prev_blog:
data['prev_blog'] = {
'id': prev_blog.id,
'title': prev_blog.title,
}
# 如果存在下一篇文章,添加到返回的数据中
if next_blog:
data['next_blog'] = {
'id': next_blog.id,
'title': next_blog.title,
}
return JsonResponse(data)
def score_view(request, examid):
# 创建一个子查询,用于获取每个用户的最高分数和对应的创建时间
max_score_subquery = ExamScore.objects.filter(
exam_id=examid
).order_by('created_at').values('user').annotate(
max_score=Max('score'),
created_at=Max('created_at')
).values('max_score', 'created_at')
# 使用子查询来获取每个用户的最高分数和对应的创建时间
scores = ExamScore.objects.filter(
exam_id=examid,
score=Subquery(max_score_subquery.filter(user=OuterRef('user')).values('max_score')[:1])
).select_related('user', 'exam').order_by('-created_at')
print(scores)
return render(request, 'exam_score.html', {'scores': scores})
# 404页面
def page_not_found(request, exception):
return render(request, '404.html', status=404)
# 万维网
def all_webs(request,typeid=None):
query = request.GET.get('q') # 获取搜索关键字
Webs = ToolWebsite.objects.all().order_by('-created_at')
if query:
# 根据标题和内容搜索
Webs = Webs.filter(name__icontains=query) | Webs.filter(type__name__contains=query)
if typeid and typeid != 'all':
Webs = Webs.filter(type_id=typeid)
# 分页
paginator = Paginator(Webs, 6) # 每页显示 5
page_number = request.GET.get('page') # 获取当前页码
page_obj = paginator.get_page(page_number) # 获取当前页的列表
# 获取网站类型
types = ToolType.objects.all()
return render(request, 'all_webs.html', {
'page_obj': page_obj,
'types': types,
'typeid': typeid,
})
# 1. 完善原有礼物列表视图:传递当前用户积分到前端
def Gifts(request, typeid=None):
query = request.GET.get('q')
gifts = Gift.objects.all().order_by('-created_at')
if query:
gifts = gifts.filter(name__icontains=query) | gifts.filter(description__contains=query)
if typeid and typeid != 'all':
gifts = gifts.filter(type_id=typeid)
types = GiftType.objects.annotate(gift_count=Count('Webtype'))
total_count = Gift.objects.count()
# 新增:获取当前登录用户的积分(未登录则为0)
user_score = 0
if request.session.get('user'):
# 从数据库获取最新用户数据(避免session缓存旧积分)
try:
user = User.objects.get(id=request.session['user']['id'])
user_score = user.score
# 更新session中的积分(保持同步)
request.session['user']['score'] = user_score
except User.DoesNotExist:
user_score = 0
return render(request, 'gifts.html', {
'gifts': gifts,
'types': types,
'typeid': typeid,
'total_count': total_count,
'user_score': user_score, # 传递积分到前端
})
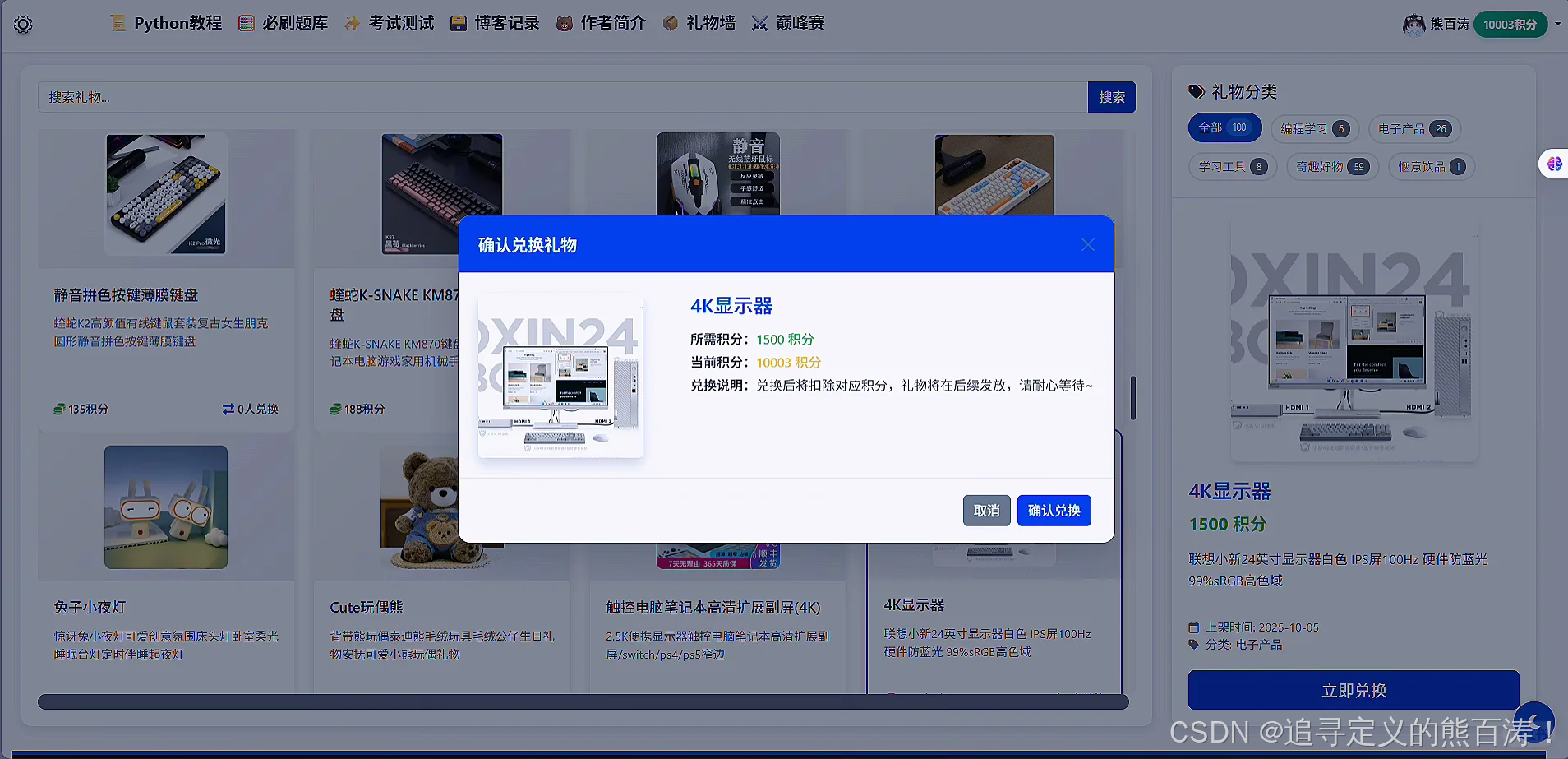
# 2. 新增:礼物兑换接口(处理AJAX请求)
def exchange_gift(request):
# 仅接受POST请求
if request.method != 'POST':
return JsonResponse({'status': 'error', 'msg': '请通过正确方式请求'})
# 1. 验证用户是否登录
if not request.session.get('user'):
return JsonResponse({'status': 'error', 'msg': '请先登录再兑换礼物!'})
# 2. 获取请求参数(礼物ID)
gift_id = request.POST.get('gift_id')
if not gift_id:
return JsonResponse({'status': 'error', 'msg': '请选择要兑换的礼物!'})
# 3. 验证礼物和用户是否存在
try:
gift = Gift.objects.get(id=gift_id)
user = User.objects.get(id=request.session['user']['id'])
except (Gift.DoesNotExist, User.DoesNotExist):
return JsonResponse({'status': 'error', 'msg': '礼物或用户不存在!'})
# 4. 验证积分是否足够
if user.score < gift.required_points:
return JsonResponse({
'status': 'error',
'msg': f'积分不足!当前积分:{user.score},所需积分:{gift.required_points}'
})
# 5. 验证是否已兑换过该礼物(避免重复兑换,可根据需求删除)
'''if GiftExchange.objects.filter(user=user, gift=gift).exists():
return JsonResponse({'status': 'error', 'msg': '您已兑换过该礼物,无需重复兑换!'})
'''
# 6. 执行兑换逻辑
try:
# 扣减用户积分
user.score -= gift.required_points
user.save()
# 创建兑换记录(默认未发放)
GiftExchange.objects.create(
user=user,
gift=gift,
is_issued=False # 初始状态:未发放
)
# 更新session中的用户积分(实时同步)
request.session['user']['score'] = user.score
return JsonResponse({
'status': 'success',
'msg': f'兑换成功!已扣除{gift.required_points}积分,剩余积分:{user.score}',
'remaining_score': user.score # 返回剩余积分
})
except Exception as e:
return JsonResponse({'status': 'error', 'msg': f'兑换失败:{str(e)}'})
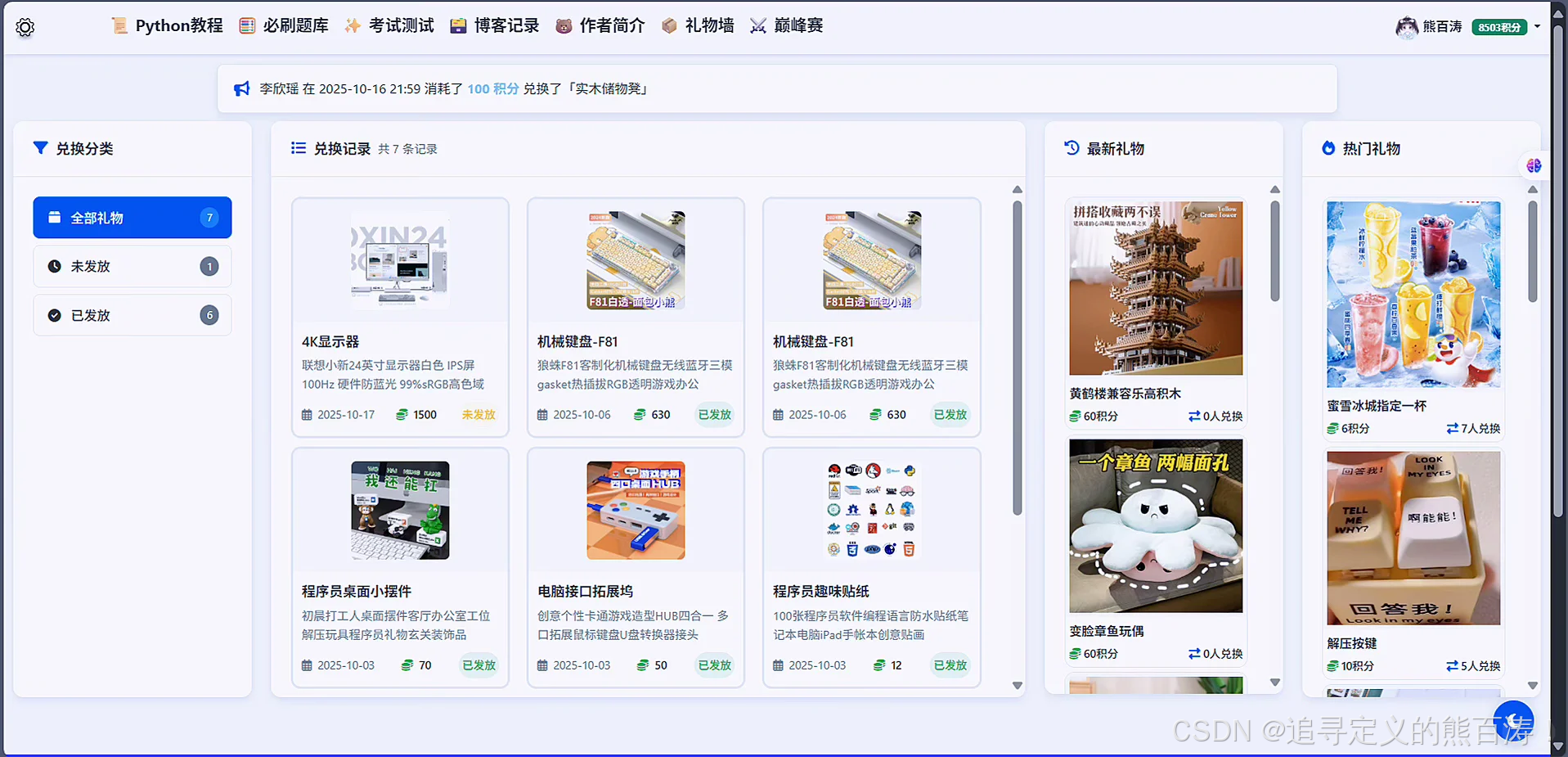
# 显示用户的兑换记录
def my_exchanges(request):
# 验证用户是否登录
if not request.session.get('user'):
messages.error(request, '请先登录查看兑换记录')
return redirect('/login/')
try:
user = User.objects.get(id=request.session['user']['id'])
# 1. 我的兑换记录
exchanges = GiftExchange.objects.filter(user=user).order_by('-exchange_time')
total_count = exchanges.count()
unissued_count = exchanges.filter(is_issued=False).count()
issued_count = exchanges.filter(is_issued=True).count()
# 2. 推荐礼物
latest_gifts = Gift.objects.all().order_by('-created_at')[:10] # 最多10个
popular_gifts = Gift.objects.annotate(
exchange_count=Count('exchanges')
).order_by('-exchange_count')[:10]
# 3. 广播数据(所有用户的最新兑换记录,取100条)
broadcast_records = GiftExchange.objects.select_related('user', 'gift').order_by('-exchange_time')[:100]
# 格式化为JSON可解析的列表
broadcast_json = [
{
'username': rec.user.username,
'time': rec.exchange_time.strftime('%Y-%m-%d %H:%M'),
'points': rec.gift.required_points,
'gift_name': rec.gift.name
}
for rec in broadcast_records
]
return render(request, 'my_exchanges.html', {
'exchanges': exchanges,
'user': user,
'total_count': total_count,
'unissued_count': unissued_count,
'issued_count': issued_count,
'latest_gifts': latest_gifts,
'popular_gifts': popular_gifts,
'broadcast_records': json.dumps(broadcast_json) # 传递广播数据
})
except User.DoesNotExist:
messages.error(request, '用户不存在')
return redirect('/login/')
except Exception as e:
messages.error(request, f'获取数据失败: {str(e)}')
return redirect('/')
# 礼物详情
def gift_detail(request, gift_id):
gift = get_object_or_404(Gift, id=gift_id)
return render(request, 'gift_detail.html', {'gift': gift})
import json
from django.db.models import Count, Q
from django.core.paginator import Paginator
from django.utils import timezone
from .models import PeakSeason, PeakComment
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
import os
from django.core.files.storage import FileSystemStorage
from django.conf import settings
@csrf_exempt
def upload_image(request):
"""上传图片接口"""
if request.method == 'POST' and request.FILES.get('image'):
image = request.FILES['image']
# 验证文件类型
allowed_types = ['image/jpeg', 'image/png', 'image/gif', 'image/webp']
if image.content_type not in allowed_types:
return JsonResponse({'success': False, 'message': '不支持的文件类型'})
# 验证文件大小 (5MB)
if image.size > 5 * 1024 * 1024:
return JsonResponse({'success': False, 'message': '文件大小不能超过5MB'})
# 生成唯一文件名
file_ext = os.path.splitext(image.name)[1]
unique_filename = f"{uuid.uuid4()}{file_ext}"
# 保存文件
fs = FileSystemStorage(location=os.path.join(settings.MEDIA_ROOT, 'peak_images'))
filename = fs.save(unique_filename, image)
file_url = f"{settings.MEDIA_URL}peak_images/{filename}"
return JsonResponse({
'success': True,
'url': file_url,
'message': '上传成功'
})
return JsonResponse({'success': False, 'message': '上传失败'})
def peak_season_list(request):
"""巅峰赛列表页"""
# 获取所有赛季,按照置顶和时间排序
seasons = PeakSeason.objects.filter(is_active=True).order_by('-is_top', '-created_at')
# 获取当前赛季
current_season = None
now = timezone.now()
for season in seasons:
if season.start_time <= now <= season.end_time:
current_season = season
break
# 如果没有当前赛季,显示最新的赛季
if not current_season and seasons:
current_season = seasons[0]
# 获取赛季详情和评论
season_detail = None
comments = None
if current_season:
season_detail = current_season
# 增加浏览量
season_detail.increase_views()
# 获取顶级评论(非回复评论)
comments = PeakComment.objects.filter(
season=current_season,
parent__isnull=True,
is_active=True
).select_related('user').prefetch_related('replies').order_by('-created_at')
# 分页
paginator = Paginator(seasons, 10)
page_number = request.GET.get('page')
page_obj = paginator.get_page(page_number)
context = {
'seasons': page_obj,
'current_season': season_detail,
'comments': comments,
'user': request.session.get('user')
}
return render(request, 'peak_season_list.html', context)
@csrf_exempt
def peak_season_detail(request, season_id):
"""巅峰赛详情页(AJAX接口)"""
if request.method == 'GET':
try:
season = PeakSeason.objects.get(id=season_id, is_active=True)
# 获取顶级评论(非回复评论)
comments = PeakComment.objects.filter(
season=season,
parent__isnull=True,
is_active=True
).select_related('user').prefetch_related('replies').order_by('-created_at')
# 序列化评论数据
comments_data = []
for comment in comments:
comment_data = {
'id': comment.id,
'user': {
'username': comment.user.username,
'avatar': comment.user.avatar.url if comment.user.avatar else '/static/default_avatar.jpg'
},
'content': comment.content,
'created_at': comment.created_at.strftime('%Y-%m-%d %H:%M'),
'likes': comment.likes,
'replies': []
}
# 获取回复
for reply in comment.get_replies():
reply_data = {
'id': reply.id,
'user': {
'username': reply.user.username,
'avatar': reply.user.avatar.url if reply.user.avatar else '/static/default_avatar.jpg'
},
'content': reply.content,
'created_at': reply.created_at.strftime('%Y-%m-%d %H:%M'),
'likes': reply.likes,
'parent_user': comment.user.username
}
comment_data['replies'].append(reply_data)
comments_data.append(comment_data)
data = {
'status': 'success',
'season': {
'id': season.id,
'name': season.name,
'description': season.description,
'content': season.content, # 保持原始 Markdown 内容
'start_time': season.start_time.strftime('%Y-%m-%d %H:%M'),
'end_time': season.end_time.strftime('%Y-%m-%d %H:%M'),
'status': season.get_status_display(),
},
'comments': comments_data
}
return JsonResponse(data)
except PeakSeason.DoesNotExist:
return JsonResponse({'status': 'error', 'message': '赛季不存在'}, status=404)
except Exception as e:
return JsonResponse({'status': 'error', 'message': str(e)}, status=500)
@csrf_exempt
def add_peak_comment(request):
"""添加评论"""
if request.method == 'POST':
if not request.session.get('user'):
return JsonResponse({'status': 'error', 'message': '请先登录'})
try:
data = json.loads(request.body)
season_id = data.get('season_id')
content = data.get('content', '').strip()
parent_id = data.get('parent_id')
if not content:
return JsonResponse({'status': 'error', 'message': '评论内容不能为空'})
# 增加内容长度限制
if len(content) > 5000:
return JsonResponse({'status': 'error', 'message': '评论内容过长'})
season = PeakSeason.objects.get(id=season_id, is_active=True)
user = User.objects.get(id=request.session['user']['id'])
parent_comment = None
if parent_id:
try:
parent_comment = PeakComment.objects.get(id=parent_id, season=season)
except PeakComment.DoesNotExist:
return JsonResponse({'status': 'error', 'message': '父评论不存在'})
# 创建评论,内容直接存储 Markdown 格式
comment = PeakComment.objects.create(
season=season,
user=user,
content=content, # 存储原始 Markdown 内容
parent=parent_comment
)
# 返回新评论数据
comment_data = {
'id': comment.id,
'user': {
'username': user.username,
'avatar': user.avatar.url if user.avatar else '/static/default_avatar.jpg'
},
'content': content, # 返回原始内容,前端会渲染
'created_at': comment.created_at.strftime('%Y-%m-%d %H:%M'),
'likes': 0,
'replies': []
}
if parent_comment:
comment_data['parent_user'] = parent_comment.user.username
return JsonResponse({
'status': 'success',
'message': '评论成功',
'comment': comment_data,
'is_reply': parent_comment is not None
})
except PeakSeason.DoesNotExist:
return JsonResponse({'status': 'error', 'message': '赛季不存在'})
except Exception as e:
return JsonResponse({'status': 'error', 'message': f'评论失败: {str(e)}'})
@csrf_exempt
def like_peak_comment(request):
"""点赞评论"""
if request.method == 'POST':
if not request.session.get('user'):
return JsonResponse({'status': 'error', 'message': '请先登录'})
try:
data = json.loads(request.body)
comment_id = data.get('comment_id')
comment = PeakComment.objects.get(id=comment_id, is_active=True)
comment.likes += 1
comment.save()
return JsonResponse({'status': 'success', 'likes': comment.likes})
except PeakComment.DoesNotExist:
return JsonResponse({'status': 'error', 'message': '评论不存在'})
except Exception as e:
return JsonResponse({'status': 'error', 'message': f'点赞失败: {str(e)}'})
2.2.2 后端代码核心讲解
我由于项目比较大,我这里只分析重点四个模块:教程模块、必刷题库模块、礼物兑换模块和巅峰赛模块。注意:代码中可能包含其他模块,但我核心分析关注这四个。
-
教程模块:对应的是基础知识(Points)和博客(Blog)部分。
-
必刷题库模块:对应的是题目(Problem)和提交记录(Submission)部分。
-
礼物兑换模块:对应的是礼物(Gift)和兑换记录(GiftExchange)部分。
-
巅峰赛模块:对应的是巅峰赛季(PeakSeason)和评论(PeakComment)部分
1. 教程模块 - 结构化知识体系
设计理念:构建渐进式学习路径,将碎片化知识组织成树形结构,模拟教材的章节目录,让学习者有清晰的进阶路径。
核心功能实现:
树形知识结构构建
def build_tree():
points_list = Points.objects.all().order_by('id')
tree = []
for point in points_list:
if point.parent is None: # 识别一级节点
primary = {
'id': point.id,
'title': point.title,
'children': [] # 准备存放子节点
}
# 查找并添加所有子节点
for child in point.children.all():
child_dict = {
'id': child.id,
'title': child.title
}
primary['children'].append(child_dict)
tree.append(primary)
return tree
技术实现解析:
-
自关联模型:通过
parent字段实现无限层级 -
前端友好格式:生成JSON树状数据便于前端渲染
-
顺序控制:按ID排序确保内容稳定性
Markdown内容渲染系
def point_detail(request, blog_id):
blog = get_object_or_404(Points, id=blog_id)
# 安全的内容转换
blog.content = markdown.markdown(blog.content, extensions=[
'markdown.extensions.extra', # 支持表格、定义列表等
'markdown.extensions.codehilite', # 代码语法高亮
'markdown.extensions.toc', # 自动生成目录导航
])
用户体验优化:
-
学习进度追踪:上一篇/下一篇导航
-
阅读统计:
view_count记录知识点热度 -
响应式设计:JSON API支持前后端分离
数据流分析:
数据库Points表 → 构建树形结构 → 前端目录渲染 → 用户点击 → 加载内容 → Markdown转换 → HTML显示
2. 必刷题库模块 - 多维学习激励系统
设计理念:数据驱动的个性化学习 不仅仅是题目仓库,而是包含竞争、反馈、进度追踪的完整练习生态系统。
核心功能体系:
2.1 智能排名竞争机制
总排名 - 长期成就展示
user_rankings = (
Submission.objects.filter(result=True, user__role=0)
.values('user', 'problem') # 按用户+题目分组
.distinct() # 关键:去重,避免刷题
.values('user') # 按用户聚合
.annotate(correct_problem_count=Count('problem', distinct=True))
.order_by('-correct_problem_count') # 降序排列
)
设计意义:鼓励真正掌握知识点,而非重复提交
月排名 - 持续活跃激励
first_day_of_month = timezone.now().replace(day=1, hour=0, minute=0, second=0, microsecond=0)
top_five_correct_this_month = (
Submission.objects.filter(
result=True,
user__role=0,
submission_time__gte=first_day_of_month # 时间范围筛选
)
# ... 同样的去重统计逻辑
)
商业价值:防止老用户垄断榜单,给新用户上升机会
当日排名 - 实时竞争氛围
today = datetime.now().date() # 获取当天日期
top_five_correct_today = (
Submission.objects.filter(result=True, submission_time__date=today)
# ... 统计逻辑
)
用户心理:制造"每日都有新机会"的紧迫感
2.2 题目智能分析系统
全局题目统计
problems_query = Problem.objects.annotate(
submission_count=Count('submission'), # 总提交次数
correct_user_count=Count('submission__user', distinct=True,
filter=Q(submission__result=True)) # 做对人数
).all()
# 计算正确率
for problem in problems_query:
if problem.submission_count > 0:
problem.correct_rate = (problem.correct_user_count / problem.submission_count) * 100
else:
problem.correct_rate = 0
个性化学习状态
# 标记用户是否已掌握该题目
for problem in problems_query:
problem.user_is_correct = Submission.objects.filter(
problem=problem, result=True, user=user
).exists()
2.3 个人学习分析面板
难度分布分析
# 统计用户在各难度级别的掌握情况
difficulty_correct_counts = Submission.objects.filter(
user=user, result=True
).values('problem_id', 'problem__difficulty').distinct()
difficulty_correct_counts_dict = {'简单': 0, '中等': 0, '困难': 0}
for item in difficulty_correct_counts:
difficulty = item['problem__difficulty']
difficulty_correct_counts_dict[difficulty] += 1
学习进度可视化
# 总体进度计算
all_problems_mun = len(Problem.objects.all())
user_correct_problem_count = 0
for item in user_all_rankings:
if item['user'] == current_user_id:
user_correct_problem_count = item['correct_problem_count']
break
rate = round(user_correct_problem_count / all_problems_mun * 100, 2)
2.4 代码评测引擎
安全代码执行
@csrf_exempt
def submit_code(request):
code = request.POST.get('code', '')
problem = Problem.objects.get(id=id)
test_cases = TestCase.objects.filter(problem=problem).all()
test_results = []
for case in test_cases:
try:
# 在安全环境中执行用户代码
res = evaluate_python_code(code, case)
except Exception as e:
res = False # 运行异常视为失败
test_results.append(res)
# 首次答对奖励积分
user_is_corret = Submission.objects.filter(
problem=problem, result=True, user=user).exists()
if not user_is_corret and all(test_results):
user.score += problem.score
user.save()
技术亮点:
-
性能优化:使用
annotate在数据库层面完成统计 -
去重逻辑:确保排名公平性
-
实时更新:积分和排名即时反馈
-
多维筛选:支持标签、难度、关键词搜索
3. 礼物兑换模块 - 积分激励经济系统
设计理念:构建虚拟经济循环,通过积分奖励机制将学习成果转化为 tangible 回报,形成学习正反馈。
核心兑换流程:安全兑换验证系统
def exchange_gift(request):
# 1. 身份验证层
if not request.session.get('user'):
return JsonResponse({'status': 'error', 'msg': '请先登录!'})
# 2. 数据验证层
try:
gift = Gift.objects.get(id=gift_id)
user = User.objects.get(id=request.session['user']['id'])
except:
return JsonResponse({'status': 'error', 'msg': '礼物或用户不存在!'})
# 3. 业务规则层
if user.score < gift.required_points:
return JsonResponse({'status': 'error', 'msg': f'积分不足!当前:{user.score},需要:{gift.required_points}'})
# 4. 交易执行层
user.score -= gift.required_points # 扣减积分
user.save()
# 5. 记录创建层
GiftExchange.objects.create(
user=user,
gift=gift,
is_issued=False # 待发放状态
)
# 6. 状态同步层
request.session['user']['score'] = user.score
实时社交广播系统
def my_exchanges(request):
# 获取最近兑换记录用于社区展示
broadcast_records = GiftExchange.objects.select_related('user', 'gift')[:100]
broadcast_json = [
{
'username': rec.user.username,
'time': rec.exchange_time.strftime('%Y-%m-%d %H:%M'),
'points': rec.gift.required_points,
'gift_name': rec.gift.name
}
for rec in broadcast_records
]
个人中心数据聚合
def my_exchanges(request):
user = User.objects.get(id=request.session['user']['id'])
exchanges = GiftExchange.objects.filter(user=user).order_by('-exchange_time')
# 多维统计
total_count = exchanges.count()
unissued_count = exchanges.filter(is_issued=False).count()
issued_count = exchanges.filter(is_issued=True).count()
# 智能推荐
latest_gifts = Gift.objects.all().order_by('-created_at')[:10]
popular_gifts = Gift.objects.annotate(
exchange_count=Count('exchanges')
).order_by('-exchange_count')[:10]
经济系统设计:
-
积分获取:通过刷题获得,难度越高积分越多
-
积分消耗:兑换实物/虚拟礼物
-
状态管理:待发放/已发放的工作流
-
社交影响:广播系统增强兑换欲望
4. 巅峰赛模块 - 竞技社区生态系统
设计理念:游戏化学习体验,将竞赛元素融入学习过程,通过赛季制、评论互动营造社区氛围。
核心竞赛系统:
智能赛季状态管理
def peak_season_list(request):
now = timezone.now()
seasons = PeakSeason.objects.filter(is_active=True).order_by('-is_top', '-created_at')
# 自动识别当前赛季
current_season = None
for season in seasons:
if season.start_time <= now <= season.end_time:
current_season = season
break
# 评论系统初始化
comments = PeakComment.objects.filter(
season=current_season,
parent__isnull=True, # 顶级评论
is_active=True
).select_related('user').prefetch_related('replies')
树形评论互动系统
@csrf_exempt
def add_peak_comment(request):
# 安全验证
if not request.session.get('user'):
return JsonResponse({'status': 'error', 'message': '请先登录'})
content = data.get('content', '').strip()
if not content:
return JsonResponse({'status': 'error', 'message': '评论内容不能为空'})
# 内容安全限制
if len(content) > 5000:
return JsonResponse({'status': 'error', 'message': '评论内容过长'})
# 回复逻辑处理
parent_comment = None
if parent_id:
parent_comment = PeakComment.objects.get(id=parent_id, season=season)
# 创建评论(支持Markdown)
comment = PeakComment.objects.create(
season=season,
user=user,
content=content,
parent=parent_comment
)
安全图片上传系统
@csrf_exempt
def upload_image(request):
if request.method == 'POST' and request.FILES.get('image'):
image = request.FILES['image']
# 1. 文件类型白名单验证
allowed_types = ['image/jpeg', 'image/png', 'image/gif', 'image/webp']
if image.content_type not in allowed_types:
return JsonResponse({'success': False, 'message': '不支持的文件类型'})
# 2. 文件大小限制
if image.size > 5 * 1024 * 1024:
return JsonResponse({'success': False, 'message': '文件大小不能超过5MB'})
# 3. 安全文件名生成
unique_filename = f"{uuid.uuid4()}{os.path.splitext(image.name)[1]}"
# 4. 文件存储
fs = FileSystemStorage(location=os.path.join(settings.MEDIA_ROOT, 'peak_images'))
filename = fs.save(unique_filename, image)
社区功能特色:
-
赛季制度:有时间限制的竞赛周期
-
置顶功能:重要内容优先展示
-
点赞互动:增强用户参与感
-
内容安全:多层防护确保社区质量
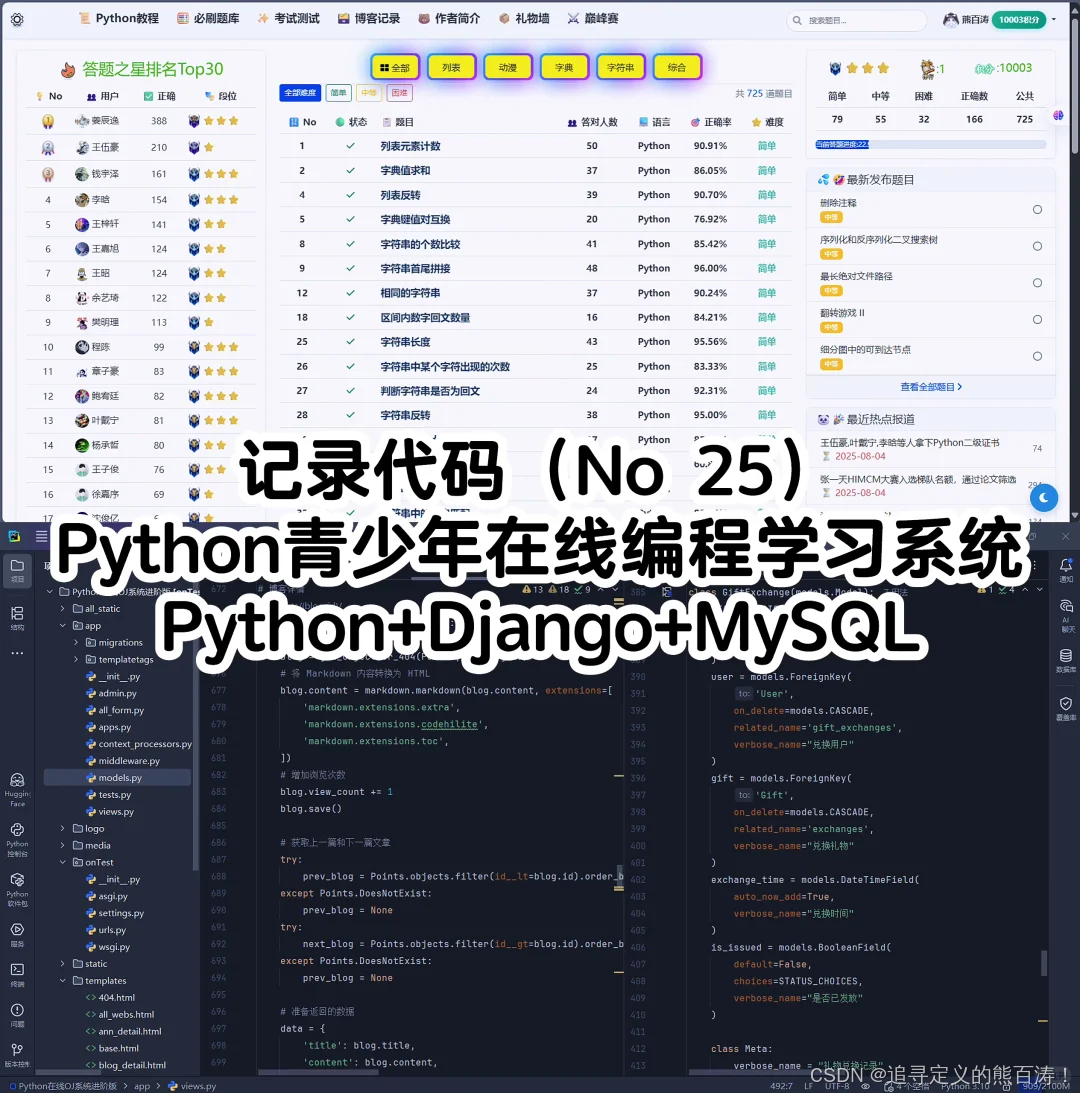
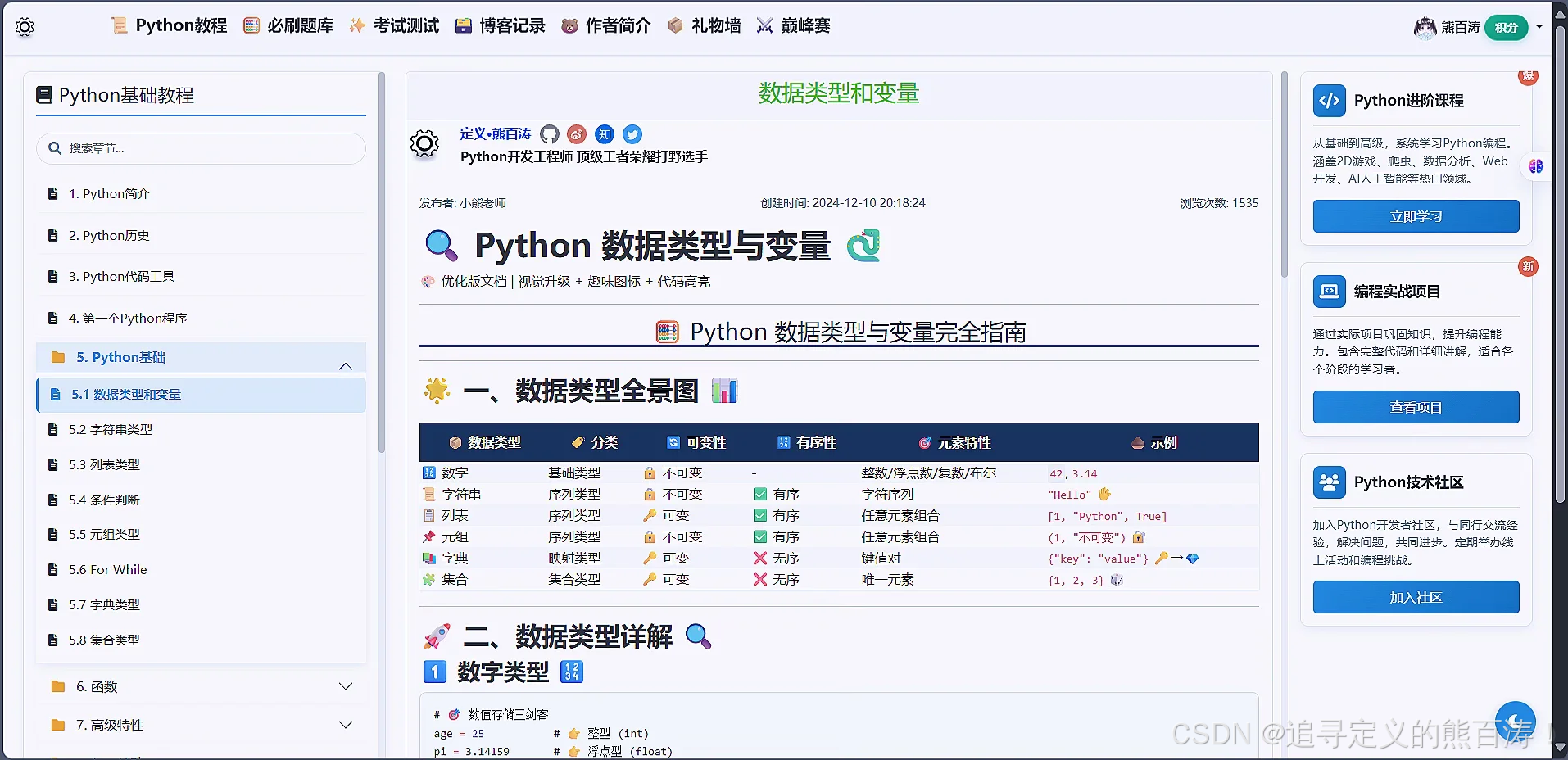
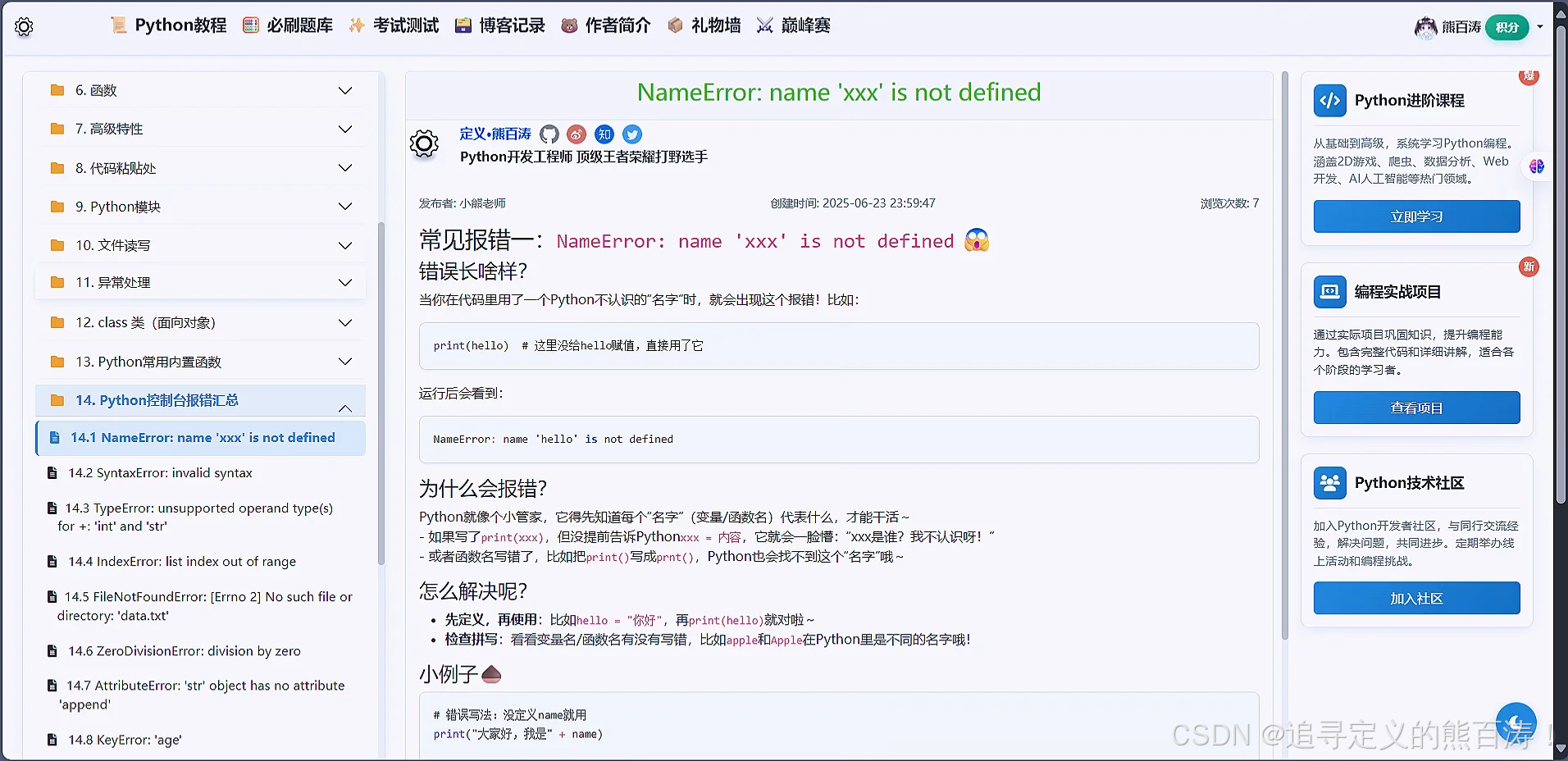
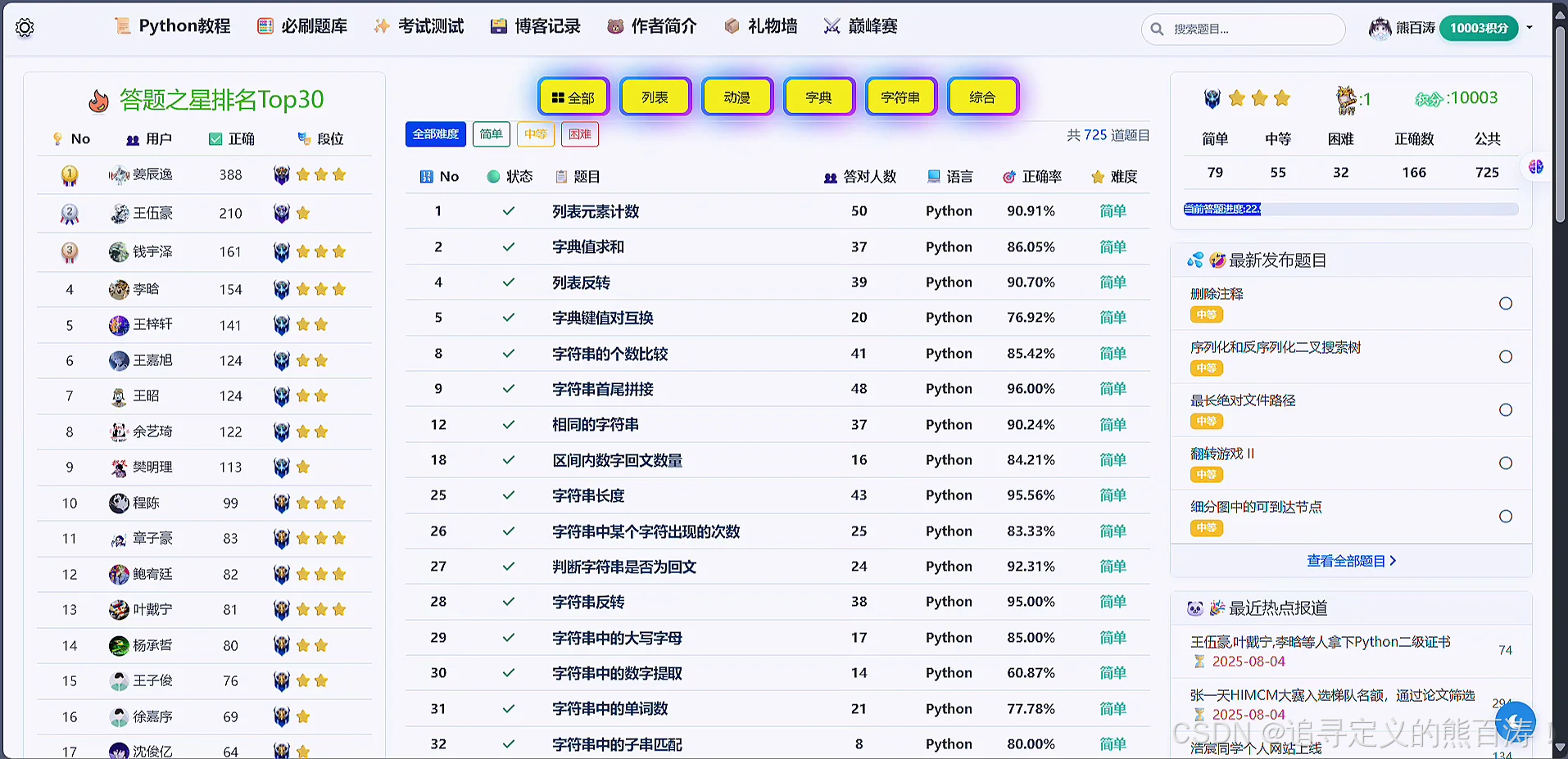
3 项目代码部分截图
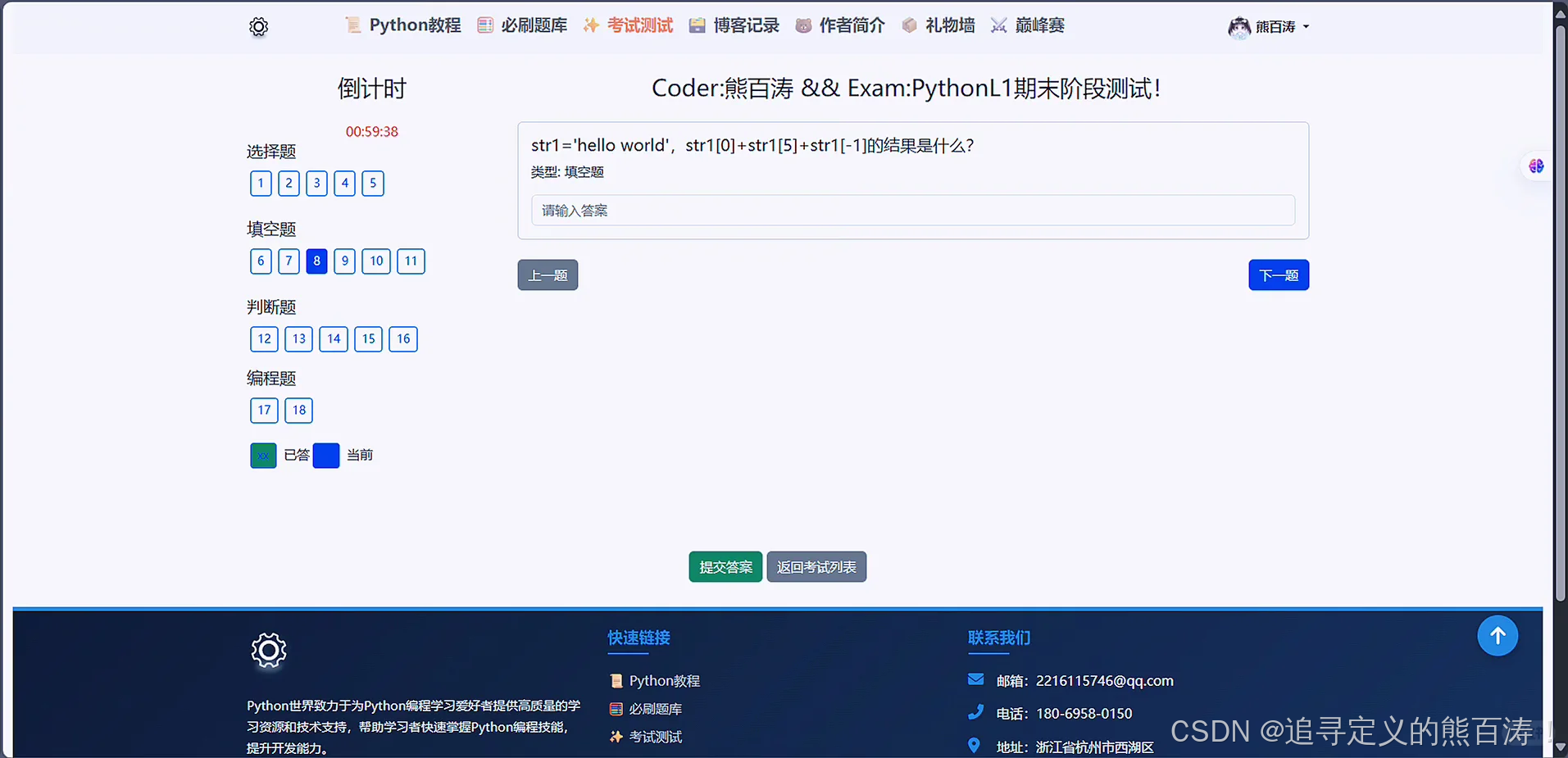
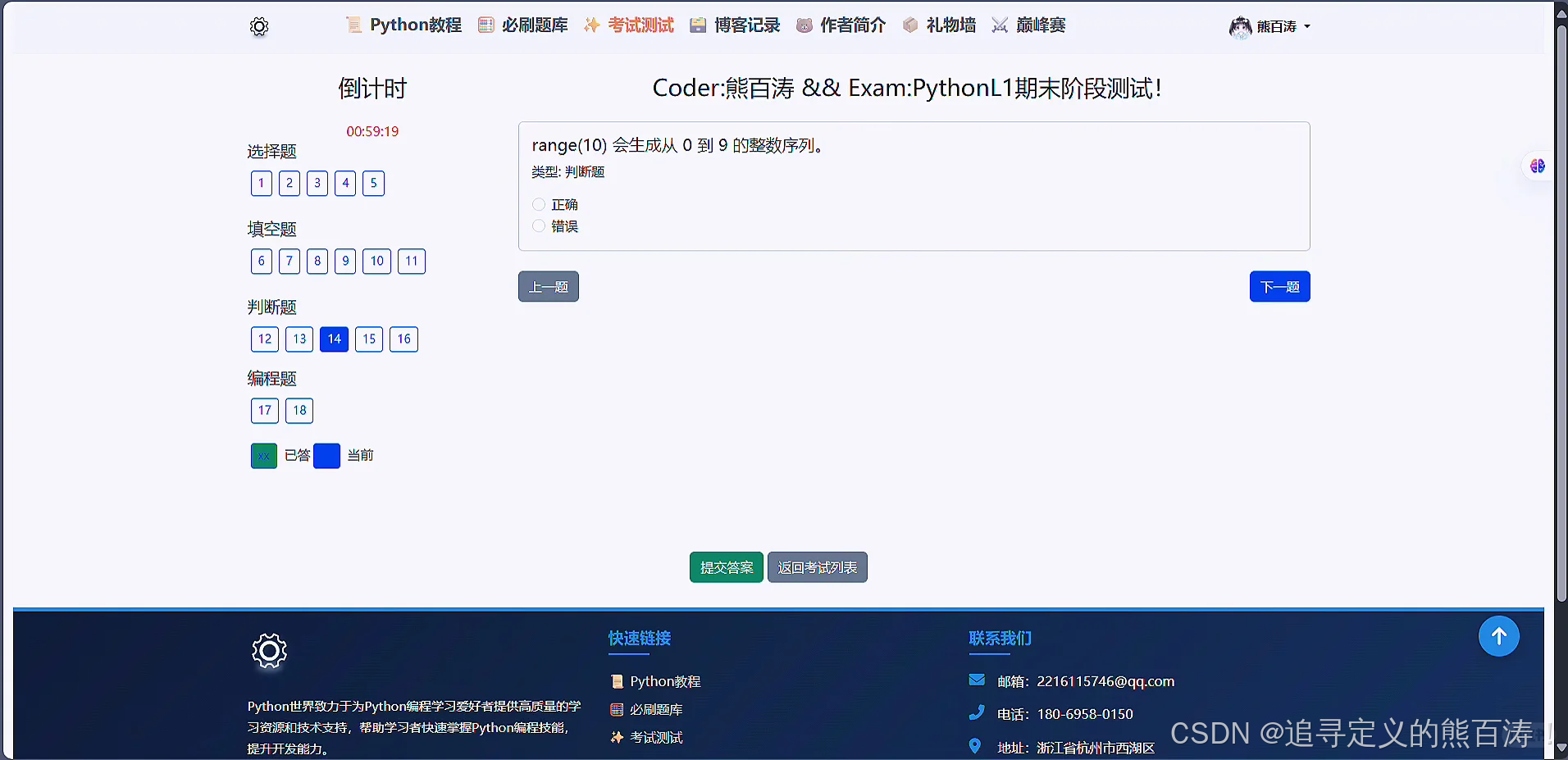
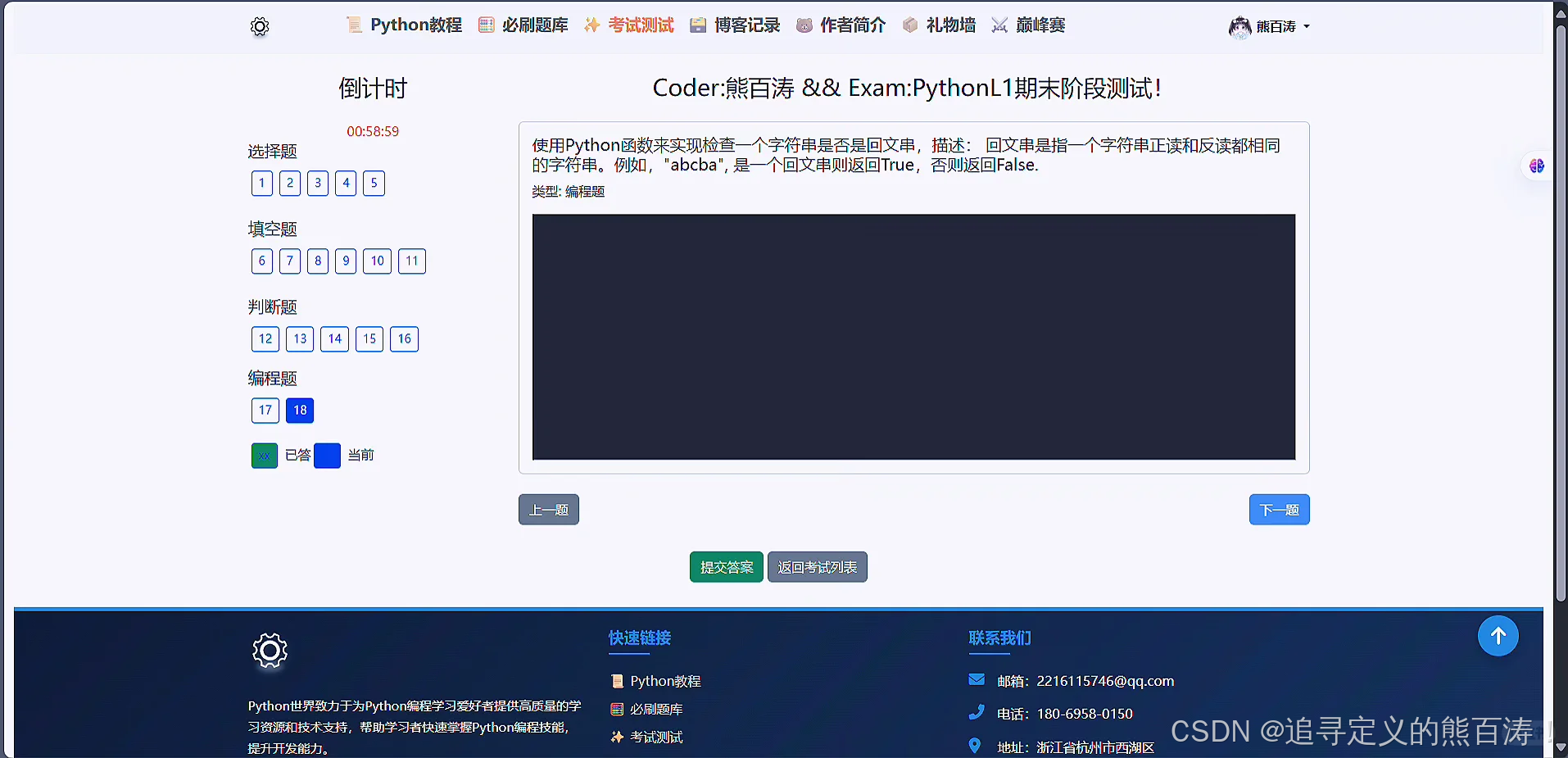

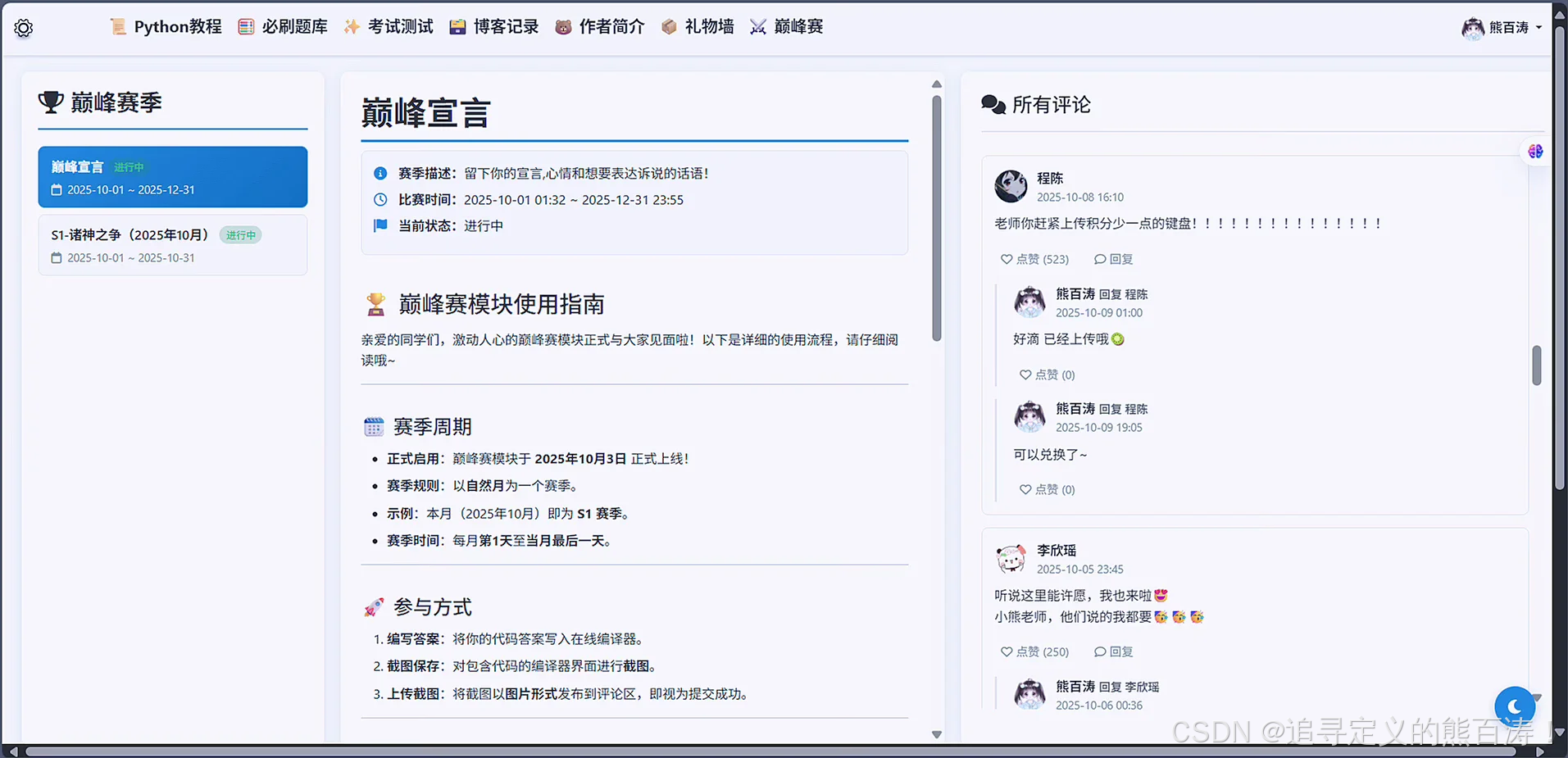
4 最后:
该项目个人感觉写的还不错,基本上涵盖了青少年编程教育技术学习的各个方向,形成了相对完美的闭环,如果对该项目感兴趣的同学可以私信或者和我交流讨论!


















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











