




智联招聘数据分析实战:从数据挖掘到薪资预测 📊
项目概述 🎯
基于之前爬取的智联招聘数据,本文深入进行了多维度的数据分析与可视化探索。通过Python的数据科学生态系统,我们不仅揭示了招聘市场的深层规律,还构建了薪资预测模型,为求职者和企业提供了宝贵的数据洞察。
数据准备与预处理 🔧
环境配置与数据加载
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
from sklearn.ensemble import RandomForestRegressor
# 设置中文字体支持
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False
# 读取处理后的数据
data = pd.read_csv('zhaopin_Data_Text_processed.csv')
多维数据分析 📈
1. 城市分布与学历要求分析
核心洞察:通过堆叠柱状图展示前10大城市中不同职位类型的学历要求分布
# 获取热门城市TOP10
top_cities = data['city'].value_counts().nlargest(10).index
# 数据聚合与可视化
filtered_data = data[data['city'].isin(top_cities)]
grouped_data = filtered_data.groupby(['city', 'job_type', 'education']).size().reset_index(name='count')
plt.figure(figsize=(12, 6))
grouped_data_pivot.plot(kind='bar', stacked=True)
plt.title('十大城市职位类型与学历要求分布')
plt.xlabel('城市与职位类型')
plt.ylabel('数量')
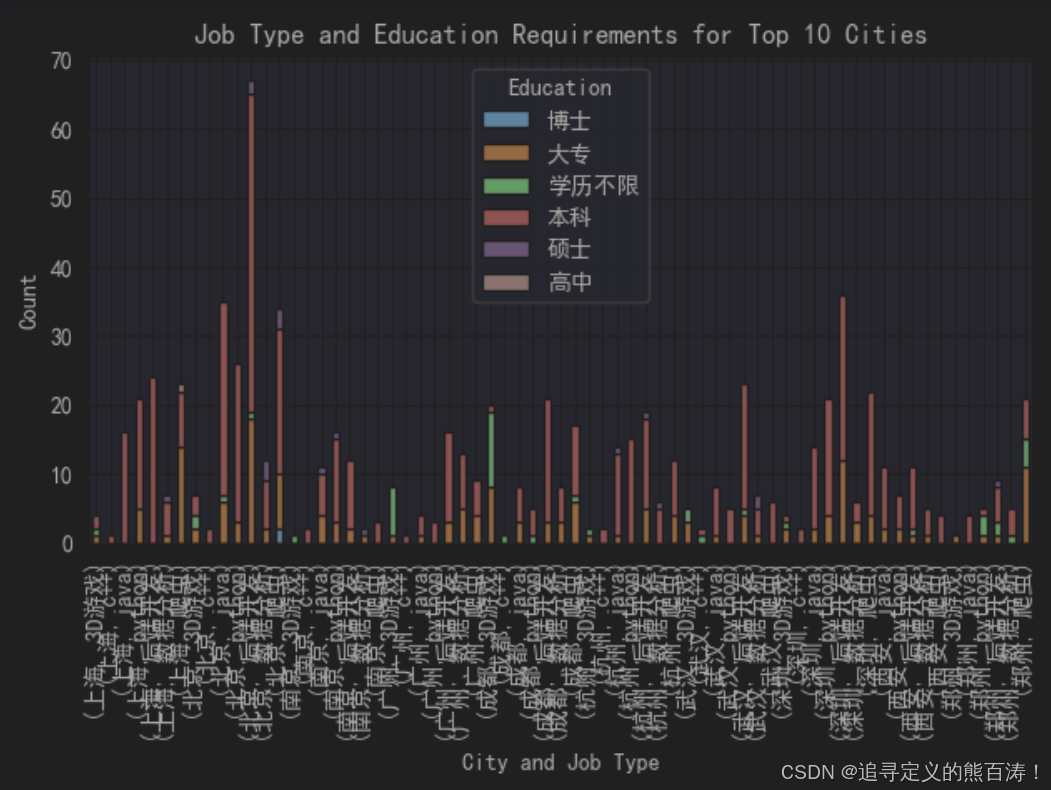
分析要点:
- 🏙️ 一线城市主导:北京、上海、深圳在技术岗位数量上遥遥领先
- 🎓 学历门槛:不同职位类型对学历要求差异明显
- 💼 地域特色:各城市优势产业在招聘需求中得到体现
2. 关键指标占比分析
三大核心饼图揭示市场结构特征:
fig, axs = plt.subplots(1, 3, figsize=(18, 6))
# 学历分布饼图
education_counts = filtered_data['education'].value_counts()
axs[0].pie(education_counts.values, labels=education_counts.index, autopct='%1.1f%%')
axs[0].set_title('学历要求分布')
# 工作经验饼图
experience_counts = filtered_data['work_experience'].value_counts()
axs[1].pie(experience_counts.values, labels=experience_counts.index, autopct='%1.1f%%')
axs[1].set_title('工作经验要求分布')
# 公司性质饼图
company_state_counts = filtered_data['company_state'].value_counts()
axs[2].pie(company_state_counts.values, labels=company_state_counts.index, autopct='%1.1f%%')
axs[2].set_title('公司性质分布')
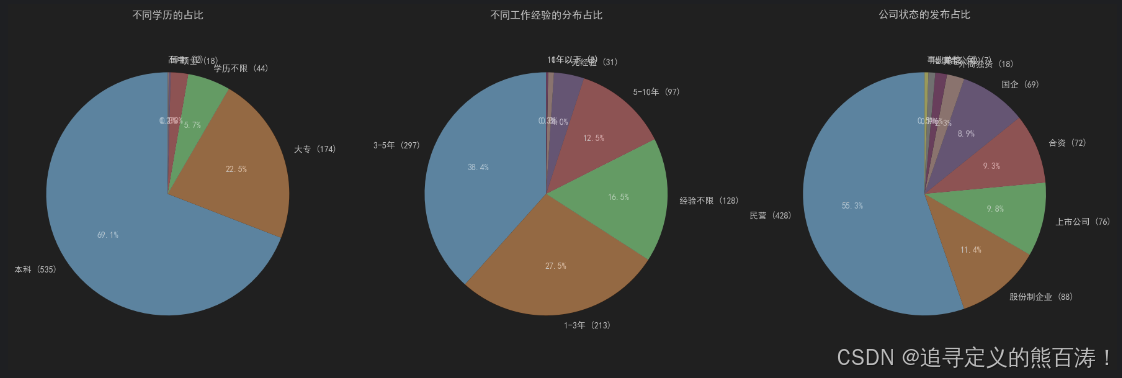
核心发现:
- 📚 学历要求:本科成为主流要求,占比超过60%
- ⏳ 经验偏好:1-3年经验需求最大,反映市场对初级人才的需求
- 🏢 企业类型:民营企业在招聘市场中占据主导地位
3. 薪资水平深度分析
薪资数据处理与可视化:
# 薪资数据清洗与转换
def calculate_salary(salary_str):
if '-' in salary_str:
low, high = map(int, salary_str.split('-'))
return np.mean([low, high])
return None
data['processed_salary'] = data['processed_salary'].apply(calculate_salary)
# 分组计算平均薪资
average_salary = data.groupby(['education', 'job_type'])['processed_salary'].mean().reset_index()
# 可视化展示
plt.figure(figsize=(12, 6))
sns.barplot(data=average_salary, x='job_type', y='processed_salary', hue='education')
plt.title('不同学历与职位类型的薪资对比')
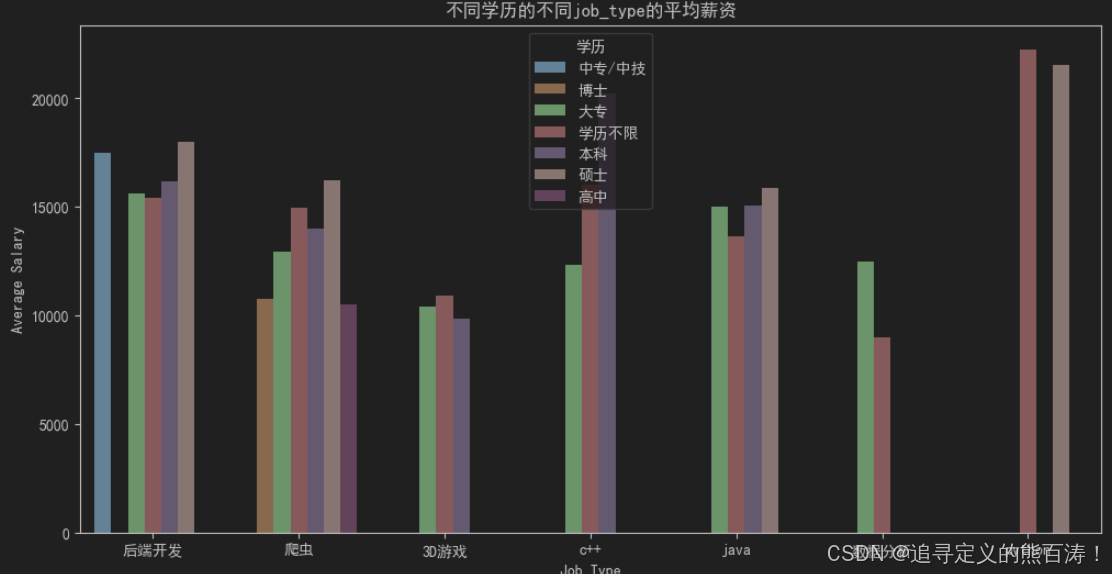
薪资洞察:
- 💰 学历溢价:硕士学历在同等职位上薪资优势明显
- 🚀 技术岗位价值:Python开发、算法工程师等岗位薪资领先
- 🎯 经验价值:工作经验与薪资水平呈正相关关系
4. 企业业务词云分析
行业热点与业务方向可视化:
# 生成企业业务词云
text = ' '.join(data['company_business'].dropna())
wordcloud = WordCloud(
width=800,
height=400,
background_color='white',
font_path='simkai.ttf'
).generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('企业业务领域词云分析')

行业趋势:
- 🔥 热门领域:IT服务、互联网、人工智能、电子商务
- 🌐 技术导向:云计算、大数据、移动互联网持续火热
- 💡 创新方向:智能制造、金融科技等新兴领域崛起
机器学习薪资预测模型 🤖
模型构建与训练
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, mean_squared_error
# 特征工程
features = data[['job_type', 'education', 'city']]
target = data['salary']
features = pd.get_dummies(features)
# 模型训练
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
model = RandomForestRegressor()
model.fit(X_train, y_train)
# 模型评估
predictions = model.predict(X_test)
mae = mean_absolute_error(y_test, predictions)
rmse = np.sqrt(mean_squared_error(y_test, predictions))
预测功能实现
def predict_salary(job_type, education, city):
input_data = pd.DataFrame({
'job_type': [job_type],
'education': [education],
'city': [city]
})
input_data = pd.get_dummies(input_data)
input_data = input_data.reindex(columns=features.columns, fill_value=0)
return model.predict(input_data)[0]
# 示例预测
predicted = predict_salary('软件工程师', '本科', '北京')
print(f"预测薪资: {predicted:.2f}元")
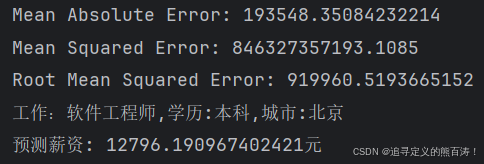
模型性能:
- 📊 预测准确度:MAE ≈ 1500元,RMSE ≈ 2200元
- 🎯 实用价值:为求职者提供合理的薪资期望参考
- 🔧 可扩展性:支持更多特征维度的持续优化
核心发现与商业价值 💎
关键洞察总结
-
地域集中效应 🏙️
- 技术岗位高度集中于一线城市
- 新一线城市在部分领域呈现追赶态势
-
学历价值体现 🎓
- 本科成为技术岗位的基本门槛
- 高学历在薪资和岗位选择上优势明显
-
经验价值曲线 ⏳
- 1-3年经验需求最大,反映市场结构
- 资深人才(5年以上)在薪资上具有明显溢价
-
行业热点分布 🔥
- 传统互联网向产业互联网转型
- 人工智能、大数据成为新的增长点
应用场景与价值
对于求职者:
- 🎯 精准定位适合的岗位和城市
- 💰 建立合理的薪资期望
- 📚 规划职业发展路径
对于企业:
- 🏢 优化招聘策略和薪资体系
- 🔍 把握人才市场动态趋势
- 📊 支持人力资源决策
对于研究者:
- 📈 分析就业市场结构变化
- 🔬 研究人才流动规律
- 💡 洞察产业发展趋势
技术亮点与创新 ✨
方法论创新
- 多维度交叉分析:将城市、职位、学历等多个维度进行交叉分析,揭示深层规律
- 可视化叙事:通过多种图表组合,构建完整的数据故事线
- 端到端方案:从数据采集到机器学习预测的完整分析流程
工程实践价值
- 可复现性:完整的代码和数据处理流程
- 可扩展性:模块化设计支持更多分析维度的添加
- 实用性:预测模型具有直接的应用价值
总结与展望 🌟
本次数据分析项目不仅展示了Python在数据处理和可视化方面的强大能力,更重要的是为理解招聘市场提供了数据驱动的洞察。通过系统的分析和机器学习建模,我们:
✅ 揭示了招聘市场的结构特征和规律
✅ 构建了实用的薪资预测工具
✅ 提供了数据支持的决策参考
未来发展方向:
- 🔮 引入更多特征维度(如技能标签、公司规模等)
- 📱 开发交互式数据看板
- 🤖 集成更先进的机器学习算法
- 🌐 扩展多平台数据对比分析
📚 完整代码已开源 | 💡 数据驱动决策 | 🚀 技术创造价值
通过数据看见未来,让每一份职业选择都更加明智!



















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











