




 本文介绍了GAM-Attention注意力机制,一种超越CBAM的机制,旨在提高目标检测精度。虽然实际效果依赖于具体任务,但可以在YOLOv8模型上尝试增加GAM以提升性能。通过在通道和空间注意力上增强跨维度信息交互,GAM在分类任务上表现出色。文章详细说明了如何将GAM集成到YOLOv8模型的代码实现中,并提供了训练参数设置的指导。注意在集成过程中可能出现的报错及解决办法。
本文介绍了GAM-Attention注意力机制,一种超越CBAM的机制,旨在提高目标检测精度。虽然实际效果依赖于具体任务,但可以在YOLOv8模型上尝试增加GAM以提升性能。通过在通道和空间注意力上增强跨维度信息交互,GAM在分类任务上表现出色。文章详细说明了如何将GAM集成到YOLOv8模型的代码实现中,并提供了训练参数设置的指导。注意在集成过程中可能出现的报错及解决办法。
一、GAM-Attention注意力机制简介
GAM全称:Global Attention Mechanism。它被推出的时候有一个响亮的口号叫做:超越CBAM,不计成本地提高精度。由此可见,它的主要作用是为了目标检测精度的提高。
但是,大家都明白,具体效果怎么样,还得看具体的任务,我浅浅地试了一下,这个注意力机制在小目标检测任务中表现还是可以的,如果你有这方面的需求,可以尝试一下增加GAM注意力机制。
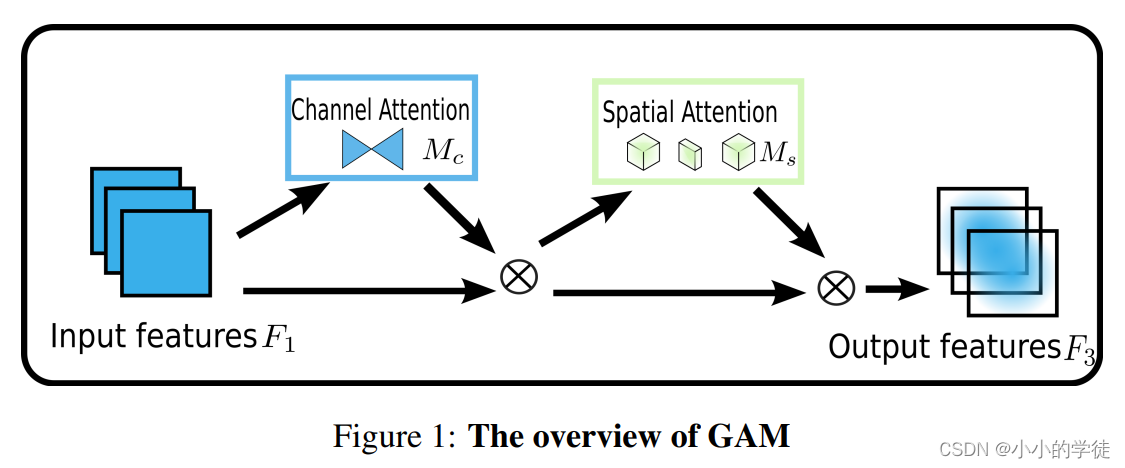
上一篇文章中说,通道注意力与空间注意力被广泛地应用在视觉任务中,CBAM注意力机制就是融合了两者。无独有偶,GAM注意力机制也采用了通道注意力+空间注意力的框架。不同的是,GAM注意力机制的作者提出了一种全局吸引机制,这种机制是通过在减少信息约简的同时放大全局交互表示来提高深度神经网络的性能。
因为作者认为以往的注意力方法都忽略了通道与空间的相互作用,丢失了跨维信息。考虑到跨维度信息的重要性,并放大跨维度的交互作用,GAM就应运而生。
GAM注意力机制的模型结构图如下图所示:
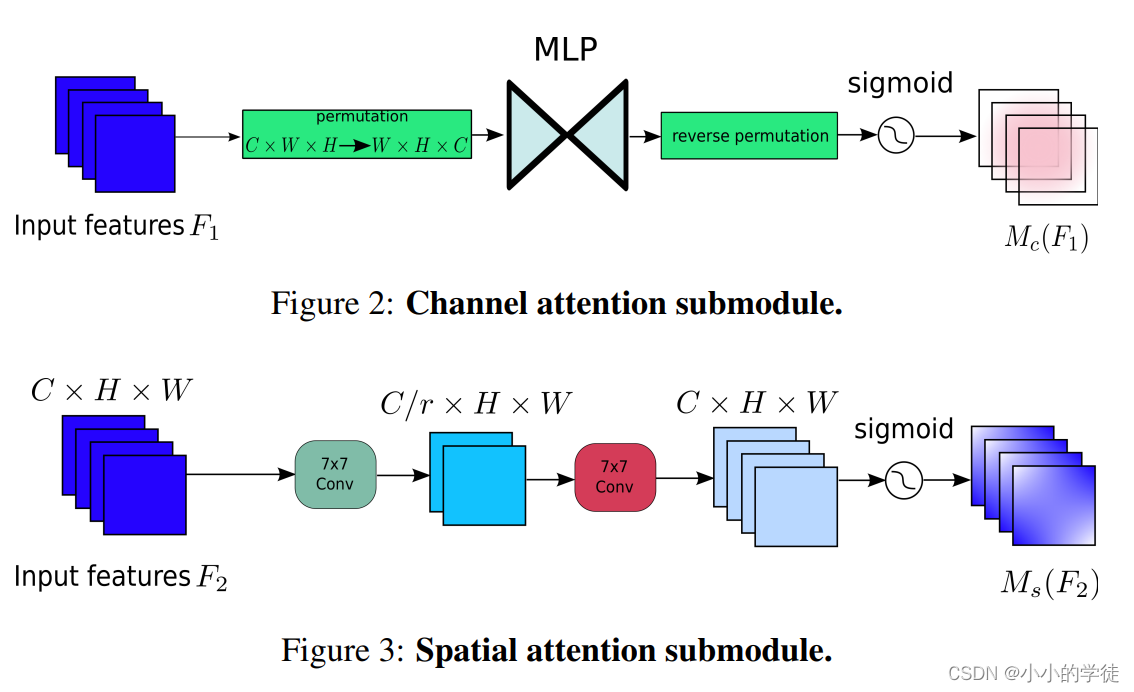
下面是GAM中通道注意力与空间注意力的结构图
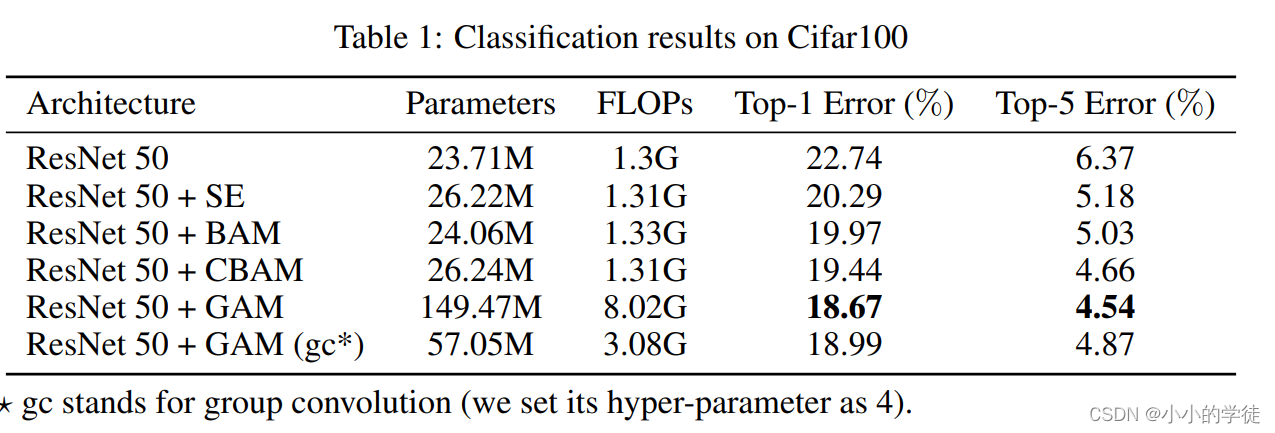
GAM注意力机制在数据集Cifar100上的分类结果
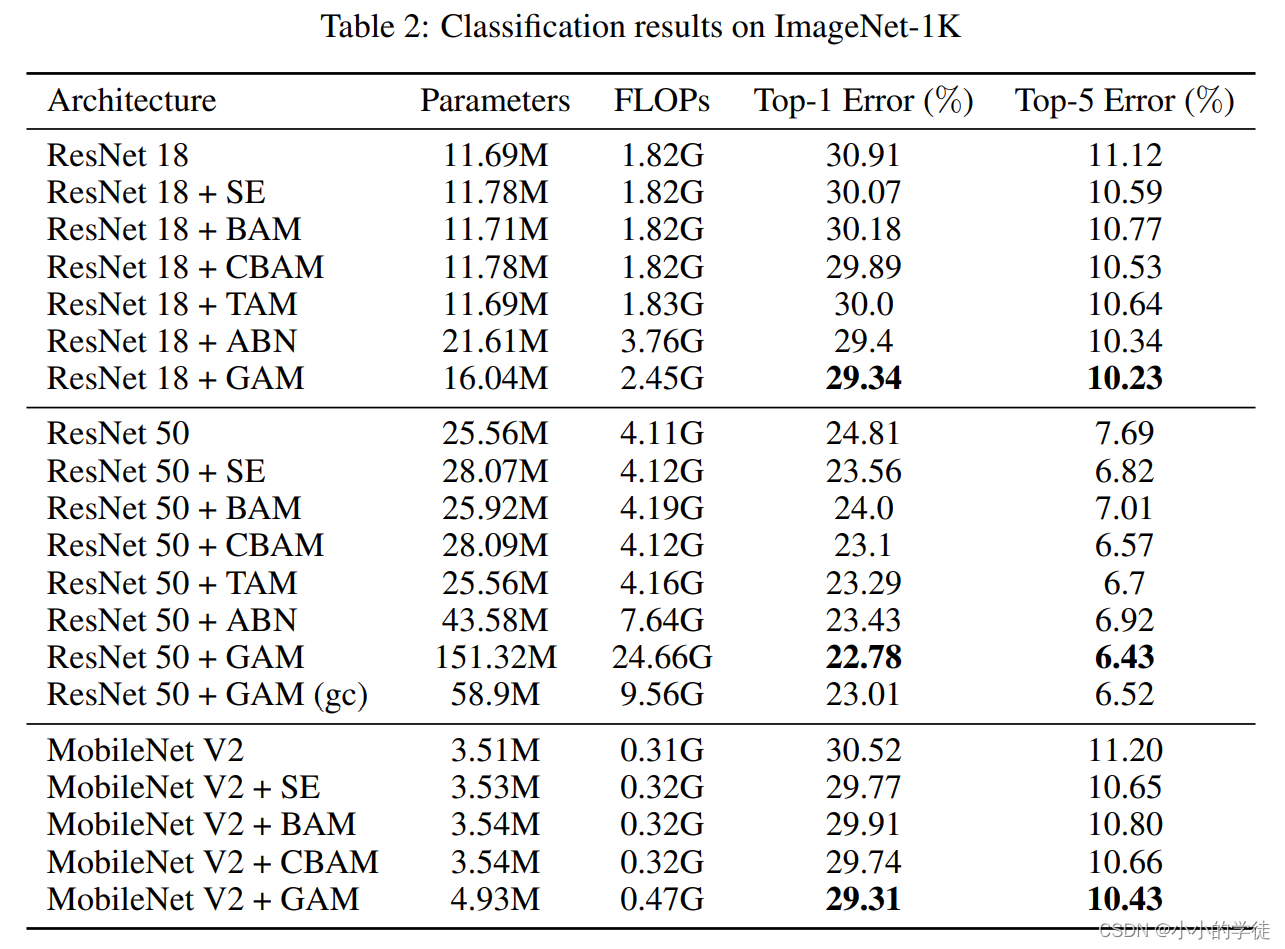
GAM注意力机制在数据集ImageNet-1K的分类结果
【注:代码Pytorch实现Github】:https://github.com/dengbuqi/GAM_Pytorch?tab=readme-ov-file
***【注:论文–Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions链接】:**https://arxiv.org/pdf/2112.05561v1.pdf
【注:GAM注意力机制论文中并没有将其应用到目标检测任务中进行尝试,所以再次强调–它的具体性能得用了才知道!】
二、增加GAM-Attention注意力机制到YOLOv8模型上
方法基本还是一样的,只会有一些细微的差别:
【1: …/ultralytics/nn/modules/conv.py】
在这个文件末尾增加有关GAM-Attention的代码:(有两段,不要少加!!!)
#增加GAM注意力
def channel_shuffle(x, groups=2): ##shuffle channel
# RESHAPE----->transpose------->Flatten
B, C, H, W = x.size()
out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()
out = out.view(B, C, H, W)
return out
class GAM_Attention(nn.Module):
# https://paperswithcode.com/paper/global-attention-mechanism-retain-information
def __init__(self, c1, c2, group=True, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(c1, int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(c1 / rate), c1)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(c1, c1 // rate, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(c1, int(c1 / rate 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











