




 本文介绍了如何在YOLOv8模型中添加SA-Net注意力机制以提高目标检测精度,同时解决了训练和预测过程中遇到的NameError和AttributeError。SA-Net结合通道和空间注意力,虽提升性能但增加计算负担。文章提供代码修改指导,并给出错误处理方案。
本文介绍了如何在YOLOv8模型中添加SA-Net注意力机制以提高目标检测精度,同时解决了训练和预测过程中遇到的NameError和AttributeError。SA-Net结合通道和空间注意力,虽提升性能但增加计算负担。文章提供代码修改指导,并给出错误处理方案。
一、SA-Net注意力机制简介
SA-Net注意力机制全称为(ShuffleAttention)。前文介绍的CBAM注意力机制相比于SE注意力机制来讲,它融合了通道注意力以及空间注意力,即——使用了两种注意力的组合来提高模型对有效信息的专注度(注意:通道与空间注意力也是视觉任务中使用比较广泛的两种注意力,经常是它们的组合变换)。虽然通过这种组合,使其在目标检测任务上有较好的表现,但是不可避免地会增加计算开销。
为了解决这个问题,一种轻量化的注意力机制就诞生了——ShuffleAttention
ShuffleAttention模型结构图如下图所示:
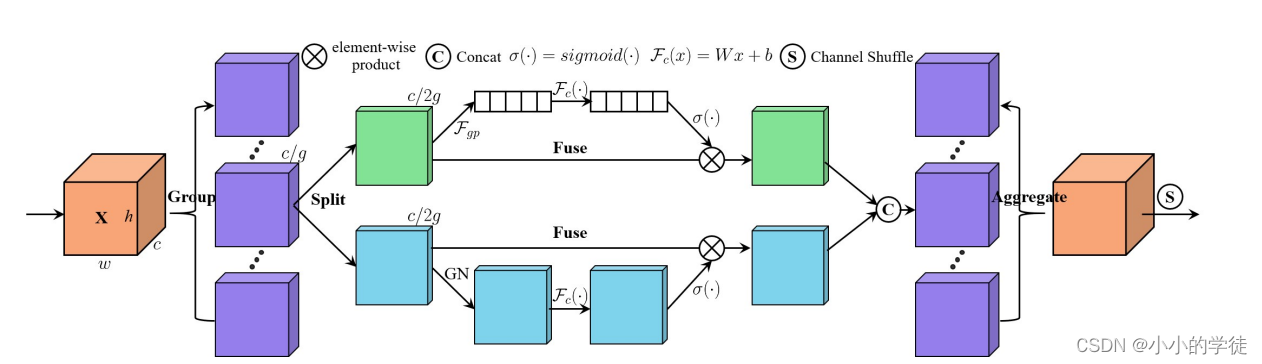
*
目标检测任务中Shuffle Attention模块在COCO val2017上的表现如下表所示:*
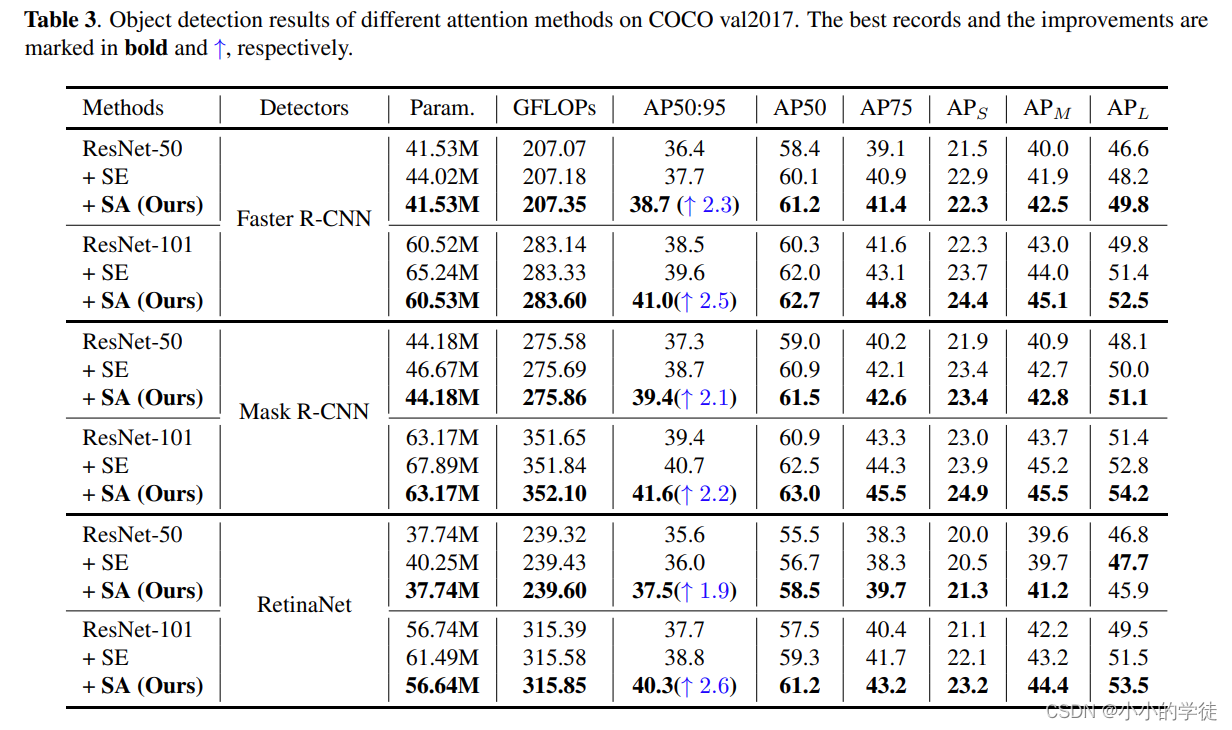
【注1】:如果该模型在你的任务上表现良好或者想了解一下具体的细节的话,请看论文:https://arxiv.org/pdf/2102.00240.pdf
【注2】:Githhub代码:https://github.com/wofmanaf/SA-Net
二、增加ShuffleAttention注意力机制到YOLOv8模型上
*修改的地方与前面增加注意力的方法大部分仍然是一致的,只是会有一点不同!*
【1: …/ultralytics/nn/modules/conv.py】
在这个文件的末尾增加有关ShuffleAttention的代码:
class ShuffleAttention(nn.Module):
def __init__(self, channel=512, reduction=16, G=8):
super().__init__()
self.G = G
self.channel = channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2764
2764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











