







 超级会员免费看
超级会员免费看
 SELF-INSTRUCT是一种新提出的框架,通过引导模型自我生成指令,提升预训练语言模型的指令遵循能力。在GPT-3上应用实验显示,该方法能显著改善模型性能,且在无大量人工标注的情况下实现与InstructGPT_001相当的效果,降低了大规模语言模型的训练成本。
SELF-INSTRUCT是一种新提出的框架,通过引导模型自我生成指令,提升预训练语言模型的指令遵循能力。在GPT-3上应用实验显示,该方法能显著改善模型性能,且在无大量人工标注的情况下实现与InstructGPT_001相当的效果,降低了大规模语言模型的训练成本。
Self-Instruct: 使用自生成指令调整语言模型
随着大规模语言模型(LLM)的能力范围越来越广,其中涉及到的人工标注需求量快速增长,标注成本也不断提高,因此,一些研究人员尝试提出一种能够让模型自己引导自己生成过程的方法,以解决人工成本对模型能力增强的瓶颈。
近日,华盛顿大学等机构联合发表一篇论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》,提出的新框架SELF-INSTRUCT通过引导模型自己的生成过程,提高了预训练语言模型的指令遵循能力。

论文地址:https://arxiv.org/pdf/2212.10560v1.pdf
发表时间:20 Dec, 2022
SELF-INSTRUCT 介绍
SELF-INSTRUCT 是一种半自动化过程,使用来自模型本身的指令信号对预训练的 LM 进行指令调整。如下图所示,整个过程是一个迭代引导算法。
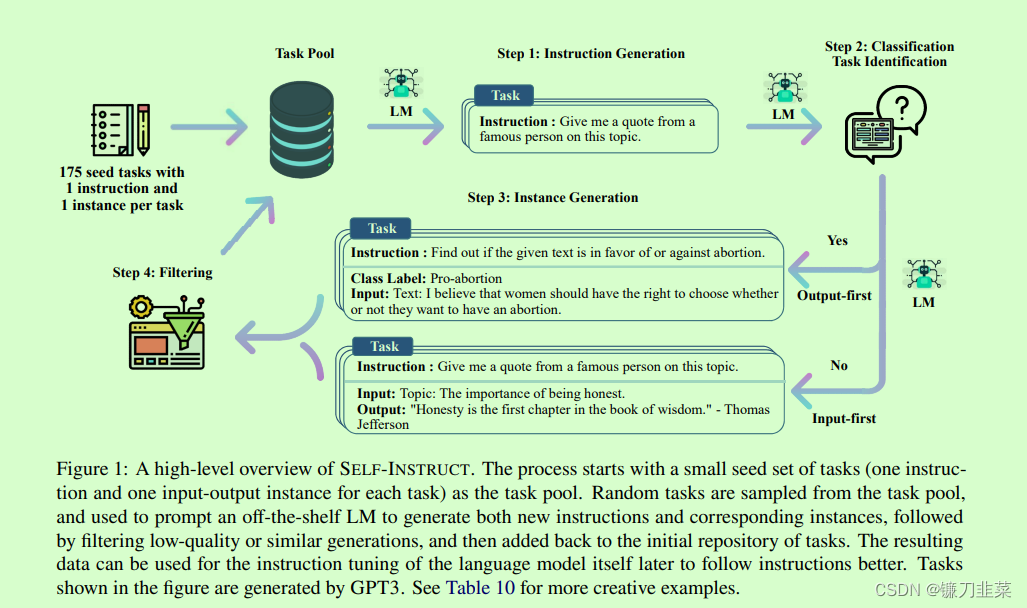
该过程从一组小的任务种子集(每个任务的一条指令和一个输入输出实例)作为任务池开始。 从任务池中抽取随机任务

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











