






本文将讲清楚self-instruct原理,并说明如何利用本地大模型实操!
概念
self-instruct是一种将预训练语言模型与指令对齐的方法。可以通过模型半自动生成数据,而不需要大量的人工标注。 self-instruct用来产生大模型的指令微调数据,以及扩充指令多样性。
原理
自指令过程是一种迭代引导算法,它从手动编写的指令种子集开始,并使用它们提示语言模型生成新指令和相应的输入输出实例。然后对这些生成进行过滤,以删除低质量或相似的生成,并将生成的数据添加回任务池。这个过程可以重复多次,从而产生大量的教学数据,可用于微调语言模型以更有效地遵循指令。
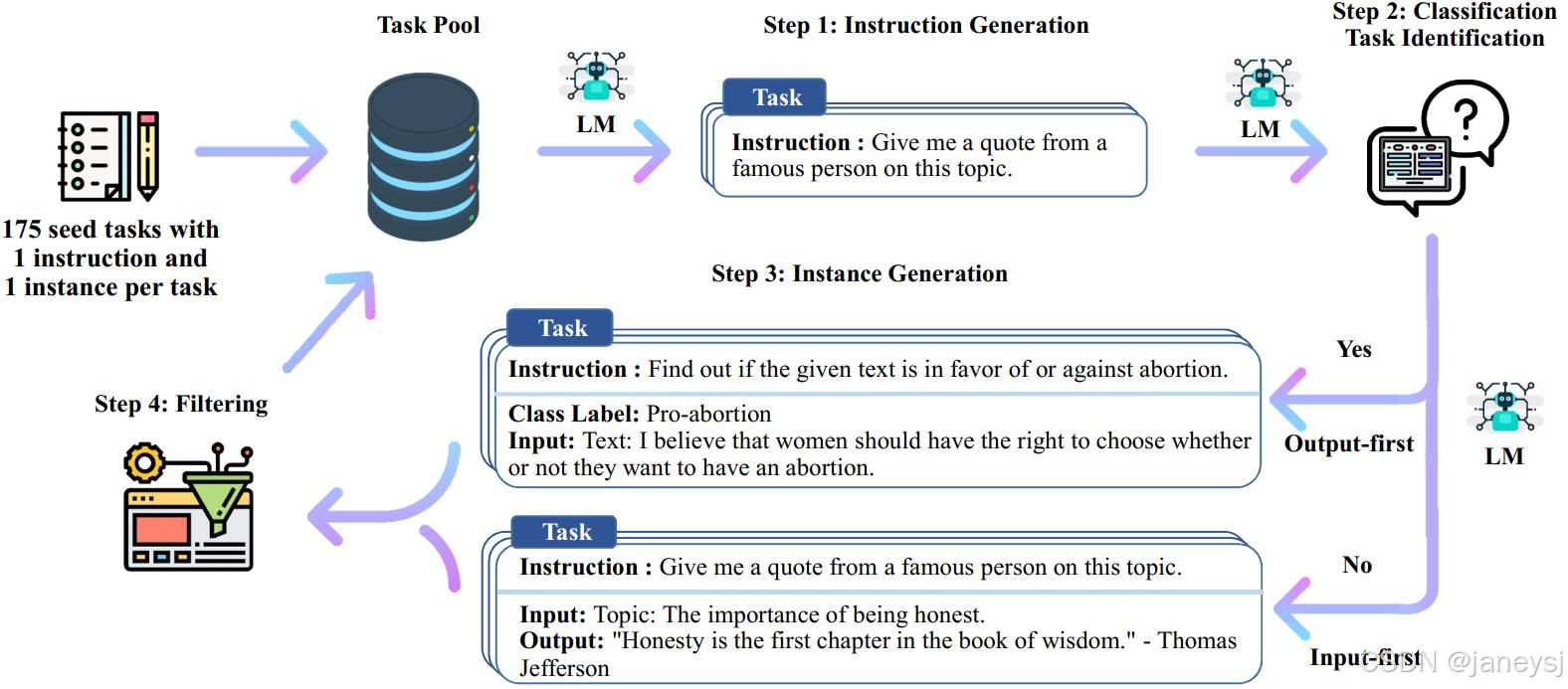
例如,上图所示,主要分为四个步骤:
1. 自动生成多样化的指令集
- 功能: 利用预训练的语言模型扩展初始的人工编写的种子指令。
- 主要任务: 通过自我迭代的方式生成新的指令,并将结果保存到文件中。
- 输入: 种子指令文件 (
seed_instructions.jsonl):包含由人类编写的基础指令。 - 输出: 自动生成的指令文件 (
machine_generated_instructions.jsonl):包含机器生成的新指令。
2. 利用大模型区分自动生成的指令是否属于分类任务
- 功能: 识别并标记指令是否为分类任务。
- 主要任务: 加载已有的机器生成指令,构建适当的提示询问每个指令是否为分类任务,并将结果保存到文件中供后续步骤使用。
- 输入: 自动生成的指令文件 (machine_generated_instructions.jsonl)。
- 输出: 指令分类标签文件 (is_clf_or_not_davinci_template_1.jsonl):包含每个指令及其是否为分类任务的标签。
3. 为每个指令创建具体的输入输出对(实例)
- 功能: 为每个指令生成具体的输入输出对(实例)。
- 主要任务: 根据指令是否为分类任务选择合适的模板,发送构建好的提示给API以获得实例,进行必要的后处理如去除无效或重复的实例,并保存结果。
- 输入:
自动生成的指令文件 (machine_generated_instructions.jsonl)。
指令分类标签文件 (is_clf_or_not_davinci_template_1.jsonl)。
- 输出:
实例文件 (machine_generated_instances.jsonl):包含每个指令及其对应的多个具体输入输出对。
注意,这里根据是否是分类任务来选择模板,如果是分类任务则使用output-first模板,否则使用input-first模板。分类任务的output就是分出来的种类,使用output-first方式是因为此种方式适合扩展和丰富数据集,特别是生成难以直接思考的问题(逆向问题设计),主要用于生成创新性或逆向思考的任务,帮助模型探索多样化的指令形式。
4. 准备用于微调的数据集
- 功能: 将生成的实例与分类标签相结合,并根据需要加入种子任务,创建一个结构化的数据集,供后续微调使用。
- 主要任务: 解析之前生成的实例文件和分类标签,控制每个任务的实例数量并确保数据集的质量,将所有经过处理的训练实例格式化并保存到文件中。
- 输入:
实例文件 (machine_generated_instances.jsonl)。
指令分类标签文件 (is_clf_or_not_davinci_template_1.jsonl)。
种子任务文件 (seed_tasks.jsonl)(可选):高质量的人类编写任务实例。
- 输出:
微调数据集 (all_generated_instances.jsonl):包含所有经过处理的训练实例,用于后续模型微调。
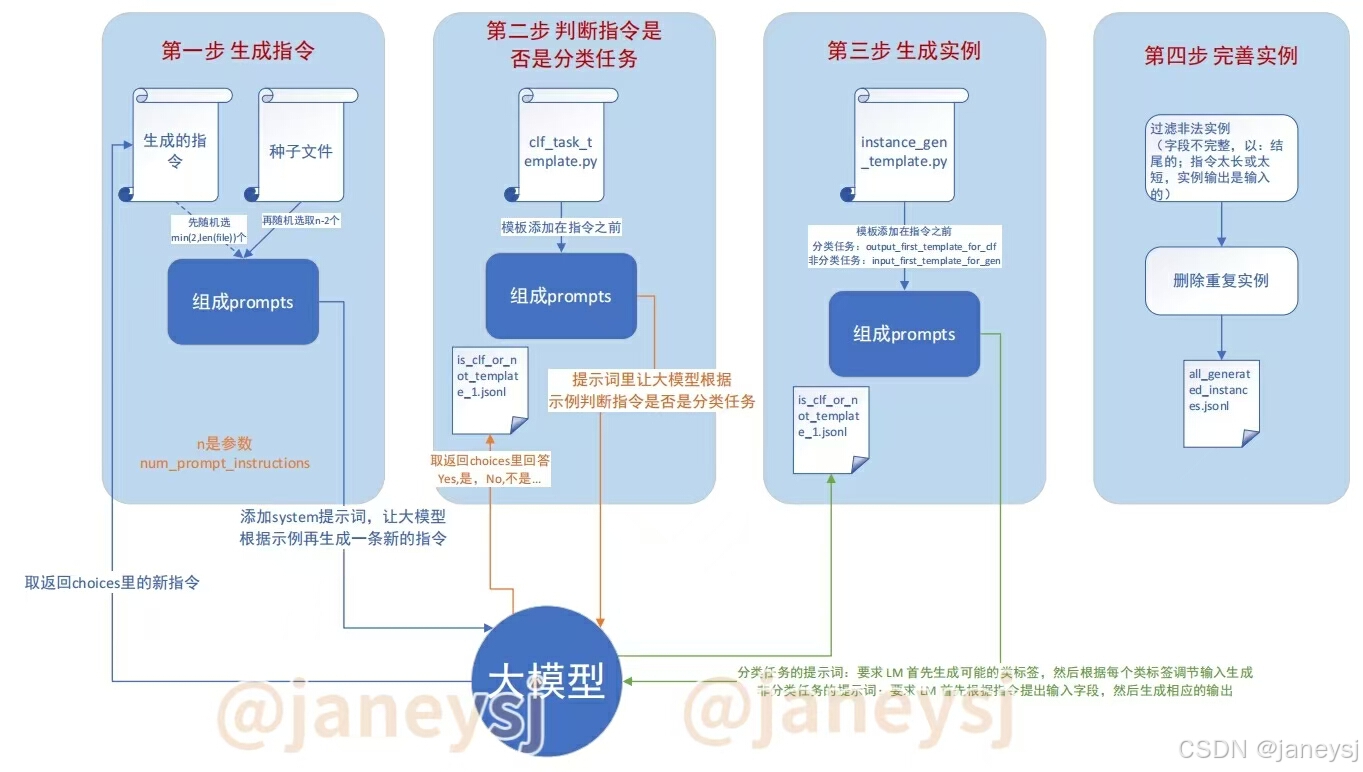
根据以上,我按照自己的理解画了一个图,流程如下:
实践
要基于足够大的大模型(例如 chatgpt3.5以上)因此,需要你有一个chatgpt账号,这个请自行搜索。
1. 申请chatgpt APIKey(土豪请使用此方法,不免费)
登录openai官网https://platform.openai.com/,直接看Quickstart里就有创建APIKey的链接。
按照操作即可。
很遗憾,chatgpt 的 APIKey没有免费的,因此放弃使用。那我们先来看看self-instruct的用法吧。
下文中的“我们”是指self-instruct的开发者。代码指的是 GitHub - yizhongw/self-instruct: Aligning pretrained language models with instruction data generated by themselves. main分支。
2. 使用本地千问大模型
公开的千问模型免费 10000个token,因此还是需要搭建一个本地模型。
首先你要有一个带GPU的环境,这里我使用的是容器环境,配备2个V100显卡,内存,和硬盘。用ollama拉起一个qwen2:72b模型(拉起方法详见我的另一篇博文使用API方式远程调用ollama模型-优快云博客)
这个工程可以用,但是文件要一个一个下载。
从头开始生成Self-Instruct数据
第一步:根据种子生成instructions
该步骤实现的方式是运行如下命令:
# 1. 从种子任务生成指令(instruct)
./scripts/generate_instructions.sh该脚本的内容如下所示:

该脚本是从种子文件里和已经生成自动生成的instruction里面选取 8 个任务指令作为上下文示例。 8 条指令中,6 条来自人工编写任务,2条来自前面步骤中模型生成的任务(初始时该文件为空),然后让大模型按照这个几个instruct再续接上一条新的instruct作为返回(即9条任务)。然后循环生成足够数量(这里指定10000个)的指令,第一步结束。
这里面的8,6都是可以用参数指令的。另外,上面脚本的参数意思是总共生成10000条指令,每次发送1个请求给大模型(大模型响应一次),每个请求里面有8个指令组成的prompts.
需要注意的是 GitHub - yizhongw/self-instruct: Aligning pretrained language models with instruction data generated by themselves. 源码里面使用的gpt3 API接口,需要改成qwen的API接口。并且返回的结果也有区别,即如果一个请求里面有多个Task,gpt3返回的结果里面有多个choices字段,而qwen的返回只有一个choices字段,多个task的回答在一起。因此每次只发送一个请求,便于解析。
此步骤生成的单条指令长这个样子:

其中most_similar展开如下所示:

第二步:判断生成的指令是否是分类任务
该步骤实现的方式是运行如下命令:
# 2. 识别指令是否代表分类任务
./scripts/is_clf_or_not.sh该脚本的内容如下:
batch_dir=data/gpt3_generations/
python self_instruct/identify_clf_or_not.py \
--batch_dir ${batch_dir} \
--engine "qwen2:72b" \
--request_batch_size 5这一步是把第一步的生成结果的每条指令,添加上clf_task_template.py 分类模板内容在每一条指令之前,启发大模型判断最后的指令是否是分类任务。
提示词内容如下所示:

然后生成结果会标明每条指令是否是分类任务。对应上面的示例,此步骤生成的结果如下所示:

第三步:为每条指令生成实例
这步是最关键的一步,也是最难理解的一步。该步骤实现的方式是运行如下命令:
# 3. 为每条指令(instruct)生成实例(instance)
./scripts/generate_instances.sh该脚本的内容是:
batch_dir=data/gpt3_generations/
python self_instruct/generate_instances.py \
--batch_dir ${batch_dir} \
--input_file machine_generated_instructions.jsonl \
--output_file machine_generated_instances.jsonl \
--max_instances_to_gen 5 \
--engine "qwen2:72b" \
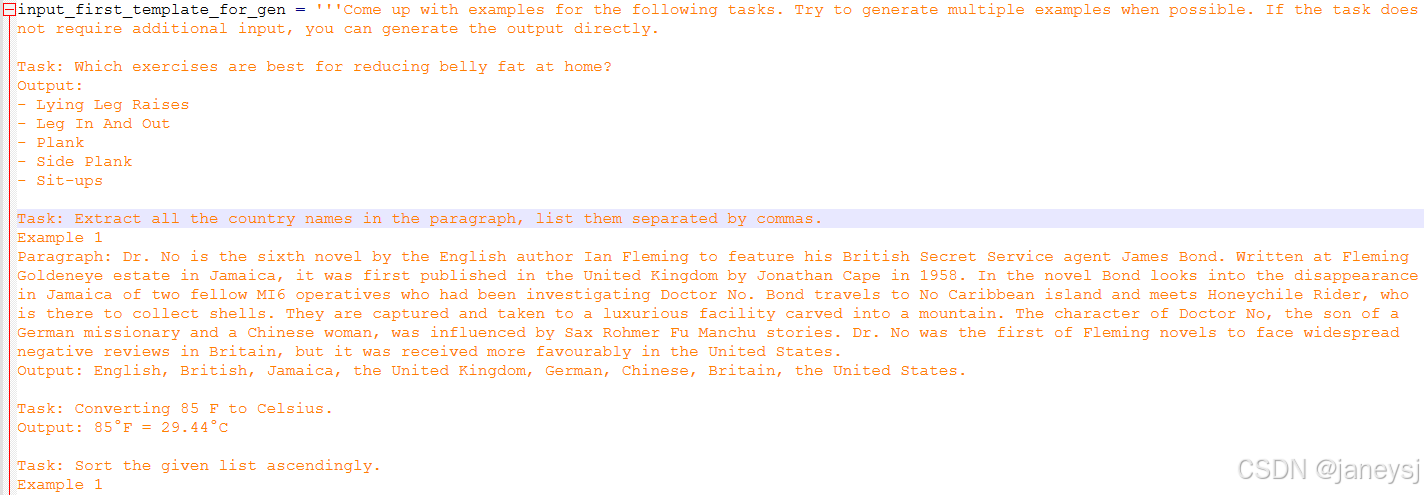
--request_batch_size 5该步骤用到了 instance_gen_template.py 中的两个模板output_first_template_for_clf 和
input_first_template_for_gen .

上图所示是英文版output_first模板部分内容。
运行脚本时,把output_first_template放在前面,添加目标指令在最后,让大模型生成实例(下图使用的是中文output first template):

对于非分类任务则使用下图所示input_first模板
同样把模板内容放在前面,添加目标指令在最后,让大模型生成实例。上面的示例在此步骤的生成结果如下图所示:

第四步:过滤优化
这是最后一个步骤,所有的步骤如下所示:
# 1. 从种子任务生成指令(instruct)
./scripts/generate_instructions.sh
# 2. 识别指令是否代表分类任务
./scripts/is_clf_or_not.sh
# 3. 为每条指令(instruct)生成实例(instance)
./scripts/generate_instances.sh
# 4. 过滤、处理和重新格式化
./scripts/prepare_for_finetuning.sh分类实例生成
1.生成指令
2.判断是否是分类任务

3.生成实例


4.过滤
最终数据格式如下所示:



















 7397
7397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









