




基于sklearn-crfsuite进行命名实体识别
本文中,针对
CoNLL2002数据训练了一个用于
命名实体识别的基本
CRF模型,并检查其权重以查看该模型学到了什么。需要
NLTK>3.x和
sklearn-crfsuite Python包。本文使用
Python 3。
0. 条件随机场
**条件随机场:**条件随机场这个模型属于概率图模型中的无向图模型,这里我们不做展开,只直观解释下该模型背后考量的思想。一个经典的链式 CRF 如下图所示:
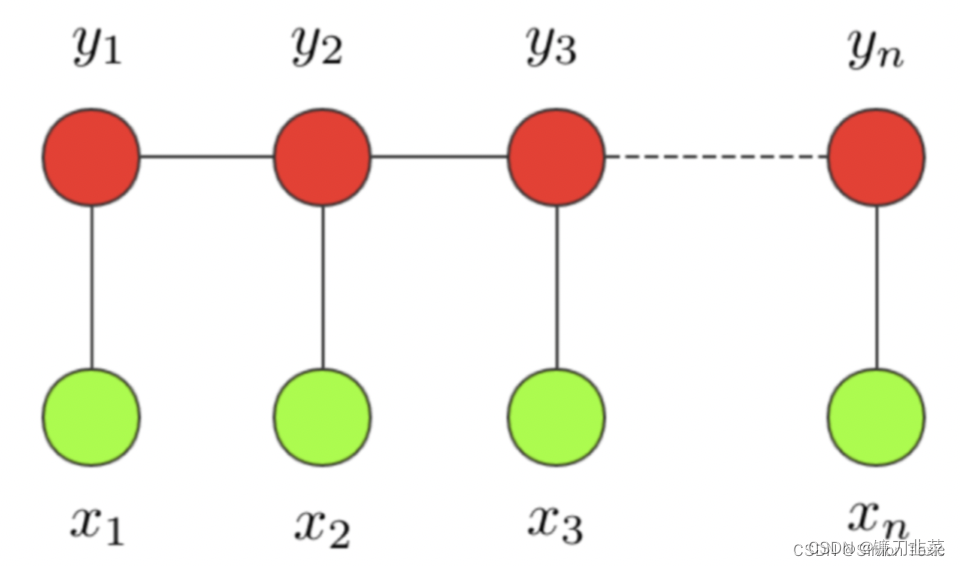
CRF 本质是一个无向图,其中绿色点表示输入,红色点表示输出。点与点之间的边可以分成两类:
- 一类是 x 与 y 之间的连线,表示其相关性;
- 另一类是相邻时刻的 y之间的相关性。
也就是说,在预测某时刻 y时,同时要考虑相邻的标签解决。当 CRF 模型收敛时,就会学到类似 P-B 和 T-I 作为相邻标签的概率非常低。
对于 CRF,我们给出准确的数学语言描述:设 X 与 Y 是随机变量,P(Y|X) 是给定 X 时 Y 的条件概率分布,若随机变量 Y 构成的是一个马尔科夫随机场,则称条件概率分布 P(Y|X) 是条件随机场。
1. 训练数据
首先导入依赖库
import nltk
import eli5
import sklearn
import sklearn_crfsuite
import scipy.stats
from itertools import chain
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RandomizedSearchCV
from sklearn_crfsuite import scorers
from sklearn_crfsuite import metrics
CoNLL2002数据集包含西班牙语句子列表,并带有注释的命名实体。 它使用IOB2编码。 CoNLL 2002 数据还提供词性标记。
import nltk
nltk.download('conll2002')
'''
[nltk_data] Downloading package conll2002 to /root/nltk_data...
[nltk_data] Package conll2002 is already up-to-date!
True
'''
nltk.corpus.conll2002.fileids()
'''
['esp.testa', 'esp.testb', 'esp.train', 'ned.testa', 'ned.testb', 'ned.train']
'''
train_sents = list(nltk.corpus.conll2002.iob_sents('esp.train'))
test_sents = list(nltk.corpus.conll2002.iob_sents('esp.testb'))
train_sents[0]
'''
[('Melbourne', 'NP', 'B-LOC'),
('(', 'Fpa', 'O'),
('Australia', 'NP', 'B-LOC'),
(')', 'Fpt', 'O'),
(',', 'Fc', 'O'),
('25', 'Z', 'O'),
('may', 'NC', 'O'),
('(', 'Fpa', 'O'),
('EFE', 'NC', 'B-ORG'),
(')', 'Fpt', 'O'),
('.', 'Fp', 'O')]
'''
2. 特征提取
接下来,定义一些特征。 POS标签可以看作是预先提取的特征。 这里提取更多特征(word parts、简化的POS标签、lower/title/upper标记、临近单词的特征)并将它们转换为 sklear-crfsuite 格式——每个句子都应转换为字典列表。 这是一个非常简单的基线任务; 当然也可以做得更好。
sklearn-crfsuite(和python-crfsuite)支持多种特征格式; 这里我们使用feature dicts。
def word2features(sent, i):
word = sent[i][0]
postag = sent[i][1]
features = {
'bias': 1.0,
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle(),
'word.isdigit()': word.isdigit(),
'postag': postag,
'postag[:2]': postag[:2],
}
if i > 0:
word1 = sent[i-1][0]
postag1 = sent[i-1][1]
features.update({
'-1:word.lower()': word1.lower(),
'-1:word.istitle()': word1.istitle(),
'-1:word.isupper()': word1.isupper(),
'-1:postag': postag1,
'-1:postag[:2]': postag1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











