



大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Pre-trained Large Language Models Use Fourier Features to Compute Addition
大型预训练语言模型展现出了令人印象深刻的数学推理能力,但它们是如何进行基本的算术运算,例如加法的,仍然不清楚。本文表明,预训练的大语言模型使用傅里叶特征进行加法运算——隐藏状态中的维度通过一组在频率域中稀疏的特征来表示数字。在模型中,多层感知器(MLP)和注意力层以互补的方式使用傅里叶特征:MLP层主要使用低频特征来近似答案的幅度,而注意力层主要使用高频特征来进行模ular加法(例如,计算答案是偶数还是奇数)。预训练对于这种机制至关重要:从零开始训练以进行数字加法的模型仅利用低频特征,导致准确度较低。向随机初始化的模型引入预训练的令牌嵌入可以挽救其性能。总的来说,我们的分析表明,适当的预训练表示(例如,傅里叶特征)可以解锁变压器学习精确算法任务机制的能力。
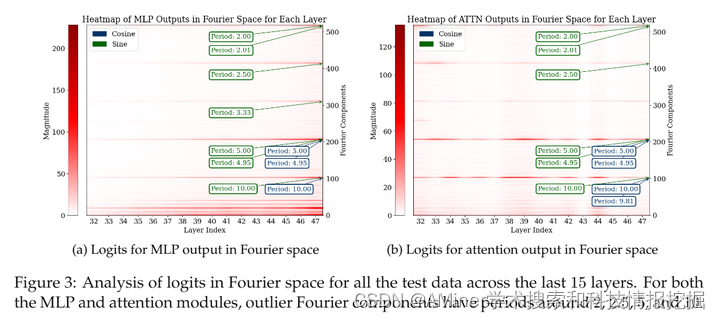
链接:https://www.aminer.cn/pub/66611c9001d2a3fbfc760480/?f=cs
2.Transfer Q Star: Principled Decoding for LLM Alignment
论文主要研究了大规模语言模型(LLM)对齐的问题。传统的微调方法在实际应用中需要更新大量的模型参数,计算成本较高。相比之下,通过解码进行对齐的方法可以直接调整响应分布,而不需要更新模型,为对齐提供了一个轻量级和适应性强的框架。然而,这种方法需要访问最优Q函数(Q),这在实际中往往是不现实的。因此,之前的最先进(SoTA)方法要么使用从参考模型得到的Q^π_来近似Q,要么依赖短期奖励,导致解码性能不佳。本文提出了一种新的方法Transfer Q,它通过一个与基线奖励ρ_对齐的基线模型ρ_来隐式估计目标奖励r的最优价值函数。理论分析表明,Transfer Q的优化性是严格的,推导出了次优性差距的上界,并根据用户需求识别了一个超参数来控制从预训练的参考模型偏离的程度。实验结果表明,与之前的最先进方法相比,Transfer Q*显著降低了次优性差距,并在多个合成和真实数据集上的各项关键指标(如连贯性、多样性和质量)都表现出色。
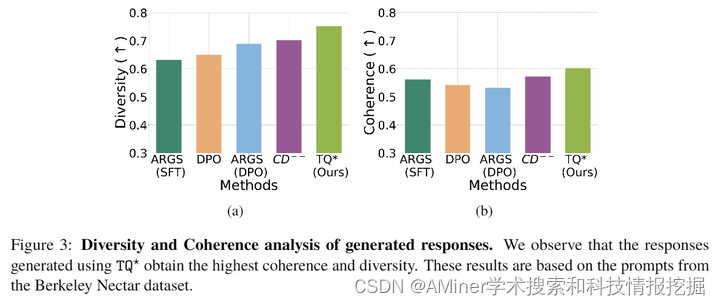
链接:https://www.aminer.cn/pub/665d238001d2a3fbfc1e2fa8/?f=cs
3.SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
这篇论文介绍了一种新的训练框架SaySelf,旨在教会大型语言模型(LLM)更准确地表达他们的信心。目前,LLM经常生成不准确或虚假的信息,并且通常无法表明他们的信心,这限制了它们更广泛的应用。过去的研究通过直接或自我一致性提示,或构建具体的训练数据来引导LLM表达信心,但这些方法的效果不佳,基于训练的方法也局限于二元或准确性较低的分组信心估计。SaySelf通过让LLM使用自然语言自动总结特定知识中的不确定性,从而识别他们参数知识的不足和解释他们的不确定性,这一方法基于对多个采样推理链的不一致性分析,并将生成的数据用于有监督的微调。此外,利用精心设计的奖励函数进行强化学习来校准信心估计,激励LLM提供准确、高信心的预测,并对错误输出中的过度自信进行惩罚。在分布内和分布外数据集上的实验结果表明,SaySelf在减少信心校准误差和保持任务性能方面是有效的。研究表明,生成的自我反思理性是合理的,并且可以进一步有助于校准。

链接:https://www.aminer.cn/pub/665d23a001d2a3fbfc1f144c/?f=cs
4.When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs
本文对大型语言模型(LLM)自我修正的能力进行了批判性调研。自我修正是一种通过在推理过程中使用LLM来改进响应的方法。先前的研究提出了使用不同反馈来源的自我修正框架,包括自我评估和外部反馈。然而,目前尚无共识关于LLM何时能够纠正自己的错误,因为近期研究也报告了负面结果。在这项工作中,我们批判性地审视了广泛的论文,并讨论了成功自我修正所需的条件。我们首先发现,先前的研究往往没有详细定义研究问题,并涉及不切实际的框架或不公平的评估,这高估了自我修正。为了解决这些问题,我们将自我修正研究中的研究问题进行分类,并提供了一个设计适当实验的检查表。根据新分类的研究问题,我们的批判性调研表明:(1)没有先前的工作在通用任务中展示成功使用提示的LLM的自我修正,(2)在没有可靠外部反馈的任务中自我修正表现良好,(3)大规模微调使自我修正成为可能。
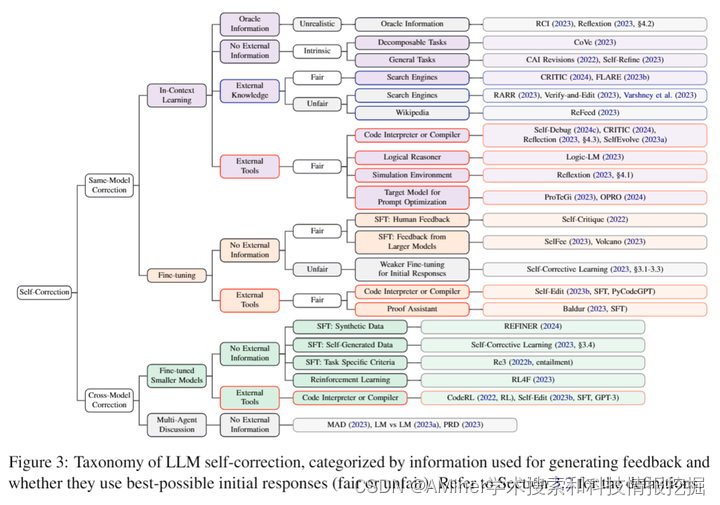
链接:https://www.aminer.cn/pub/665e891f01d2a3fbfcc24938/?f=cs
5.Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models
这篇论文通过一个简单、短小且用简洁自然语言表述的日常常识问题,展示了最新的大型语言模型(LLM)在功能和推理能力上的巨大崩溃。尽管这些模型在各种标准化的基准测试中获得了高分,声称能够在少量或零样本的情况下跨各种任务和条件强力转移,但随着预训练规模的增加,它们表现出预测函数改进的缩放规律,但实验证明,这些最先进的模型在处理简单问题时,其功能和推理能力的崩溃是戏剧性的。模型在给出错误答案时表现出强烈的过度自信,并经常提供类似虚构的解释来证明其明显错误的回应的有效性。尝试通过各种增强提示或多步骤重新评估等标准干预措施来获得正确答案的努力均告失败。作者将这一初步观察结果提交给科学和技术界,以刺激对当前一代LLM所声称的能力进行紧急重新评估。为了正确检测当前最先进评估程序和基准测试明显未发现的基本推理缺陷,这种重新评估也需要共同行动来创建标准化的基准测试。
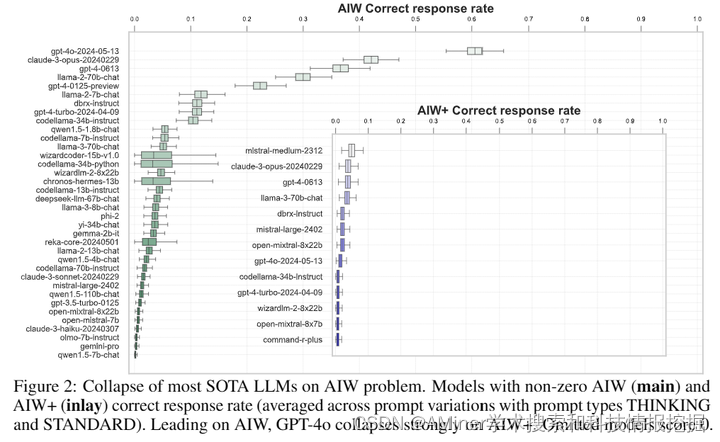
链接:https://www.aminer.cn/pub/665fc72e01d2a3fbfc4cf39a/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









