





最近Sora2爆火,让不少人刷新了对AI视频的认知。 Sora2 生成的视频在真实感、场景还原和物理一致性上都有明显提升。 但随之而来的风险 也在上升:不实信息通过视频扩散,个人肖像可能被滥用,广告内容存在误导隐患…
sora2生成视频
Sora2生成视频
识别社交媒体中的视频究竟是AI生成还是真实拍摄,已成为紧迫议题。传统视频真假鉴定方法要么 聚焦局部伪迹(如:边缘拼接、细节模糊) ,要么 依赖大规模标注数据学习生成特征 ;但面对 能近似模拟物理场景的Sora2 ,这些手段常出现 失效 。
近期,华南理工大学、香港浸会大学等团队在NeurIPS 2025接收的工作中提出一种基于物理驱动的视频鉴伪方法:以 自然场景梯度(NSG)为核心 , 用时空一致性而非局部伪迹来判定视频真伪。 方法上,先为视频构建NSG描述,再与真实视频库做分布比较得到分数。观察 视频的时空演化是否违背自然运动的核心逻辑 。
今天我们就用AMiner来拆解这套 “物理驱动的真假AI视频鉴定术”。

别找“穿帮”,找“违章”:NSG的物理直觉
传统视频鉴伪方法主要通过分析帧间运动矢量的异常模式或像素级的不连续性来识别伪造痕迹。 当 生成模型升级后,其伪造的伪迹特征会随之演化, 原有的检测模型会过度依赖旧特征而出现过拟合问题,显著降低识别准确率。

这项工作把视频真伪的判断标准下沉到 物理一致性 :把视频视作随时间演化的概率密度场, 真实的运动应符合 类似流体连续性的 配平关系 。局部的密度变化需要与周围的流入/流出情况相匹配。
当 某些时空区域与上述配平约束不一致时 ,即可认定出现配平失衡 (局部变化无法由邻域流动解释) ,将其视作是AI生成视频的特征,判定为AI生成视频。
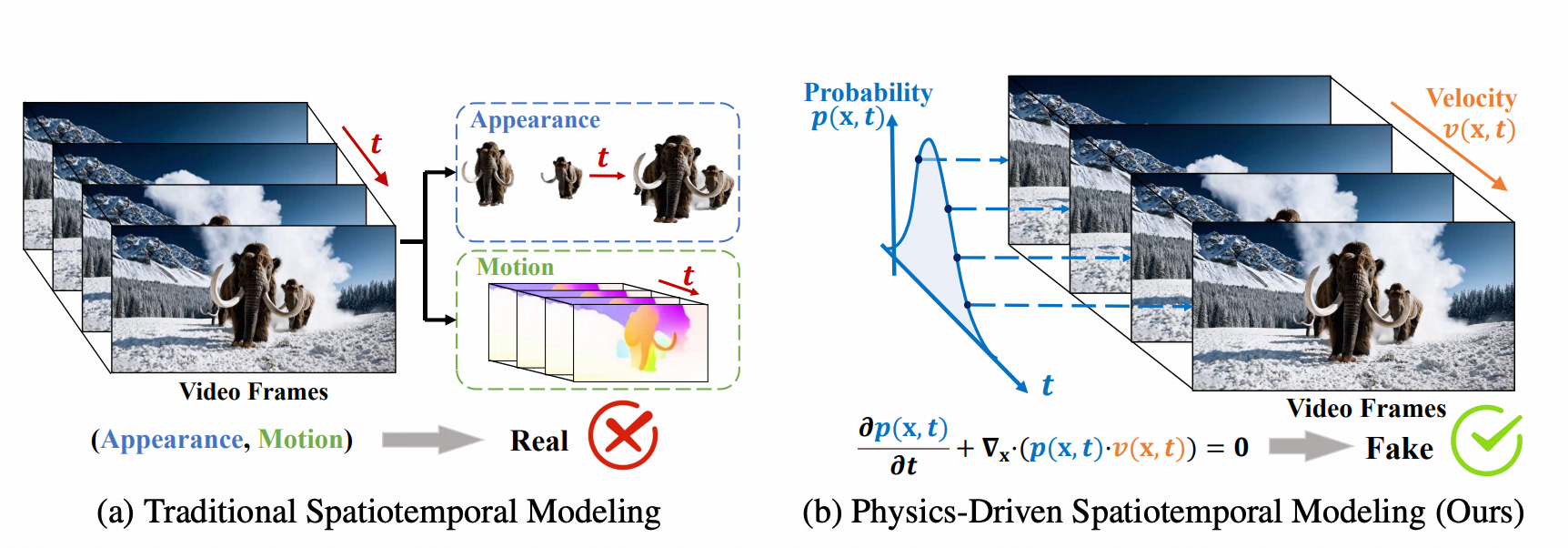
- 一句话概括 :NSG用来衡量单位时间内画面在空间上变化的合理性即 “单位时间里,画面在空间上变化是否符合物理规律”。自然视频受物理一致性的约束 ,AI生成视频则容易出现偏离物理规律的情况。
概率流守恒的直觉示意
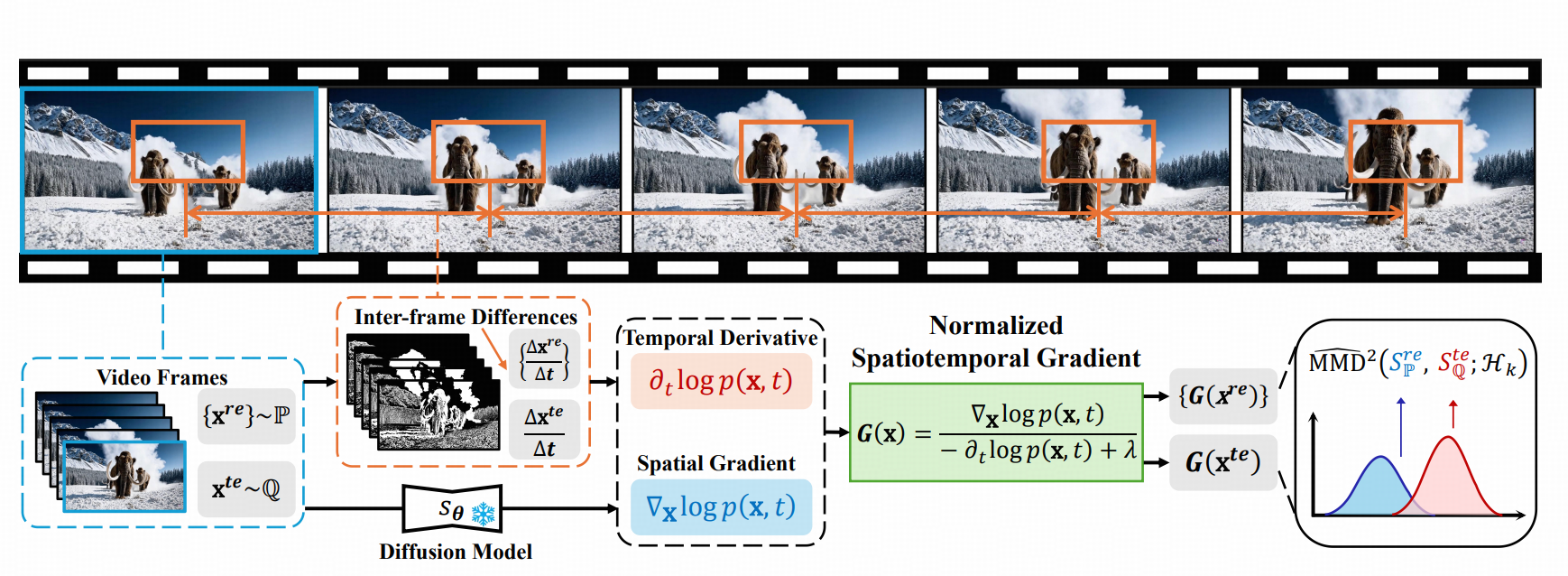
为实现NSG的可计算化,该方法以 预训练扩散模型的近似对数密度的空间梯度(score)作为空间项的近似 ,其中 score定义 为对数密度 的空间梯度 ∇ x log p (x,t) ; 时间项 则 基于 亮度恒常假设构造 ,对应对数密度的时间导数 ∂log p (x,t)/∂t 的估计。
两者耦合后形成时空一致性特征 ,无需显式光流估计即可稳定表征动态变化。该设计 降低对特定伪迹的依赖,并提升对细微时空不一致的检出能力 。
从统计量到检测器:NSG-VD的两步走
为把“是否为AI生成视频”量化为可看见复现的分数。NSG-VD两步:先提取NSG的时空表征,再与真实视频库做分布比较。
Step 1 提 NSG 表征
针对视频的每一帧, 使用预训练扩散模型得到空间 score( ∇ x log p (x,t)的近似 ), 并基于亮度恒常假设估计时间导数( ∂log p (x,t)/∂t )。二者耦合形成帧级NSG; 随后对整段视频进行聚合,得到 该视频的 时空特征分布 。
该 过程 不依赖人脸、水印等特定伪迹,也无需显式光流网络, 计算路径稳定且可复现 。
Step 2 用 MMD 做分布度量
把“待鉴定视频” 的NSG分布,与“真实视频参考库”的NSG分布做 最大均值差异(MMD) 比较:如果两者越相似,MMD就越小;差异越大,MMD就越大。模型根据这个分数与预先设定的阈值τ做出判定,从而把“可能是AI生成的视频”转换为可复现的数值标准。
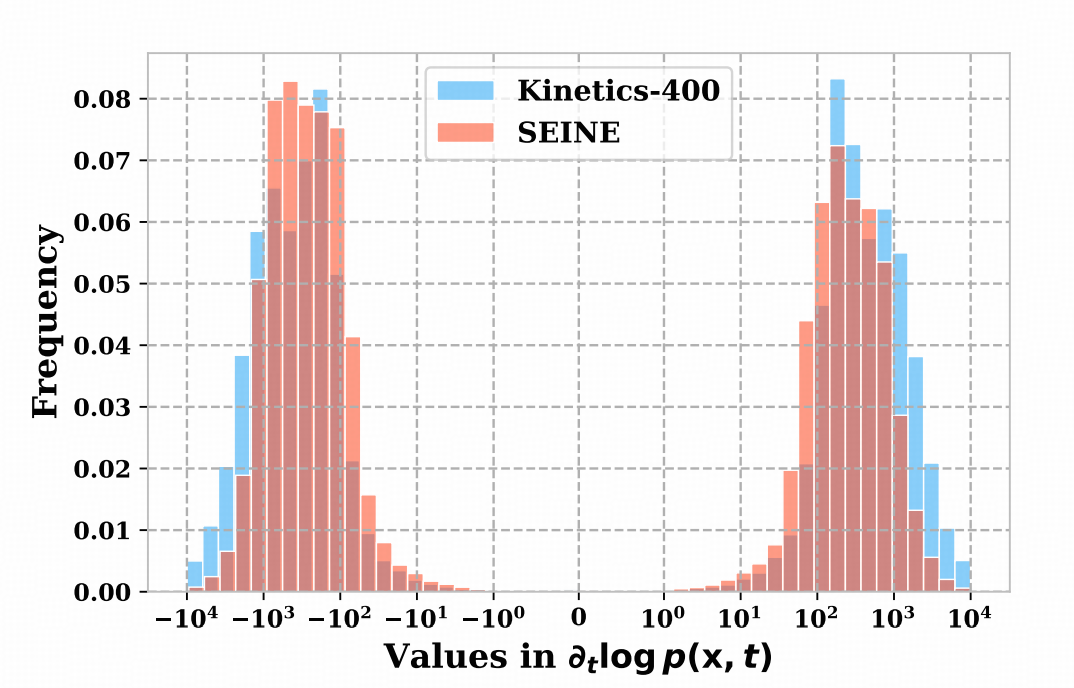
NSG-VD在做真实视频与待监测视频的 NSG 分布比较时,会默认使用固定核计算MMD。这种方法在单一来源(同一生成器、同一场景)下足够。但进入跨来源部署(不同生成器混用、素材来自多域、分辨率与压缩率不一致),则固定核对分布差异的刻画表现不稳定。
因此,为模型的提升跨来源稳健性,论文引入 deep kernel学习 ,把NSG映射到可学习核空间;并给出多群体场景的核训练策略,使同一阈值在不同生成器和不同的场景上仍然稳定。
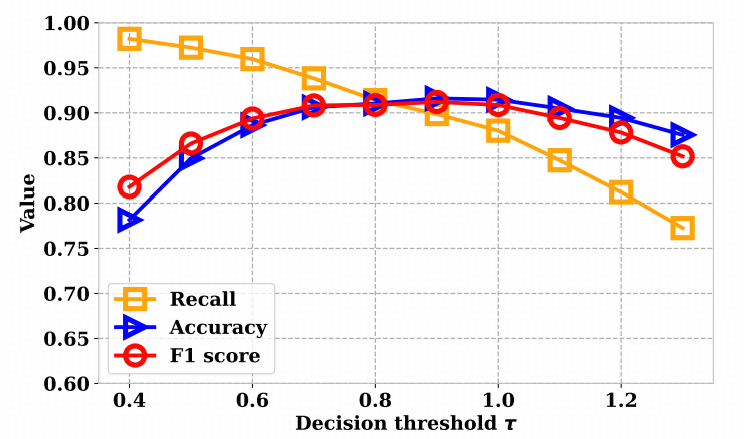
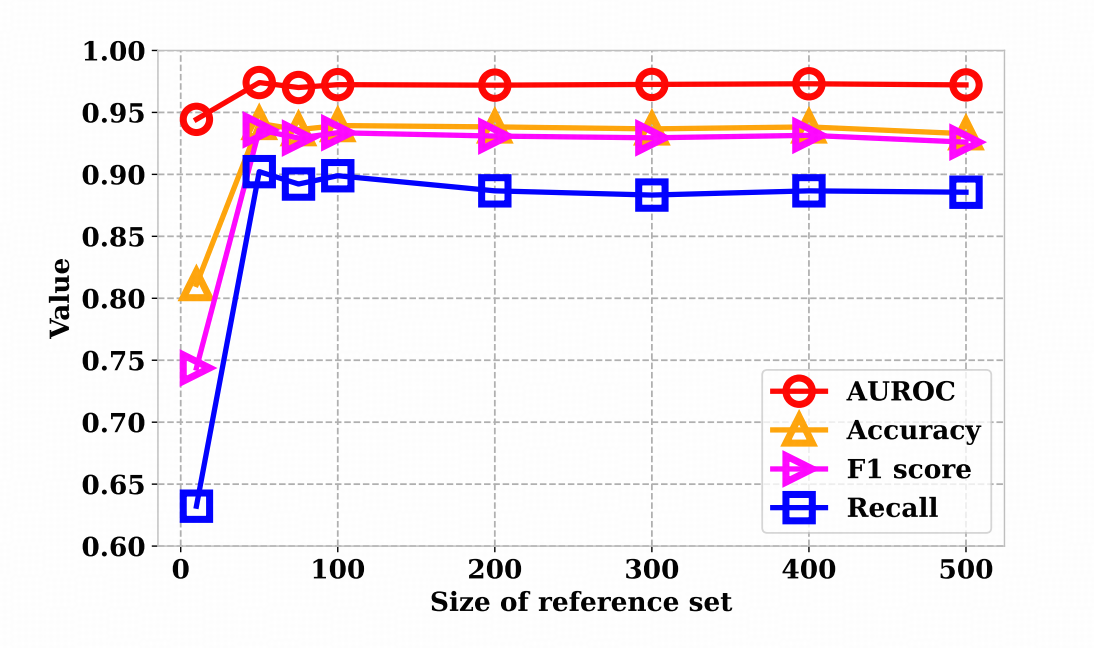
根据 参考库规模 的实验结果, 真实参考集过小会带来抽样偏差。 论文的实验显示,当参考库从10条增加到500条时,AUROC、Accuracy、F1、Recall 等指标在≥100条左右就基本趋稳,再继续扩大收益有限;而只有十几条样本时波动明显。因此,落地时建议先准备约百级规模的真实参考库,再在验证集上微调阈值τ。
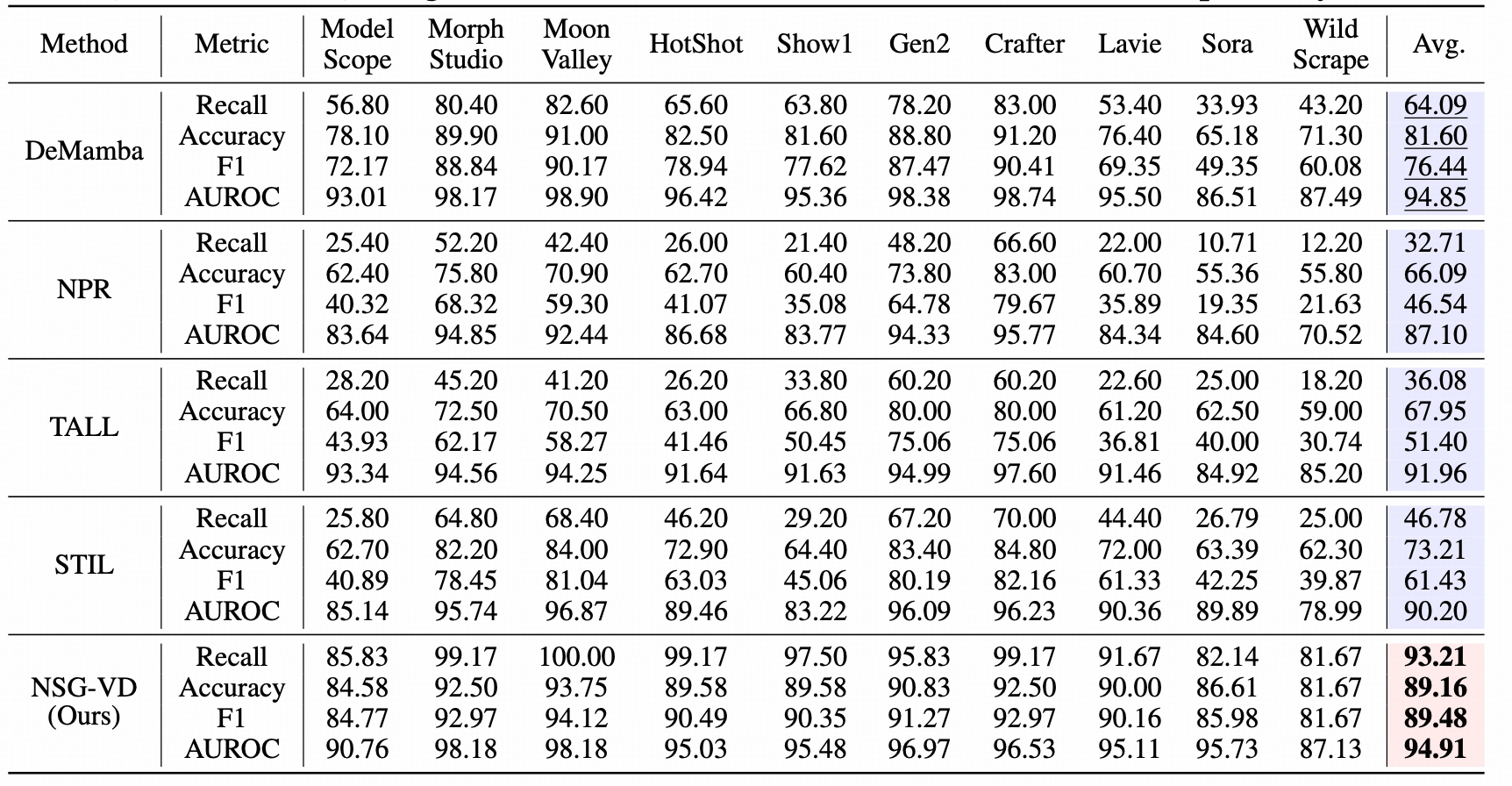
性能再突破:NSG-VD对标闭源生成器
标准对比(同量级真实/合成视频样本数据集训练): 在 Pika生成集 训练的设置下, NSG-VD 的平均Recall为88.02%、F1为90.87%, 明显高于DeMamba、NPR、TALL、STIL等代表方法 ;尤其在 Sora这类闭源强模型上 , NSG-VD的Recall78.57% ,而DeMamba的 Recall 仅48.21%。
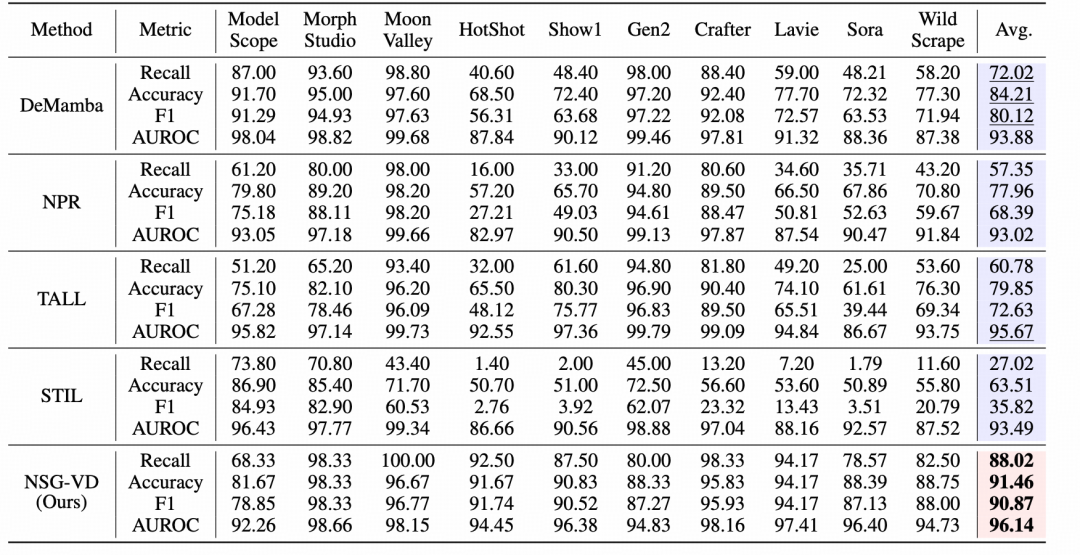
将训练来源更换为 SEINE生成集训练时 ,NSG-VD在多个合成源上的Recall都 接近“满分线”(如MoonValley、HotShot、Show1均≥98.33%),对Sora生成Recall高达94.64%,远超DeMamba的42.86%。
数据不平衡(真实多、合成少)实验: 只给 1/10 的合成样本(1k伪视频数据 vs 10k真视频数据)训练模型时, 多数传统方 法明显“失稳”。 在 Sora生成的视频 上Recall往往跌到 10%–33%区间 ;而 NSG-VD方法的Recall仍能达到82.14% ,并在 WildScrape 等新范式上 保持 80%+ 水准。
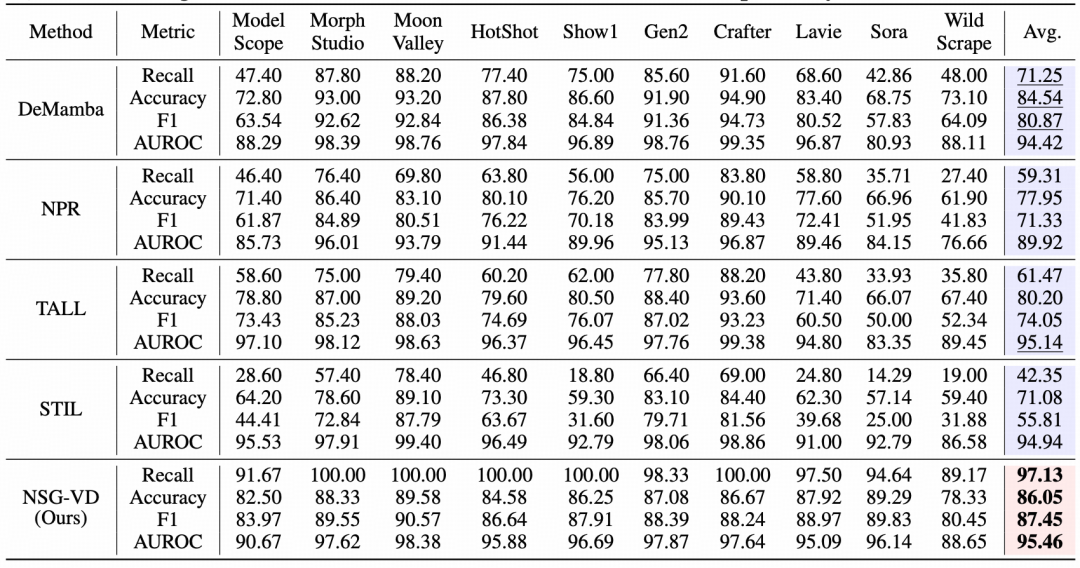
在 Sora等强闭源的生成器上 , NSG-VD的Recall和F1都整体领先大多数方法,且在样本不平衡时仍然表现稳定。
下方给出几组可视化示例,用于直观对比各方法在外观相近的视频上 对 时空不一致的检出差异 。

- 一 句话总结:在相同评测设置下,NSG-VD在 Sora 等闭源生成器上的 Recall/F1整体更高 ;相对部分对照方法,Recall约+16%,F1约+10.75%。 消融实验表明,物理一致性驱动的时空耦合是主要贡献来源。
以 物理一 致性 为判据:守住数字媒体的 “真实性底线”
这项工作将概率流守恒引入视频真实性检测中,构建能反映时空一致性的NSG特征,并用MMD将一致性差异量化为可检验的统计量。结果显示,该路径在多源数据与不平衡样本下表现稳定,具备工程化潜力。
当前文本到视频模型(包括Sora2)主要通过大规模视频数据学习统计相关性与时间一致性,并不显式求解物理方程或进行因果建模(如力-场约束、接触/碰撞刚性、守恒律求解等)。因此,模型可以逼真地复现现象,但在缺乏明确物理先验与实体约束时,仍出现不符合物理演化的细微不一致。这正是NSG-VD利用的信号:当视频的时空演化偏离物理一致性时,检测器能够更稳定地给出判定。
当前阶段,NSG-VD提供了一条可操作的鉴定视频真伪的方向:以物理一致性作为判据,对视频内容做与生成器无关的独立校验。相较传统依赖记忆伪迹的方法,这一路径可解释、可迁移,适合在多源数据与不平衡样本下使用。
AMiner 全功能已接入智谱旗舰模型 GLM-4.6 , 写论文、查文献、做综述的「超强大脑」进一步升级!
我们再次突破模型边界
- 综合能力国内第一: 在 8大权威基准 :AIME25、GPQA、LiveCodeBench v6、HLE、BrowseComp、SWE-bench Verified、Terminal-Bench、τ²-Bench模型通用能力的评估中, GLM-4.6在部分榜单表现对齐Claude Sonnet4/Claude Sonnet4.5 , 稳居国产模型首位。
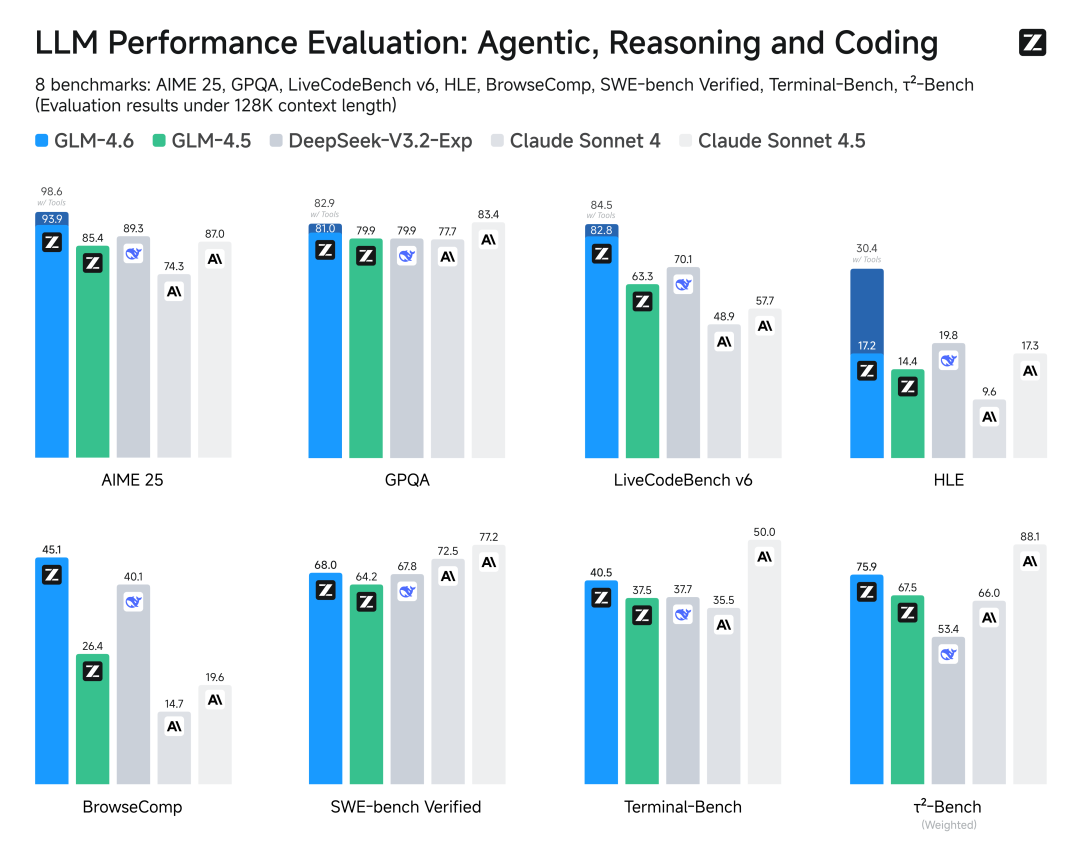
- 上下文窗口扩至200K :相当于能 一次性「读」完 2.7本《时间简史》 ,用 AMiner
AI阅读助手处理超长学术著作、学术论文阅读更快捷。
- 搜索能力、推理能力、写作能力 在智能框架下均提升表现, AMiner沉思辅助调研更全面

赶快试试在AMiner沉思输入 “AI 生成视频检测最新研究进展”,看看科研人如何打假Sora2。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









