





你有没有遇过这种情况? 刷烹饪视频, 传统多模态AI模型 能把锅铲翻飞的翻炒动作看得一清二楚,却把“小火慢炖十分钟”的关键提示当成背景音……
这并非AI的能力短板,而是传统多模态模型受限于模态割裂式架构设计。 它们或专攻视觉解析,或聚焦音频处理,难以实现图像、视频、音频、文本等多感知维度的语义与时间双维度融合。
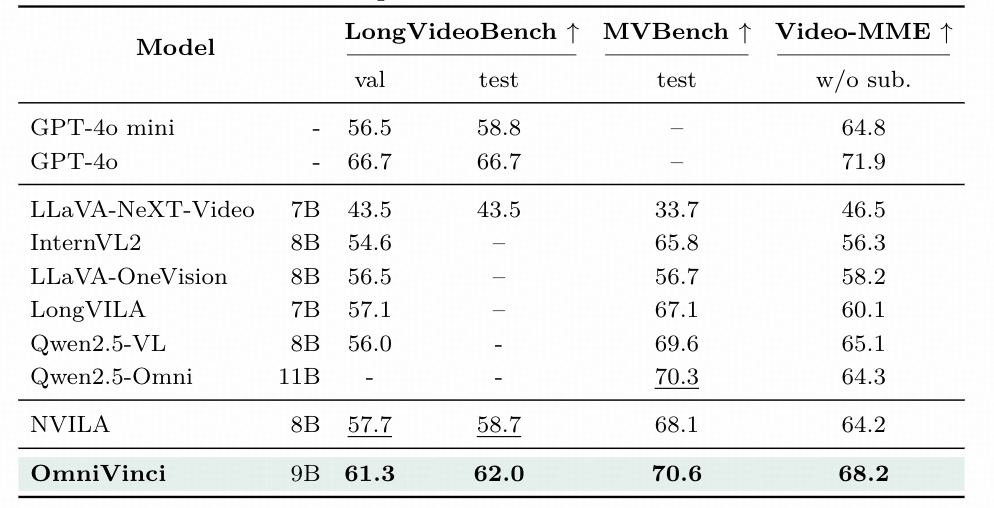
近日,NVIDIA团队推出全模态大模型OmniVinci,通过架构革新与数据优化的协同策略,系统性解决上述问题。 在跨模态基准测试中,OmniVinci超越Qwen2.5-Omni,DailyOmni评分提升19.05个百分点;训练数据量从1.2TB降至0.2TB,成本仅为原方案的1/6;且已在医疗CT影像解读、半导体器件检测等专业领域实现应用。
接下来我们用AMiner AI阅读助手解构一下该模型的技术优势。

1.架构创新:破解跨模态对齐难题
当前多模态人工智能研究面临两大核心挑战:一是模态融合的碎片化倾向 ,多数模型集中于视觉、音频等单一模态的优化,难以实现图像、视频、音频、文本四大模态的系统化融合,导致跨模态理解过程中的语义割裂; 二是训练效能不足 ,主流全模态模型如Qwen2.5-Omni需依赖1.2万亿训练tokens维持性能, 高昂的算力与数据成本制约了技术应用。
针对上述问题, OmniVinci通过三项核心架构创新,构建了四大模态间的融合机制 ,使其从独立处理转向协同运作。
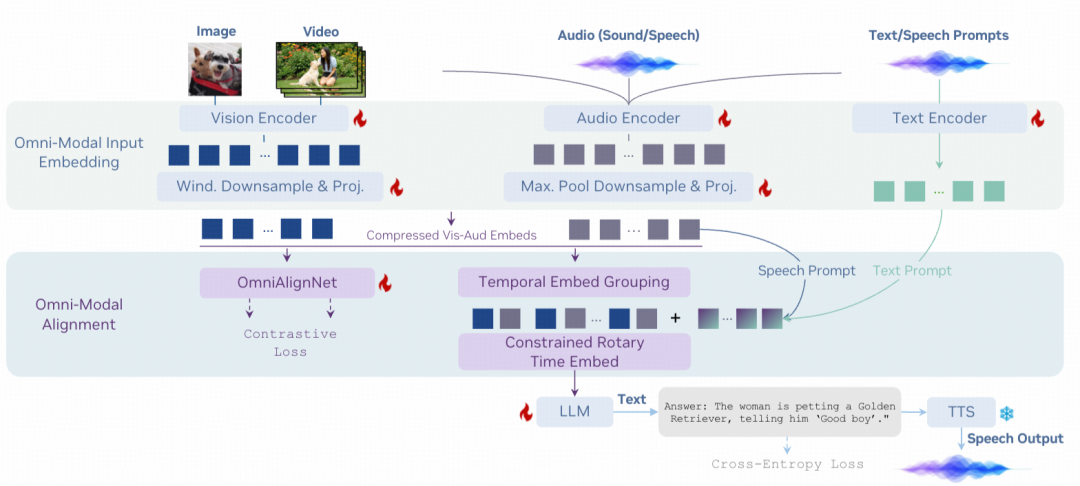
(1).OmniAlignNet: 跨模态语义统一映射机制
OmniAlignNet的 核心目标是实现跨模态语义对齐 ,具体通过“投影映射”与“对比学习”双阶段完成。
- 投影映射阶段: 将图像(通过SigLip编码器)、音频(通过AF-Whisper编码器)、文本(通过LLaMA编码器)的特征,分别通过专属投影层转换为维度一致的全模态向量,确保不同模态数据处于同一可比较的空间 。
- 对比学习阶段: 采用CLIP风格的对比损失函数,使同一场景的多模态向量的余弦相似度最大化 ,同时使 不同场景向量的相似度最小化。
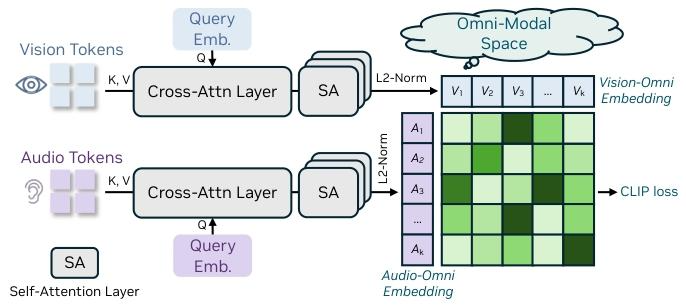
跨模态对齐的 OmniAlignNet 模块
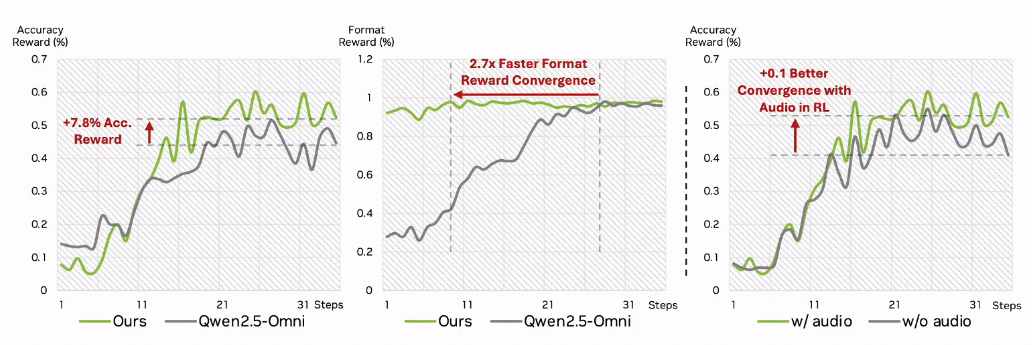
论文实验表明,该模块使跨模态理解基准DailyOmni的准确率提升12.28%,有效解决了传统模型模态语义脱节问题。
例如:在“深海探测视频 +‘1200米深度’解说”场景中,模型可准确关联视觉画面与音频信息,输出完整的跨模态描述,而非孤立的单模态结论。
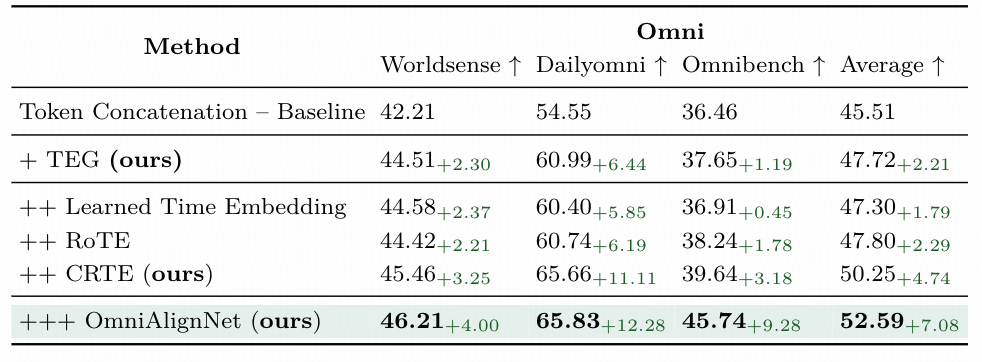
(2).Temporal Embedding Grouping:长时间信息有序化处理方法
视频、音频等时序模态的理解难点在于长时序信息的时序逻辑紊乱。 传统模型直接拼接15分钟以上的长时序帧/段,易引发时序逻辑颠倒。OmniVinci提出的Temporal Embedding Grouping( TEG)模块,通过时间粒度划分与有序聚合实现时序规整。
- 时间粒度设定 : 实验中以30秒为基准时间窗口 ,可依据任务场景进行适应性调整(工业监控场景调整为10秒/组);
- 分组与串联: 按时间戳将视频帧(16帧/秒)、音频段(16kHz采样率) 分配至对应时间窗口组,每组内生成时序子嵌入 ,再按时间顺序将各组子嵌入聚合为有序时序序列。
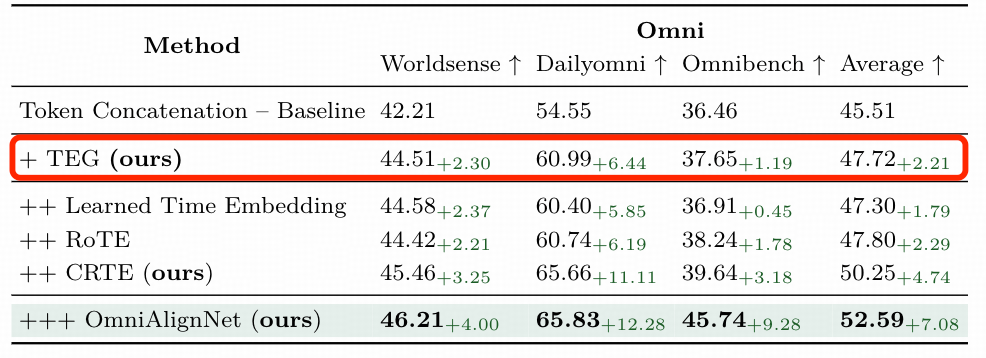
TEG 的有效性
(3).Constrained Rotary Time Embedding(CRTE):实现精准时序标记
TEG解决了时序的相对顺序问题,而CRTE聚焦绝对时间信息表征 ,通过维度敏感的旋转编码实现时间戳精准标记:
- 低维度编码(前128维): 采用高频旋转参数,对秒级时间差进行高分辨率表征,可区分第10秒与第11秒的音频频谱变化及视频帧内容差异;
- 高维度编码(后384维): 采用低频旋转参数,捕捉分钟级时间趋势(0-5min视频画面整体变化),避免长时序场景下的全局信息丢失。
CRTE带来Video-MNE +3.9%提升
与传统Rotary Time Embedding(RoTE)相比, CRTE在无字幕视频理解基准Video-MME上的得分提升3.9;即使在“音频-视频延迟1秒”的复杂场景中**, 仍能保持92%以上的时序对齐准确率,显著优于RoTE的78%。**
2.训练优化:数据质量优化高效训练机制
OmniVinci 不依赖于大规模数据量驱动,而是依托数据质量优化与模态协同学习相结合的策略 ,在2400万样本、0.2T的tokens条件下实现性能显著提升。
(1). 双路径协同修正机制:模态幻觉抑制策略
传统多模态数据易因视觉信息与音频信息的不当关联产生模态幻觉现象,如仅依据海浪图视觉信息便误判对应音频为雨声。 OmniVinci采用隐式路径与显式路径相结合的修正机制。

- 隐式路径 :利用公开视频问答数据集(如MSRVTT),使模型在自然场景中自主学习模态关联关系(如手术画面与医生解说的对应)。
- 显式路径: 先由单模态模型生成单模态描述 (视觉模型生成“蓝色机器人”、音频模型生成“启动声”), 再经大语言模型融合为全模态描述 (“蓝色探测机器人启动,伴随任务提示音”)。
双路径结合后,模态幻觉发生率降低68%,为模型学习精准模态关联奠定了数据基础。
(2). 分配层级化训练数据配比策略:2400万样本的能力导向分配
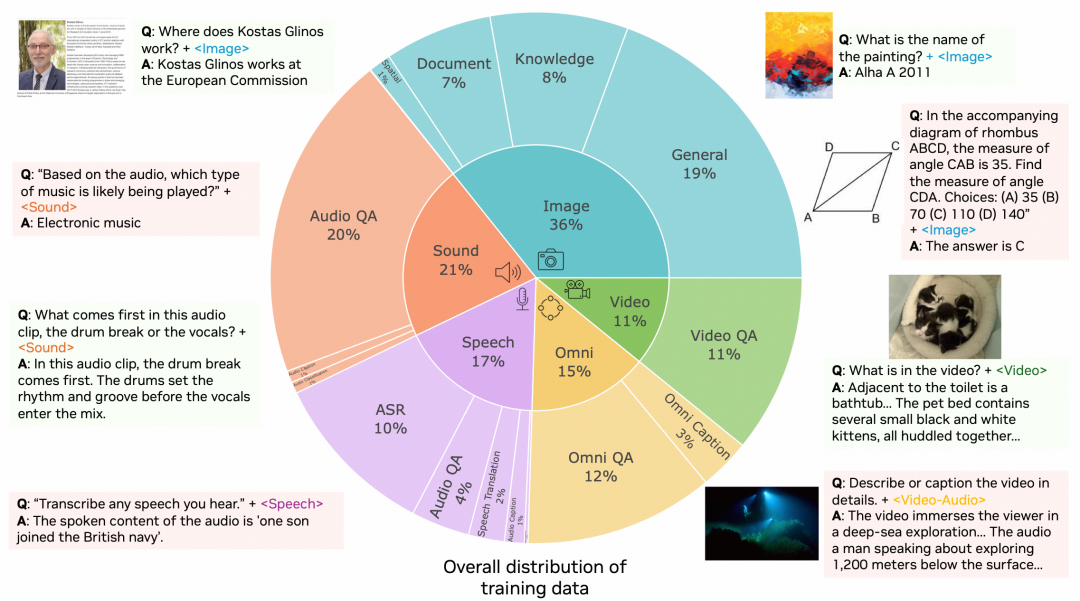
OmniVinci模型训练使用的 2400万训练样本的分配遵循“基础、专项、协同” 的能力层级体系,并非随机配置。
- 基础视觉能力(占比36%,计864万条): 涵盖图像分类、文档识别等任务,旨在提升视觉特征提取的基础能力;
- 专项音频能力(占比38%,计912万条): 包含语音指令、环境声、音乐分类等音频语义理解任务,强化音频模态的专业处理能力;
- 模态协同能力(占比15%,计360万条): 聚焦“视频+音频+文本”三模态对齐等跨模态融合任务,针对性训练模态间的协同机制。
该配比保障了模型能力的均衡性。 音频能力提升后,视频-音频跨模态任务的准确率提高2.09%;视觉基础强化后,图像-文本问答任务的得分提升8%,最终支撑模型在多项基准测试中实现全面超越。
3.性能验证:多维度基准测试与推理效率优化
从三个维度验证了 OmniVinci 的性能优势,且所有测试均在统一硬件(8×RTX 4090 GPU)与评估框架(OpenCompass-Multimodal)下完成,确保公平性。
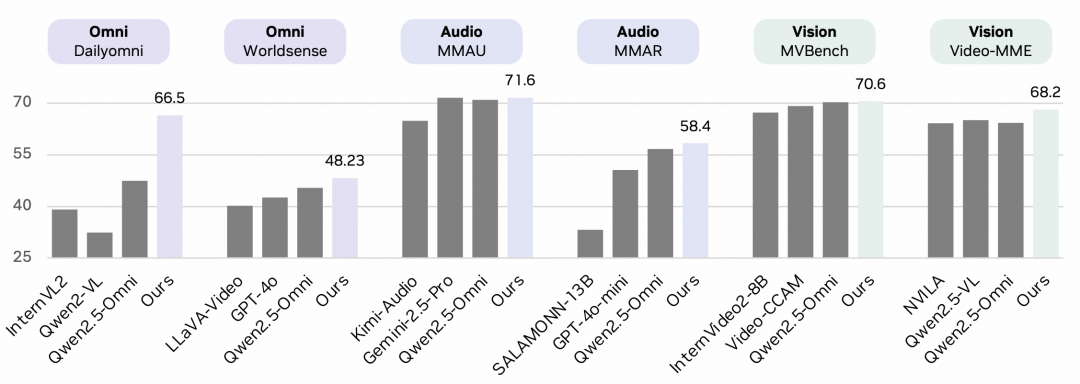
(1).全模态理解:Dailyomni基准提升19.05
**Dailyomni 作为跨模态语义对齐的核心基准 ,**涵盖视觉与音频关联、多模态场景描述等任务。在对比实验中,OmniVinci得分66.5,较Qwen2.5-Omni(47.45)提升19.05个百分点。在动态场景跨模态描述子任务中,准确率达 72.3%(Qwen2.5-Omni仅51.8%),证明其能有效融合多模态信息。
(2).音频理解:MMAR基准提升1.7
MMAR聚焦音频语义理解任务(如嘈杂环境中提取指令、故障声分类)。 对比实验显示,OmniVinci得分58.4,较Qwen2.5-Omni(56.7)提升1.7个百分点。值得注意的是,OmniVinci未对音频任务专项优化,却在工业设备故障声识别任务中准确率达69.2%,印证了其音频编码器与模态对齐机制的有效性。
(3).视觉理解:Video-MME基准提升3.9
Video-MME(无字幕视频理解基准)评估长视频时序与视觉细节理解(如手术流程排序、物体动态追踪)。 对比实验中,OmniVinci得分68.2,较 Qwen2.5-Omno(64.3)提升3.9个百分点。在长视频因果推理中,准确率达69.1%(传统模型仅62.4%),体现了TEG与CRTE对时序信息的高效处理。

此外,推理效率同步优化:在 RTX4090设备上,OmniVinci首令牌生成时间为 182ms(Qwen2.5-Omni为310ms,提速1.7倍);解码延迟时间为28.3ms/令牌(Qwen2.5-Omni为77.0ms/令牌,降低2.72倍),为工业、医疗等场景的落地扫清了效率障碍。
4.结语:全模态AI实用化拐点
OmniVinci通过对比实验的性能数据与技术架构的呼应,证明全模态模型可跳出数据量竞赛: 以架构革新(模态对齐、时序处理)和数据优化(优质样本、科学配比)为核心,用1/6的训练tokens实现性能反超。
目 前,它已在医疗(CT跨模态分析准确率91.3%)、半导体(晶圆故障定位效率提升40%)等场景验证实用价值。未来,随着模态整合精度与动态适配能力的提升,全模态AI或将更深度融入专业领域,而高效加高性能的研发思路,也为行业从规模驱动转向质量驱动树立了标杆。
AMiner 溯源树更新
若想追溯全模态AI的演进证据链、系统梳理其发展历程,可借助AMiner溯源树完成这一工作。该工具能在三分钟内生成可视化网络,帮助我们快速获取全模态AI的研究背景与相关工作,高效支撑对其发展脉络的梳理。
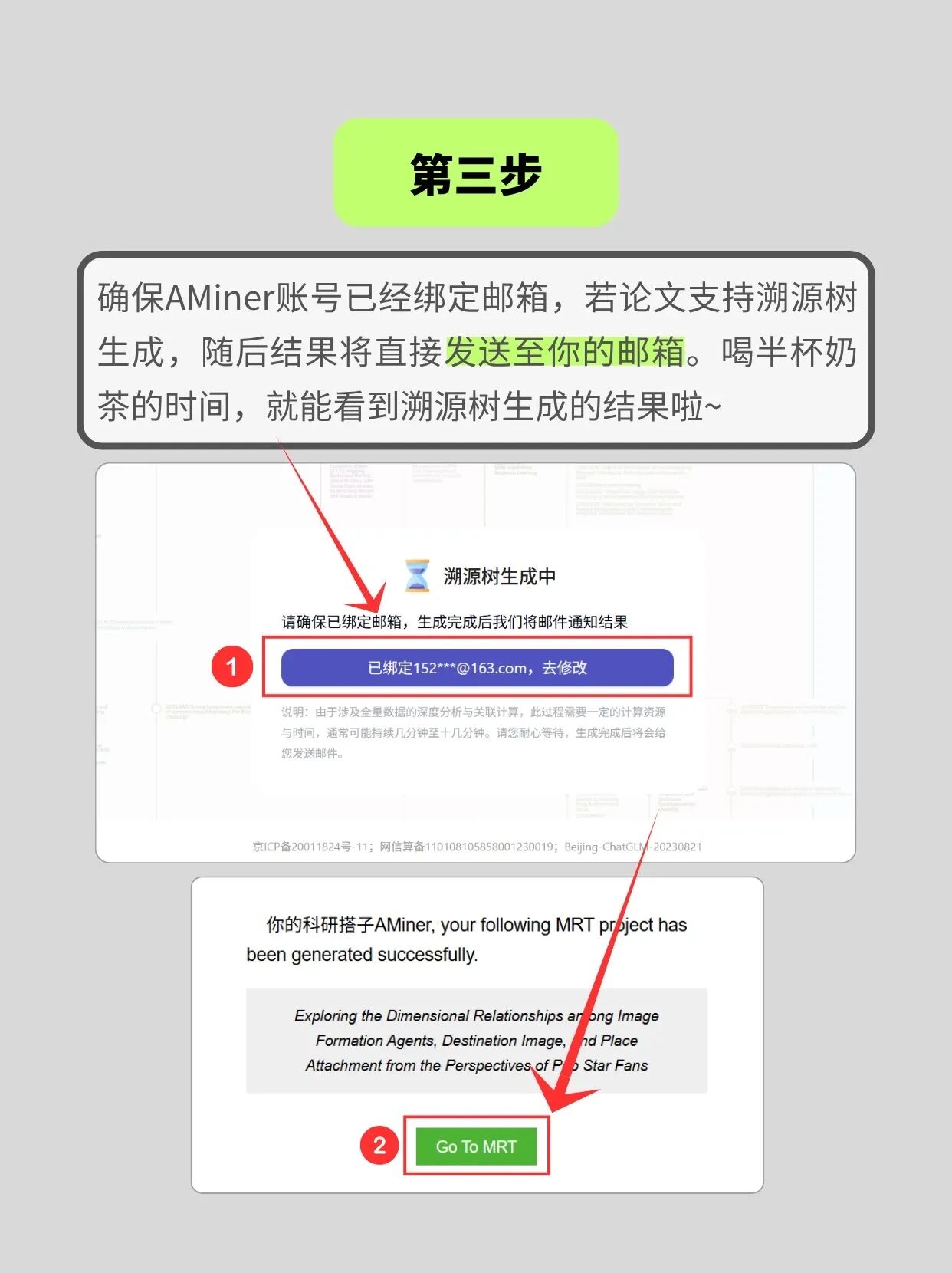
教你三步轻松解锁文献溯源脉络:
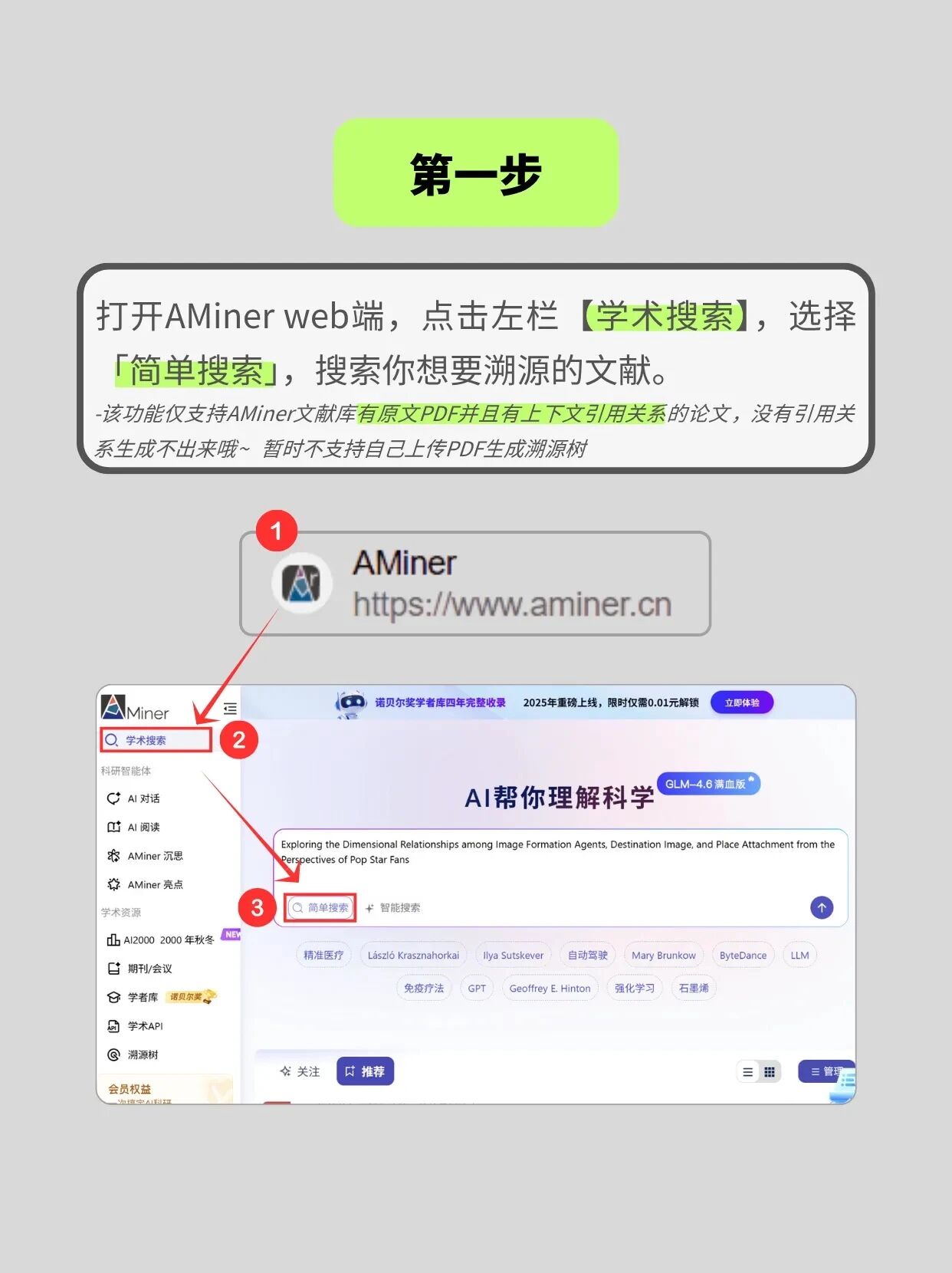
1.打开 AMiner 网页端,在「学术搜索」中定位你需要溯源的目标文献
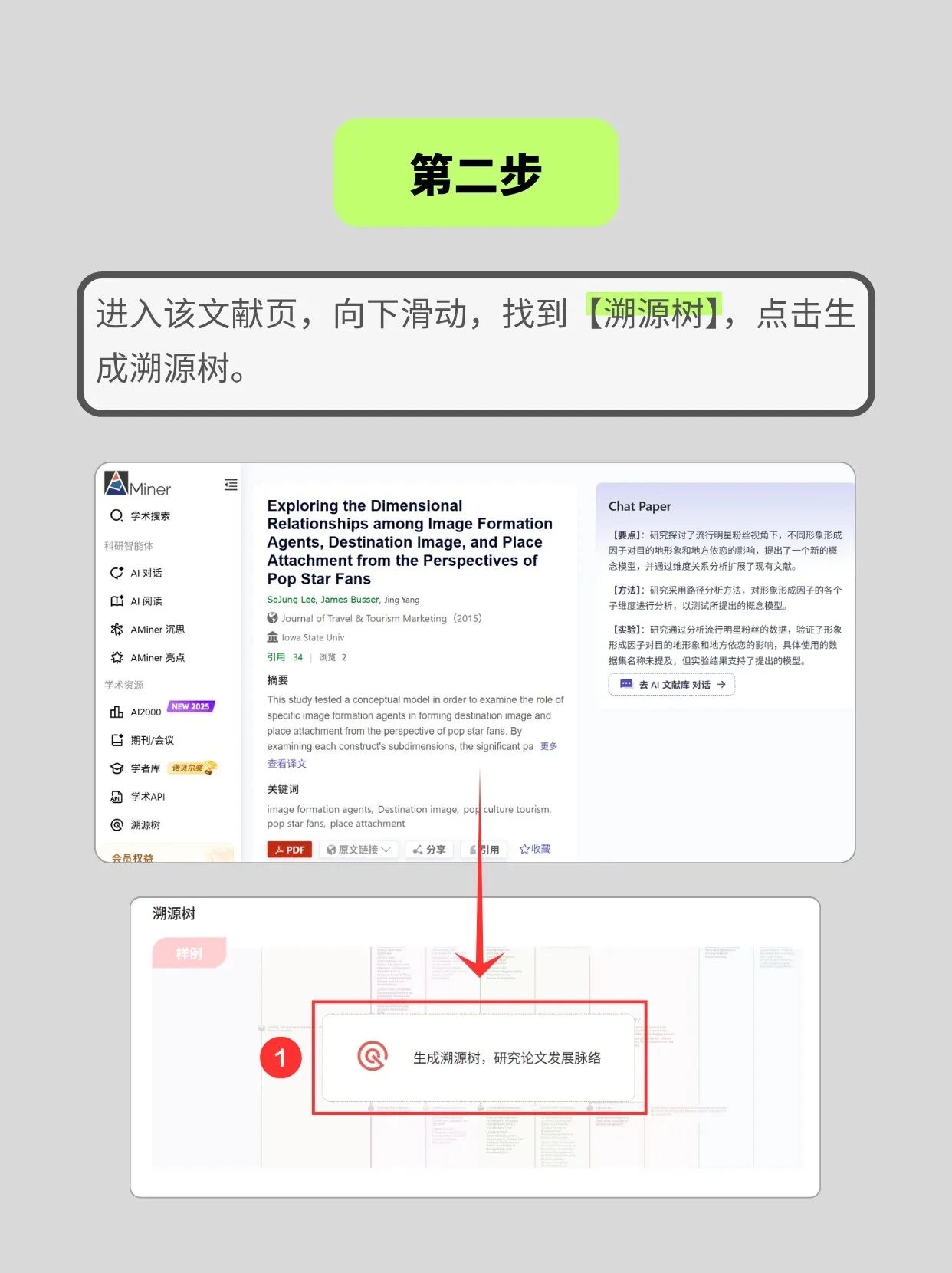
2.进入文献详情页后下滑,找到「溯源树」功能入口并点击生成
3.绑定邮箱,溯源树结果会直接发送到你的邮箱,一键掌握研究脉络
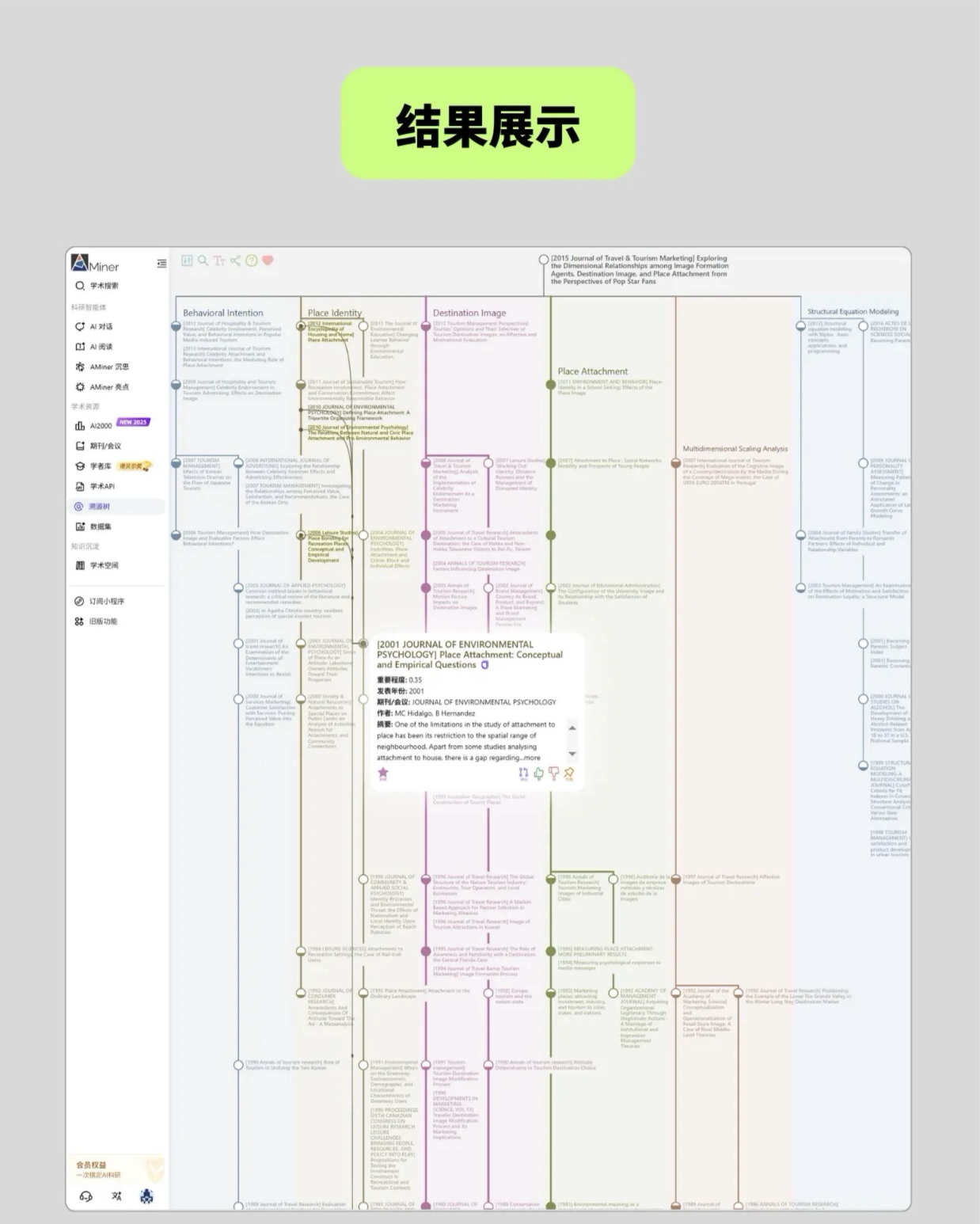
搞懂研究脉络才能站在学术前沿!AMiner「溯源树」把文献引用关系、领域发展脉络 “可视化” 呈现 —— 分支粗细直观体现类别影响力,节点填充展示时期影响力,鼠标悬浮还能高亮关联文献、查看论文贡献度星级(如图中文献节点的填充、星级标识,清晰又直观👇)详细使用说明,请点击关注AMiner AI公众号。
学术溯源树可视化结果


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









