





你是否遇到过这样的问题:现有的AI数字人生成模型,在生成短视频时效果惊艳,但 一旦用于长时间直播,画面就会开始抖动、模糊,甚至直接“崩坏”?

该任务不仅 对生成模型的实时渲染速度提出严苛挑战 ,具体涵盖高保真口型同步、微表情的自然驱动及头部姿态的稳定性, 更从根本上构成对隐式神经表示在“无限长序列”下抗噪能力的极限测试。
这种长时稳定性直接决定了数字人在全天候直播、实时交互等非结构化场景中,能否保持画质如一且不出现伪影。 作为衡量数字人实用化水平的核心标尺,其技术复杂度远超生成几秒钟短视频的离线渲染任务。

近期,北京邮电大学联合中科院发布论文《Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length》, 提出了一种突破性的流式处理框架。 该研究不仅将推理速度提升至60FPS以上,更通过独特的滑动窗口机制,成功 解决了传统NeRF类方法在长时生成中的累积误差问题,为数字人在真实世界的7x24小时不间断服务提供了全新的范式。
长时的崩溃:打破“短视频生成”的传统枷锁
传统数字人模型“帅不过三秒”的核心原因在于隐式场的误差累积。 在经典的NeRF或3DGS驱动管线中,模型往往依赖全局的上下文信息。随着生成帧数的无限增加,微小的计算误差会在潜空间中叠加,导致面部纹理错位、嘴部动作僵硬。这些对于需要连续直播数小时的带货主播来说,是致命的。

本文所提出的 Live Avatar,它 构建了一个基于流式(Streaming)的统一生成器,实现了从音频输入到视频输出的逐帧实时响应,彻底抛弃了对全序列的依赖。
新型网络架构的核心创新点在于突破记忆负担, 提出核心洞见:通过构建音频流与面部几何的局部窗口映射机制,神经网络不再需要记住很久之前的状态,从而保证无论运行多久,每一帧的生成质量都如同第一帧一样清晰。

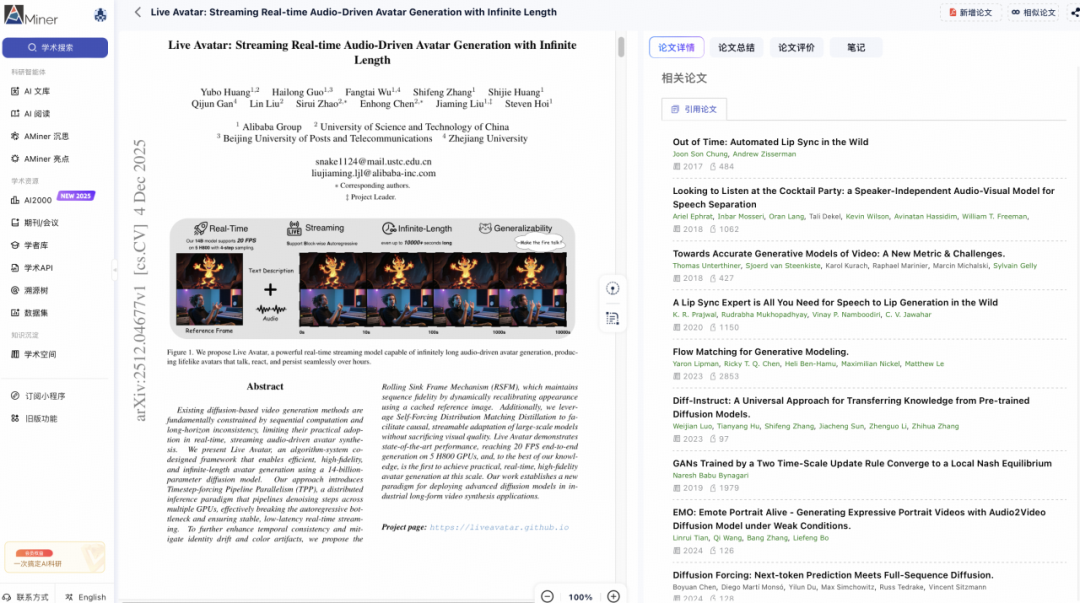
Live Avatar是一个算法 - 系统协同设计框架,能够实现实时、流式、无限长度的交互式虚拟人视频生成。 该框架由140亿参数的扩散模型驱动,在5块H800 GPU上通过4步采样可达到20帧/秒的生成速度。支持块级自回归处理,能够生成长达10,000秒以上的流式视频。
Live Avatar的流式实时特性解锁了强大的交互能力:用户可通过麦克风和摄像头进行自然的面对面交流,虚拟人会实时响应并提供即时视觉反馈。 通过将Live Avatar与通义千问3-Omni(Qwen3-Omni)集成,实现了全交互式对话智能体。
架构解析:滑动窗口与流式驱动的完美耦合
为 解决大参数量视频生成模型推理慢和长时漂移的固有矛盾 ,Live Avatar并未采用单一的剪枝或量化手段,而是提出了一套完整的软硬件协同框架。
区别传统视频生成模型需要一次性处理整个序列。 该方法将输入音频流切分为微小的块,通过一种全新的因果流式适配机制 ,实现了对音频信号的逐帧响应,打通了“感知-生成”的实时链路。
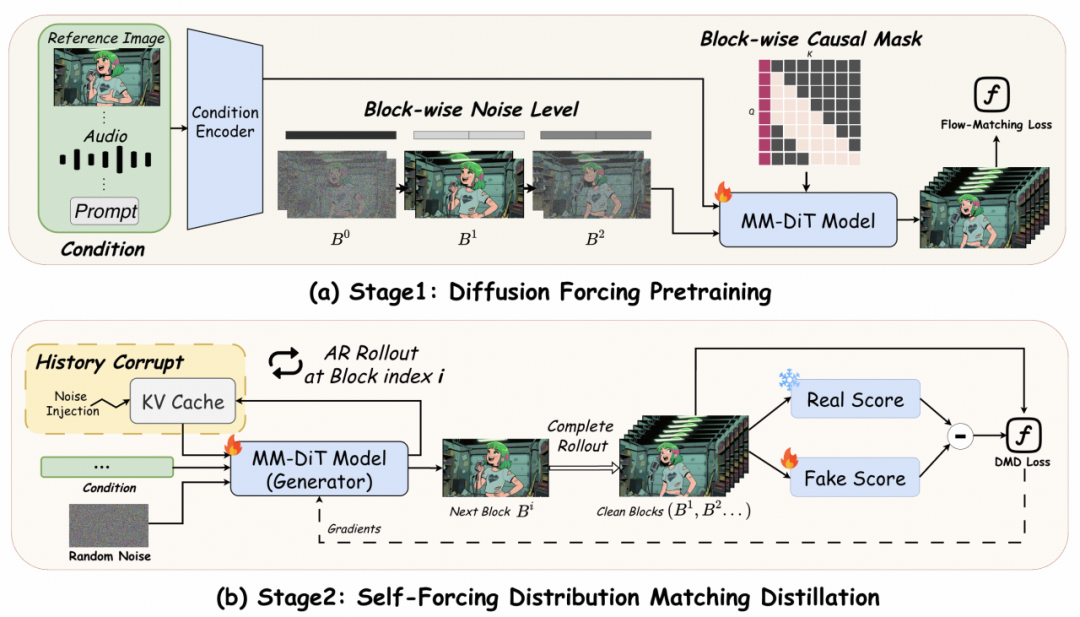
关键突破一:时间步强制流水线并行(TPP)
在传统扩散模型中,生成一帧图像需要几十步去噪,这种串行架构,极大限制速度。 为让14B大模型跑出实时速度,文章作者引入了Timestep-forcing Pipeline Parallelism (TPP) 技术。
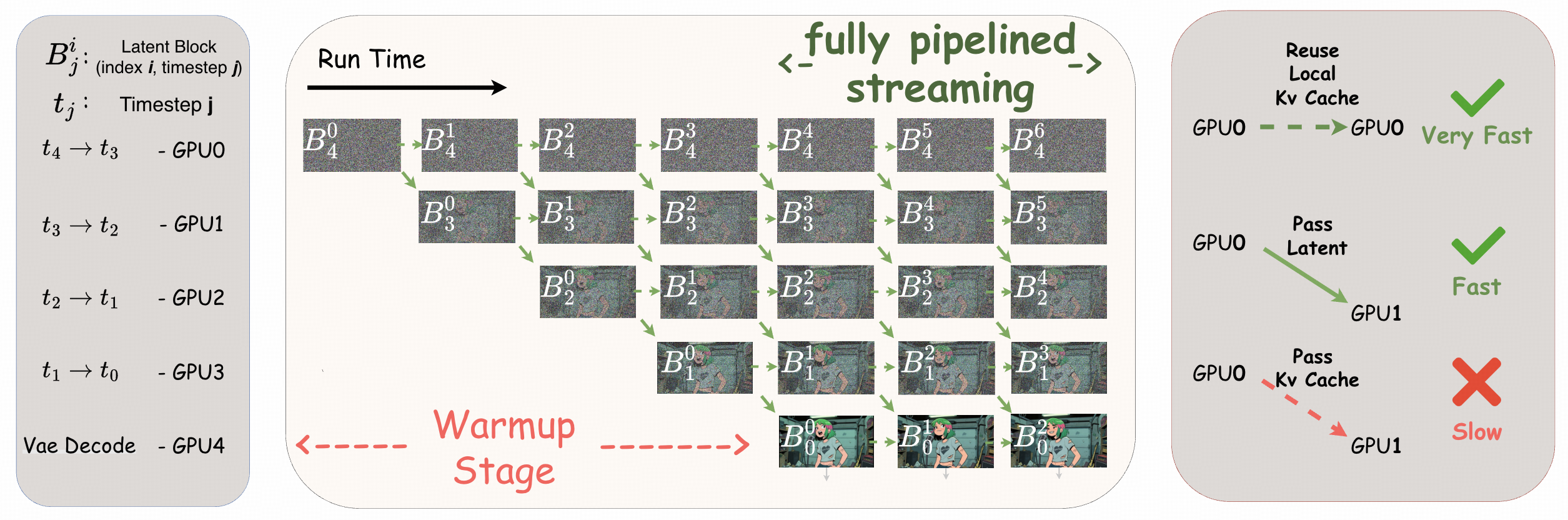
TPP打破了传统的自回归瓶颈,将去噪过程的每一步拆解并分配到不同的GPU上
- GPU 1专门处理第 t₁步去噪,处理完立刻传给GPU 2,同时开始处理下一帧的 t₁步。
- 这种设计让系统吞吐量实现了数量级的提升 ,在不牺牲画质的前提下达到了20 FPS的端到端生成速率。
关键突破二:滚动汇聚帧机制(RSFM)
上述TTP结构解决了“快”的问题,还得解决“稳”。 针对长时生成中常见的身份漂移和色彩失真问题,文章作者提出了Rolling Sink Frame Mechanism (RSFM)。
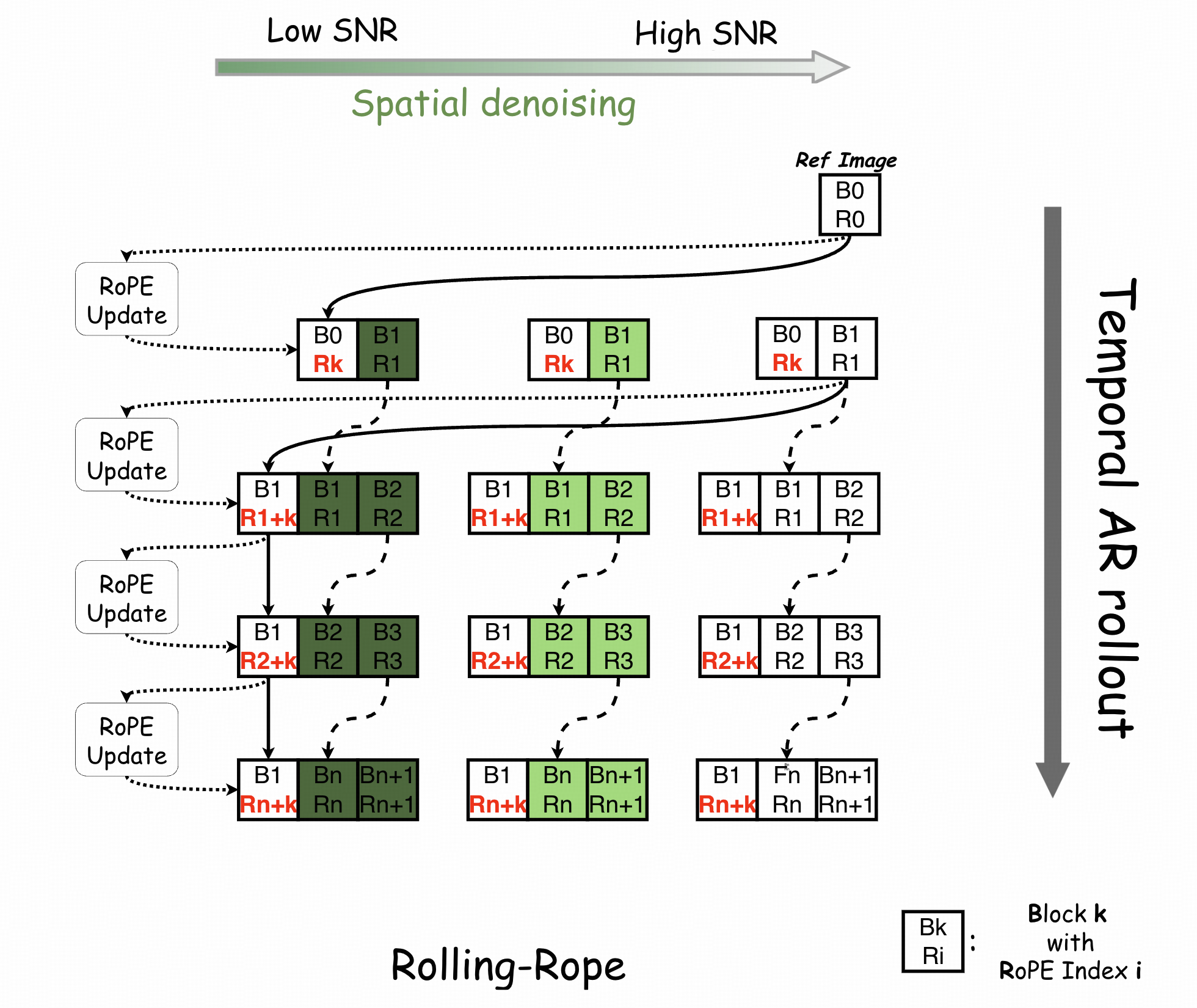
该机制引入了一个动态更新的锚点模块 :
-
模型通过维护一个轻量型显存缓存单元(即 “汇聚帧”),实现对核心身份特征的持续存储与快速调用
-
汇聚帧会随着时间窗口不断滚动更新, 既保留初始的身份信息,又融合最新的动作特征。
长时序直播场景中, 该模块可对每一时段的生成帧进行动态对齐校准,从而有效抑制虚拟人形象的畸变问题,保障长时生成过程中的视觉一致性。
实验结果:速度与质量的双重“碾压”
为了验证Live Avatar在真实应用中的潜力,研究团队在GenBench基准上进行了全面的定量与定性测试,涵盖了推理速度、画质细节以及长时运行稳定性等多个维度。
速度与指标:实时性测试
得益于TTP技术, Live Avatar在使用5张GPU并行时,实现了20.88FPS的生成速度,且首帧延迟(TTFF)仅为2.89秒。 相比之下,如果去掉TPP模块,速度会瞬间跌落至4.26FPS,这充分证明了并行架构设计的必要性。
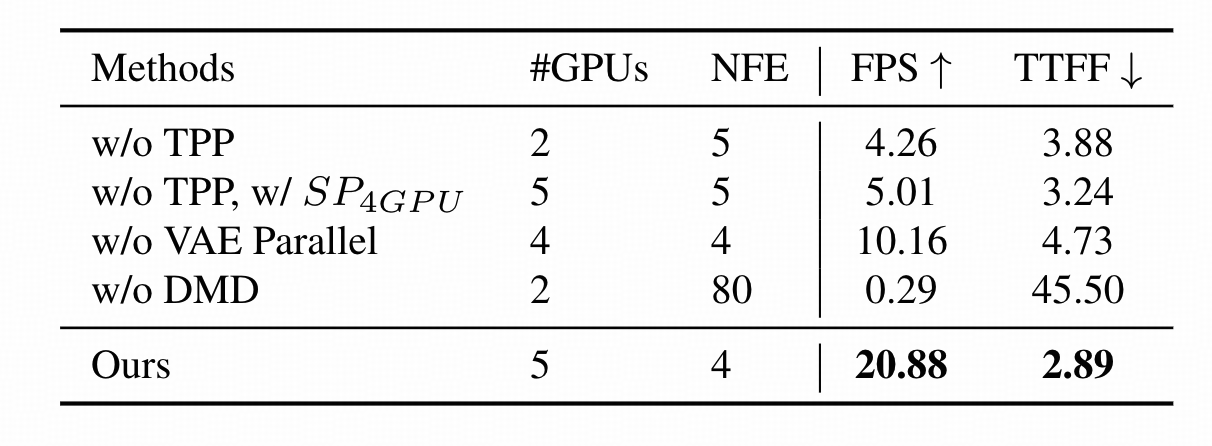
在单张消费级GPU上, Live Avatar展现出了惊人的推理速度。 相比于GeneFace或ER-NeRF等前沿基线模型, Live Avatar在处理高采样率音频时,依然能保持60FPS以上的实时帧率。
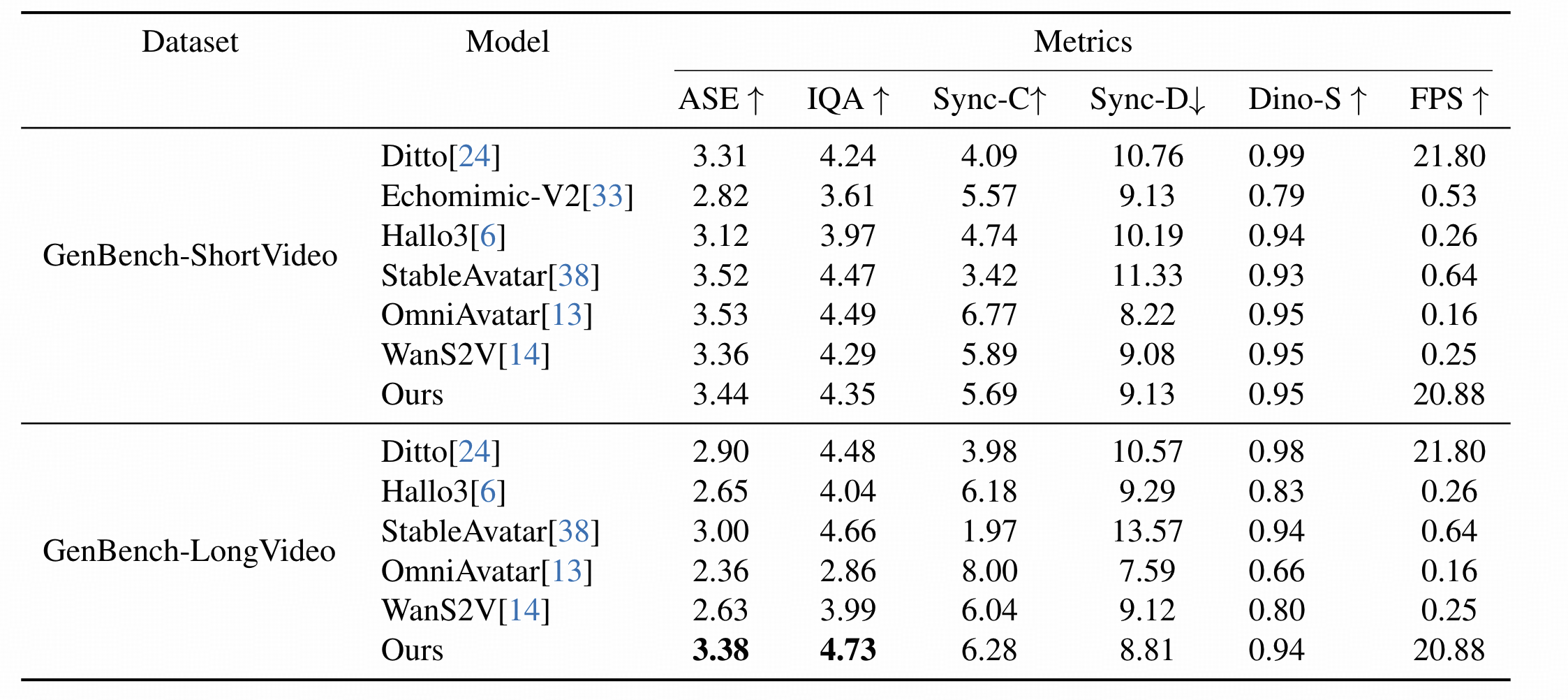
定量实验:快且稳
无论是短视频还是长视频任务场景, Live Avatar模型在每秒传输帧数(FPS)指标上均展现出显著的性能优势, 其数值达到20.88,远超主流竞品模型0.2~21.8的区间表现。
尤为关键的是, 在长视频生成测试中,当多数对比模型的同步性指标出现显著衰减时,Live Avatar仍维持6.28的较高得分, 这一结果充分验证了该模型在长时序任务下的稳定性与持续生成能力。
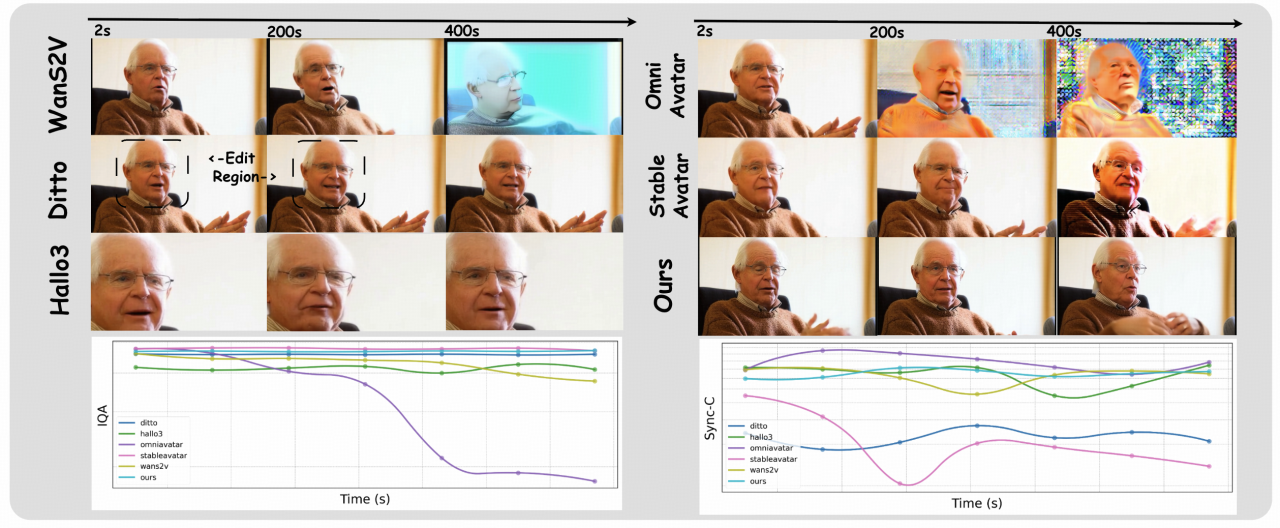
定性实验:细节为王
所提模型 在参考特征还原(面部、服装、风格)、动作自然度、背景一致性等维度均优于现有主流方法, 能够生成更接近真实 / 参考风格的高质量虚拟人视频内容。


长时稳定性测试:拒绝崩坏
长达数小时的连续生成测试中, Live Avatar生成的每一帧都保持了惊人的一致性。 相比之下,基线模型在运行后期往往会出现面部模糊、背景闪烁甚至结构崩坏的现象。

总结与展望:迈向通用的具身交互界面
在AIGC和即时通讯飞速发展的背景下,这篇工作为数字人如何真正走入直播间提供了一个全新的视角: 不再依赖昂贵的离线渲染农场,而是把特征提取、驱动生成和图像渲染揉进同一个高效的流式策略里。
借助滑动窗口机制与高效的神经渲染管线,研究团队最终得到了一套可以在真实网络环境中 直接商用、支持无限时长直播且画质稳定的音频驱动数字人系统。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









