






AMiner平台(https://www.aminer.cn)由清华大学计算机系研发,拥有我国完全自主知识产权。平台包含了超过2.3亿学术论文/专利和1.36亿学者的科技图谱,提供学者评价、专家发现、智能指派、学术地图等科技情报专业化服务。系统2006年上线,吸引了全球220个国家/地区1000多万独立IP访问,数据下载量230万次,年度访问量超过1100万,成为学术搜索和社会网络挖掘研究的重要数据和实验平台。
IJCAI 2020 论文推荐
Rewriting the Description Logic ALCHIQ to Disjunctive Existential Rules
特别是在数据密集型环境中,描述逻辑(DL)的一种有前途的推理方法是将DL理论重写为规则集。 尽管在文献中已经考虑了许多这样的方法,但是仍然存在各种相关的DL,对于这些DL来说,很小的重写(多项式大小)是未知的。
作者为DL ALCHIQ开发了小的重写-以析取、数字限制和反作用为特征-来分离析取数据记录。 通过在规则标题中接纳量词,作者可以改善此结果,以仅生成有限大小的规则,这是迄今为止在实践中实现的所有重写的共有属性。
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef27720d3?conf=ijcai2020
会议链接:https://www.aminer.cn/conf/ijcai2020

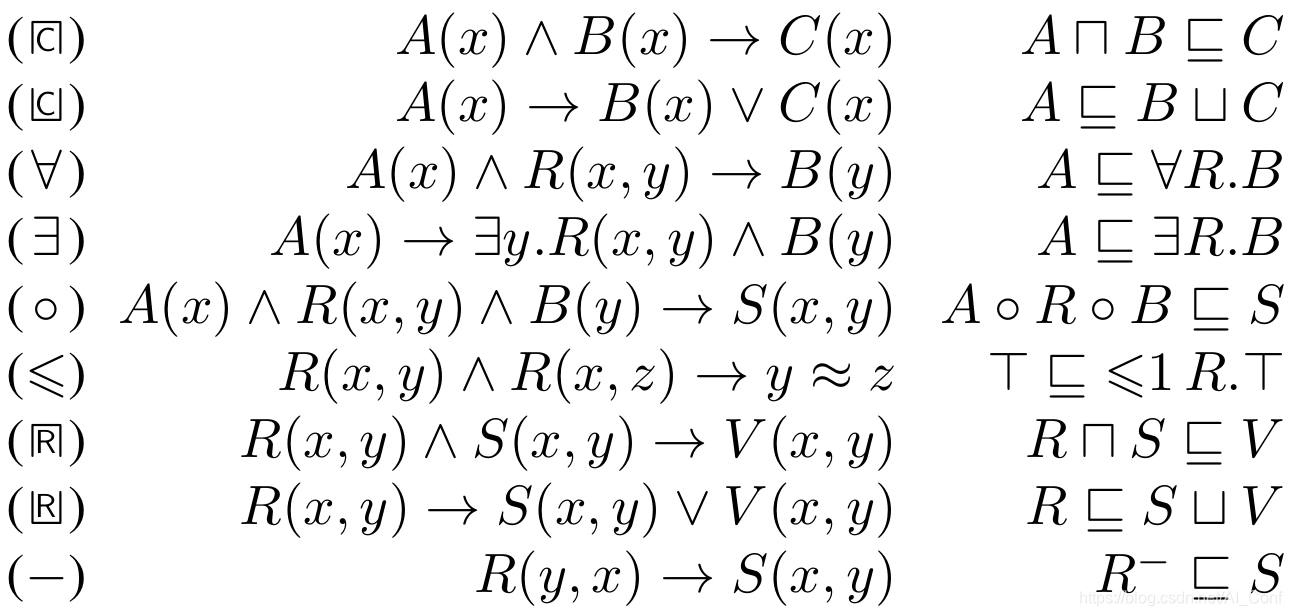


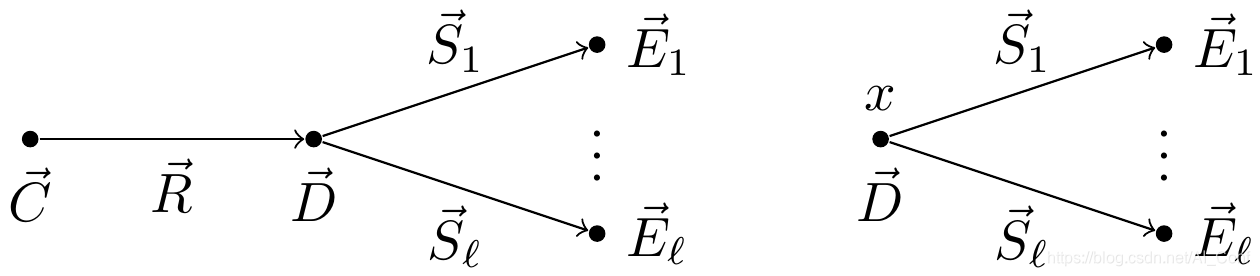
Concurrent Games in Dynamic Epistemic Logic
动态认知逻辑(DEL)的动作模型精确地表示了代理如何感知动作。DEL最近已用于定义无限多玩家游戏,并且表明它们在某些情况下可以被解决。 然而,动态是由经典的DEL更新产品定义的单个行动,到目前为止,只有回合制游戏被考虑。
在这项工作中,作者定义了一个并发的DEL产品,提出了解决动作之间冲突的机制,并定义了并发DEL游戏。 与基于回合的情况一样,当所有动作公开或全部为命题时,可以有限地表示所获得的并发无限游戏场所。因此,作者确定了可以在此类游戏上对战略认知逻辑ATL * K进行模型检查的情况。
论文链接:https://www.aminer.cn/pub/5ef96b048806af6ef27720b6?conf=ijcai2020
会议链接:https://www.aminer.cn/conf/ijcai2020
NeurIPS 2020 论文推荐
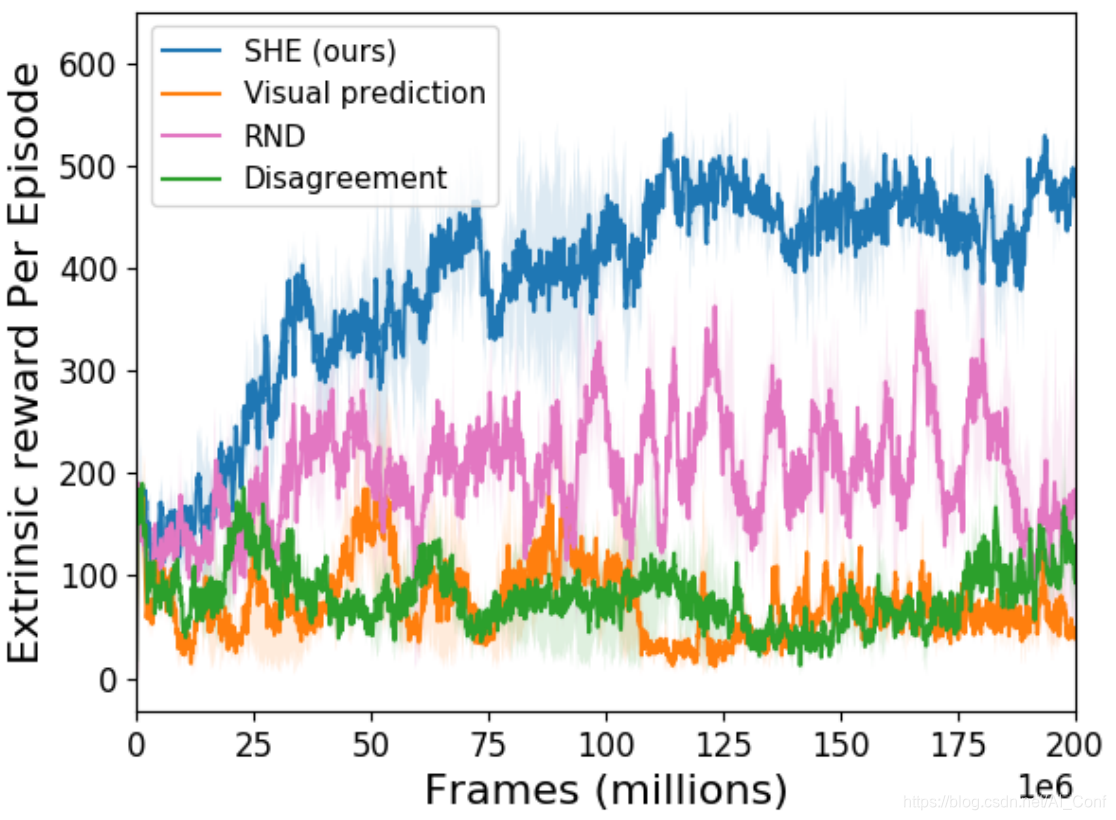
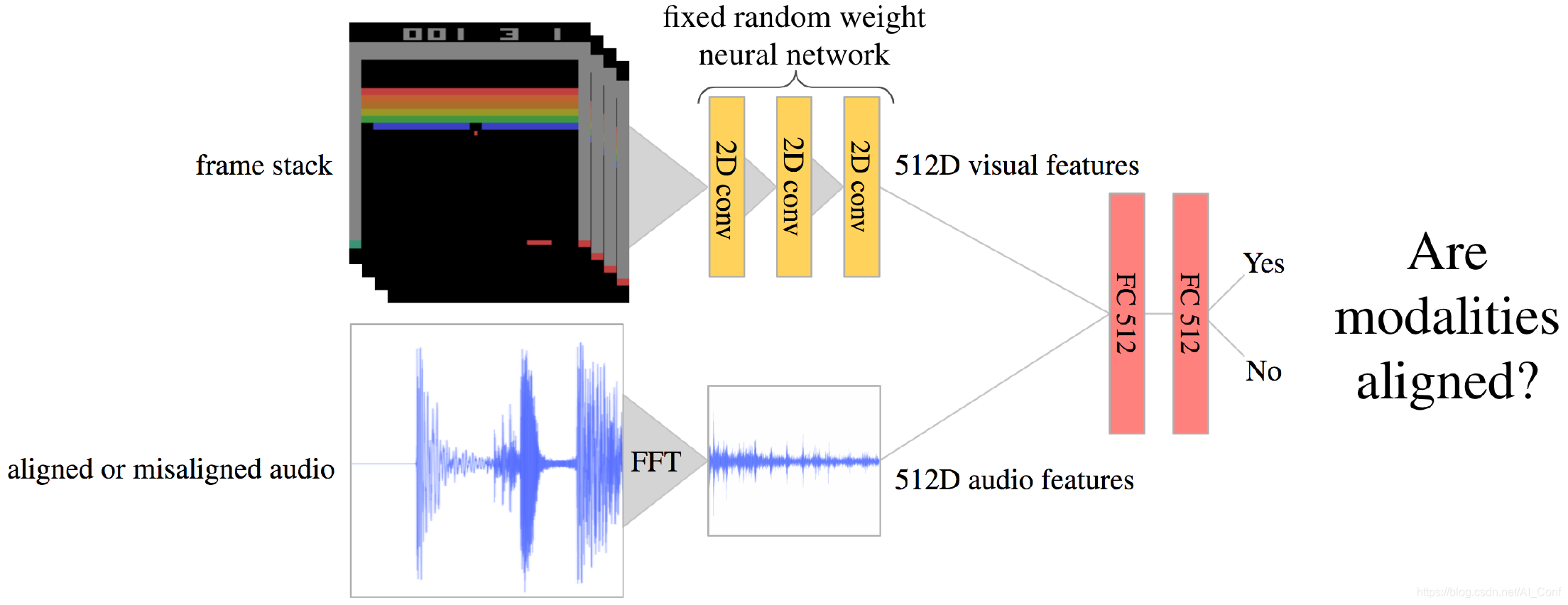
See, Hear, Explore: Curiosity via Audio-Visual Association
探索是强化学习中的核心挑战之一。好奇心驱动的探索的一种通用表述利用了真实未来与学习模型预测的未来之间的差异。但是,预测未来是一项固有的艰巨任务,面对随机性可能会出现问题。
在本文中,作者引入了另一种形式的好奇心,奖励不同感官之间的新型关联。作者的方法利用多种模式为更有效的探索提供了更强的信号。作者的方法受到以下事实的启发:对于人类来说,视觉和声音在探索中都起着至关重要的作用。
作者展示了几种Atari环境和Habitat环境(照片般逼真的导航模拟器)的结果,显示了在没有外部奖励的情况下,使用视听关联模型对学习代理进行内在引导的好处。
论文链接:https://www.aminer.cn/pub/5f05a52391e011c57e3e8ea1?conf=neurips2020
会议链接:https://www.aminer.cn/conf/neurips2020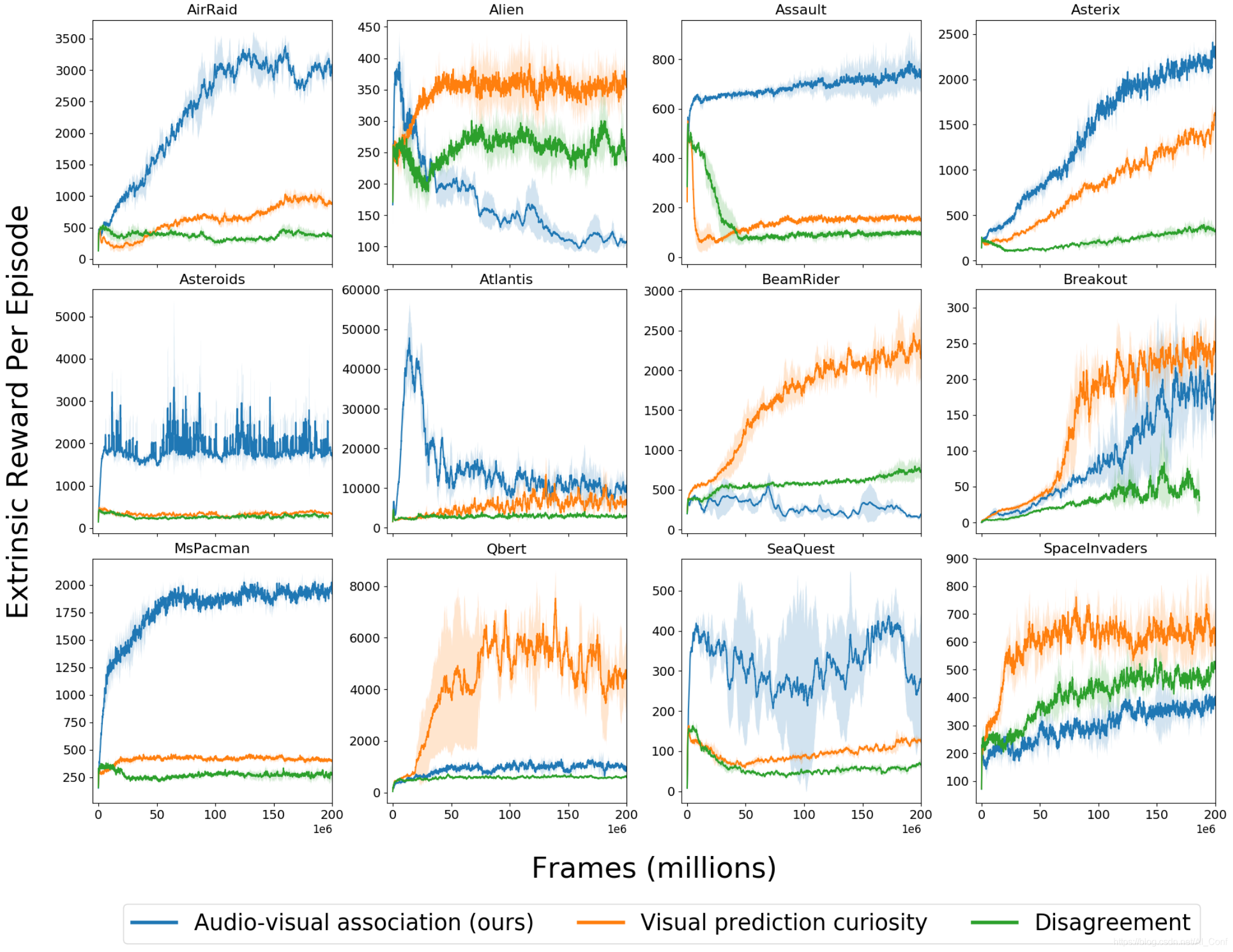
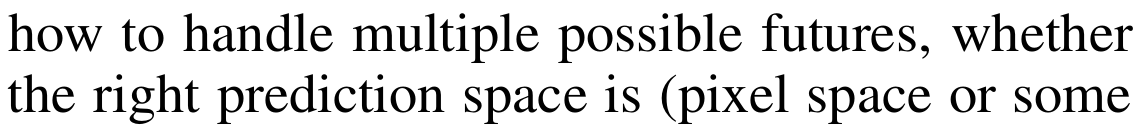
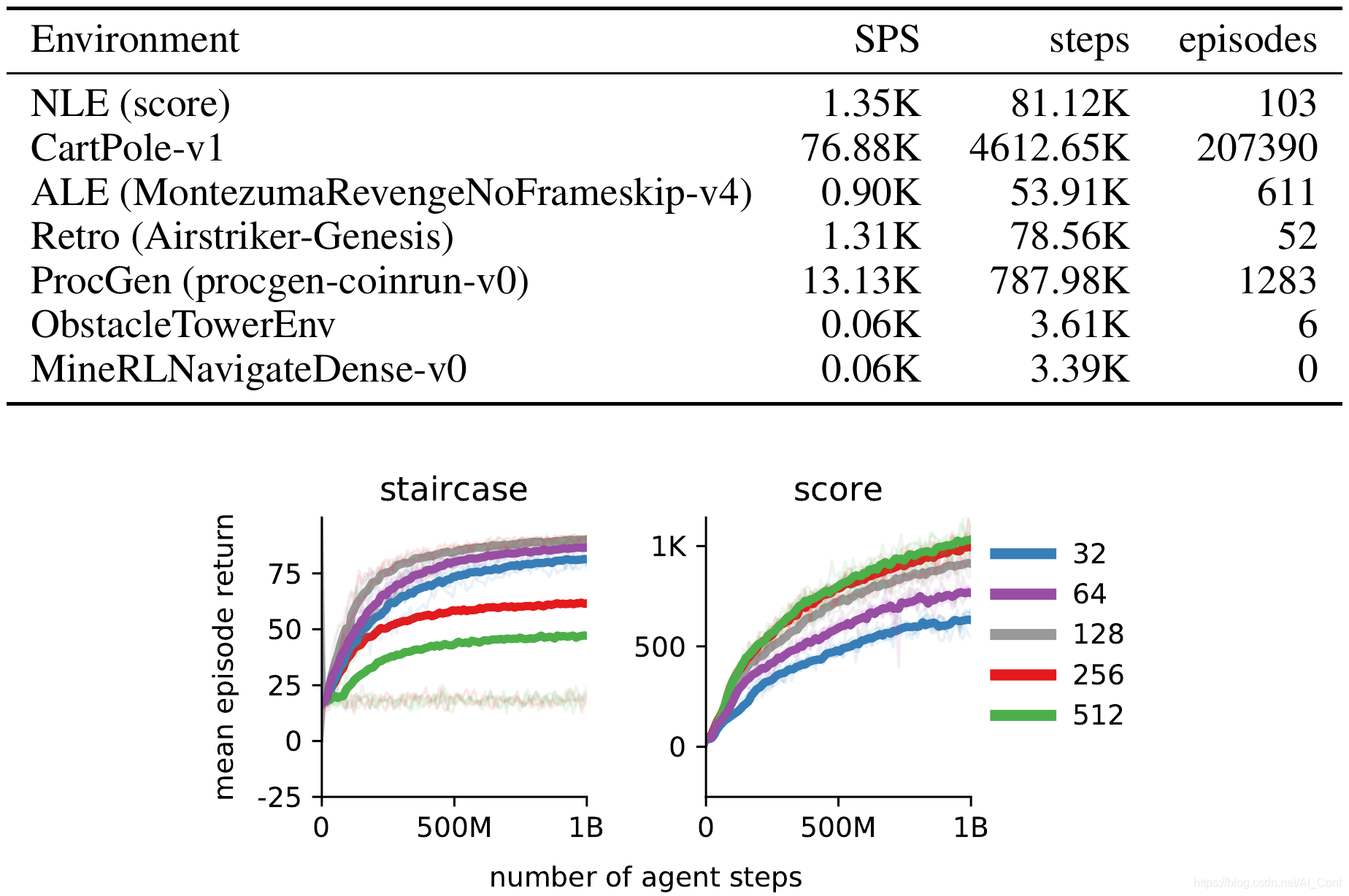
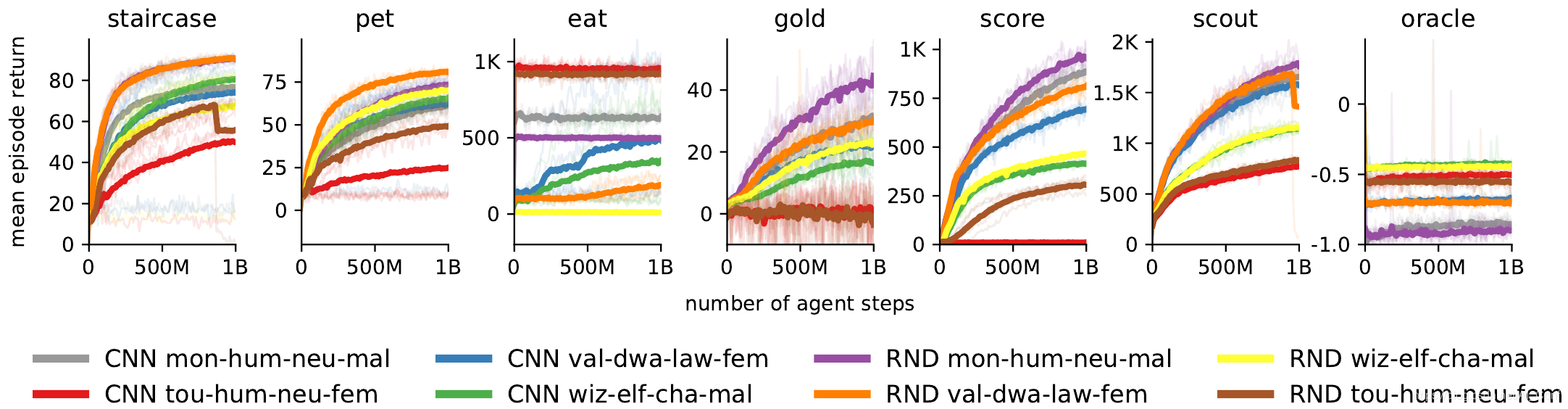
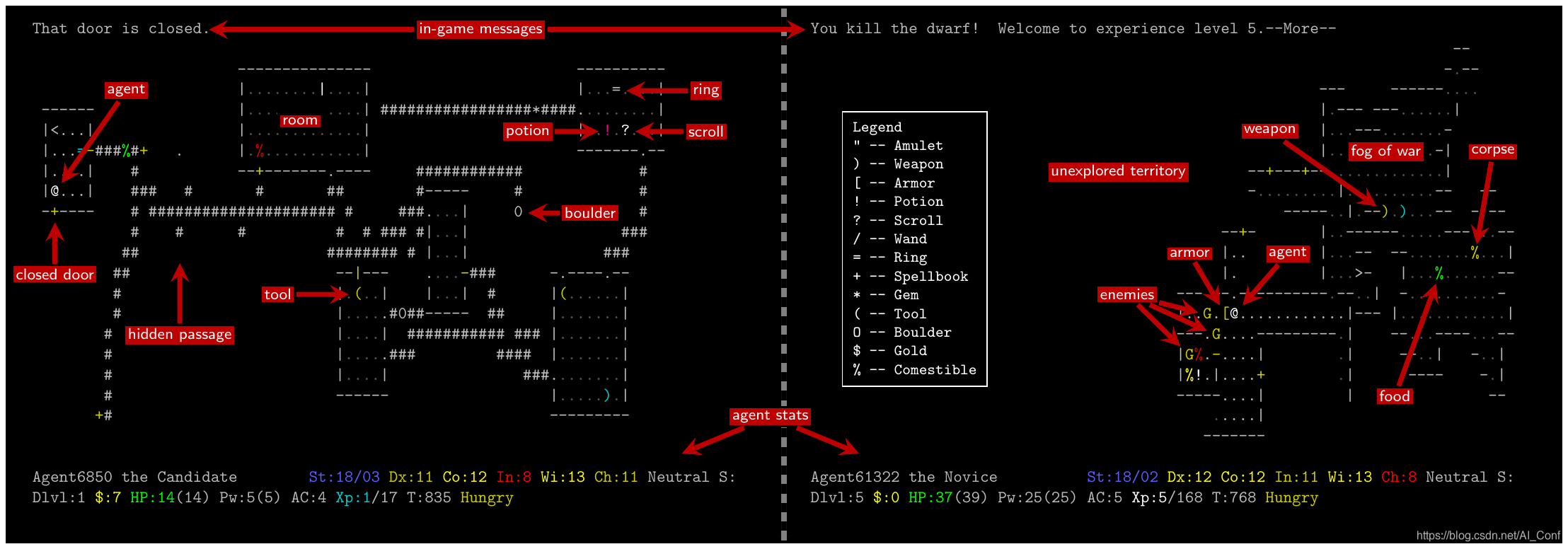
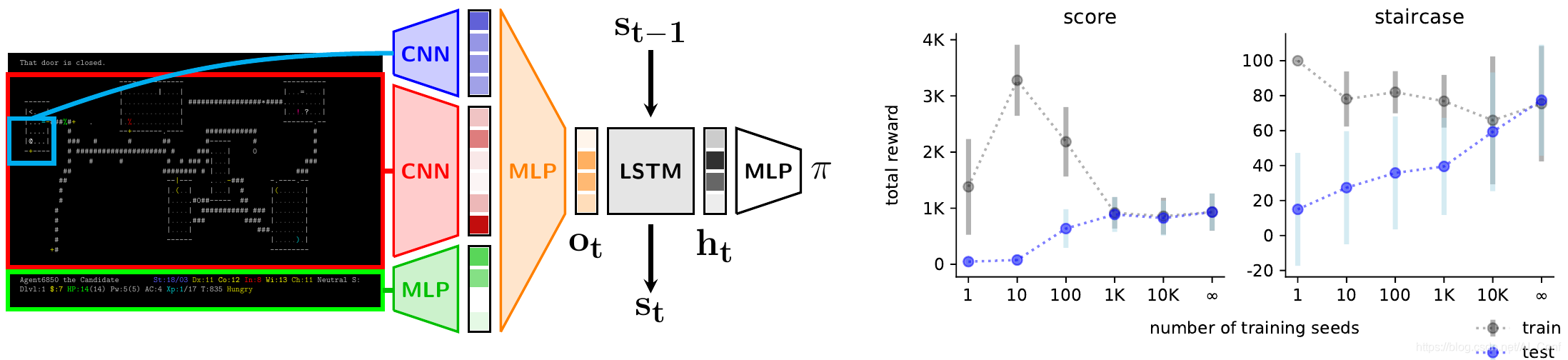
The NetHack Learning Environment
强化学习(Reinforcement Learning, RL)算法的进步与测试当前方法极限的挑战性环境的开发齐头并进。现有的RL环境要么足够复杂,要么基于快速仿真,但很少两者兼有。
本文中,作者介绍了NetHack学习环境(NLE),这是一个可扩展的、程序化生成的、随机的、丰富的、具有挑战性的RL研究环境,它基于流行的基于单机终端的类Roguelike游戏NetHack。作者认为,NetHack的复杂程度足以推动对探索、规划、技能习得和语言条件RL等问题的长期研究,同时大幅减少收集大量经验所需的计算资源。
作者将NLE及其任务套件与现有替代方案进行了比较,并讨论了为什么它是测试RL代理的健壮性和系统概括性的理想媒介。作者使用分布式Deep RL基线和随机网络蒸馏探索来展示游戏早期阶段的经验成功,同时对环境中训练的各种代理进行定性分析。
论文链接:https://www.aminer.cn/pub/5ef476b691e01165a63bbc71?conf=neurips2020
会议链接:https://www.aminer.cn/conf/neurips2020


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









