




想入门机器学习?K近邻算法(KNN)绝对是你的不二之选!作为最简单的监督学习算法之一,KNN原理直观,实现简单,非常适合新手入门。
另外,我整理了KNN经典论文+代码合集,需要的的话自取~
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/Xer-N5M--UZmsYrYISdvWw
https://mp.weixin.qq.com/s/Xer-N5M--UZmsYrYISdvWw
一、什么是K近邻算法?
K近邻算法(K-Nearest Neighbors, KNN)是一种基于实例的监督学习算法,核心思想可以概括为:**"物以类聚,人以群分"**。
简单来说,就是通过计算待分类样本与已知样本的距离,找到最近的K个样本,然后根据这K个样本的类别来判断新样本的类别。 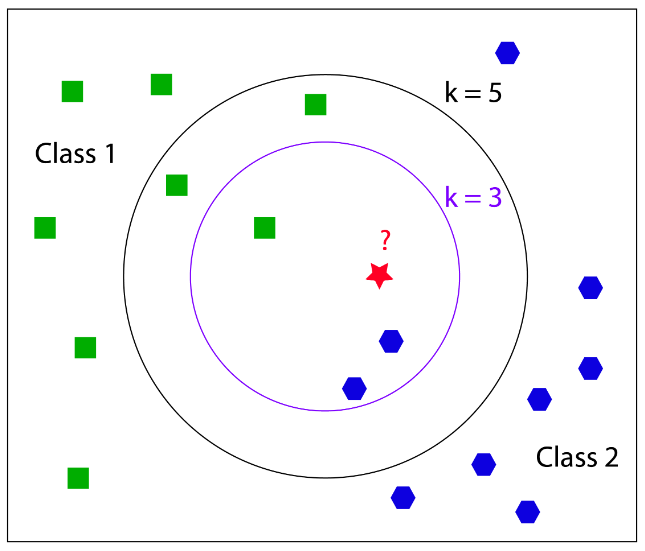
二、KNN工作原理(3步走)
-
计算距离:计算待分类样本与训练集中每个样本的距离
-
选近邻:找出距离最近的K个样本
- 做预测:
-
分类问题:K个样本中占比最高的类别即为预测结果
-
回归问题:K个样本的平均值作为预测结果
-
三、常用距离度量公式
-
欧氏距离(最常用):
其中n为特征维度,x和y为两个样本
-
曼哈顿距离:
四、KNN的优缺点
✅ 优点:
-
原理简单,易于理解和实现
-
无需训练过程,属于"懒惰学习"
-
适用于多分类问题
-
对数据分布无假设
❌ 缺点:
-
计算复杂度高,数据量大时速度慢
-
对噪声数据敏感
-
K值选择对结果影响大
-
对不平衡数据不友好
五、完整代码实现(分类+回归)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
from sklearn.metrics import accuracy_score
# --------------------------
# 1. KNN Classification Example (Iris Dataset)
# --------------------------
print("===== KNN Classification Example =====")
# Load dataset
iris = datasets.load_iris()
X = iris.data[:, :2] # Use first two features for visualization
y = iris.target
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Create and train KNN classification model
k = 3 # Select 3 nearest neighbors
knn_classifier = KNeighborsClassifier(n_neighbors=k)
knn_classifier.fit(X_train, y_train)
# Prediction and evaluation
y_pred = knn_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy when K={k}: {accuracy:.4f}")
# Visualize decision boundary
h = 0.02 # Step size of the grid
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = knn_classifier.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 4))
plt.subplot(121)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', s=50)
plt.title(f"KNN Classification Decision Boundary (K={k})")
plt.xlabel("Sepal Length")
plt.ylabel("Sepal Width")
# Explore the impact of different K values on results
k_range = range(1, 21)
accuracies = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracies.append(accuracy_score(y_test, y_pred))
plt.subplot(122)
plt.plot(k_range, accuracies, marker='o', color='b')
plt.title("Relationship between K Value and Accuracy")
plt.xlabel("K Value")
plt.ylabel("Accuracy")
plt.xticks(k_range)
plt.tight_layout()
plt.show()
# --------------------------
# 2. KNN Regression Example
# --------------------------
print("\n===== KNN Regression Example =====")
# Generate sample data
np.random.seed(42)
X = np.random.rand(100, 1) * 10 # Features
y = np.sin(X).ravel() + 0.1 * np.random.randn(100) # Target value (sine curve with noise)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Create and train KNN regression model
knn_regressor = KNeighborsRegressor(n_neighbors=5)
knn_regressor.fit(X_train, y_train)
# Prediction
y_pred = knn_regressor.predict(X_test)
# Visualize regression results
plt.figure(figsize=(8, 5))
plt.scatter(X_test, y_test, color='red', label='True Values', alpha=0.7)
plt.scatter(X_test, y_pred, color='blue', label='Predicted Values', alpha=0.7)
plt.title("KNN Regression Example")
plt.xlabel("Feature Value")
plt.ylabel("Target Value")
plt.legend()
plt.show()
六、代码说明与运行指南
-
代码包含两部分:KNN分类(基于鸢尾花数据集)和KNN回归(基于生成的正弦曲线数据)
-
分类部分可视化了决策边界,并展示了不同K值对模型准确率的影响
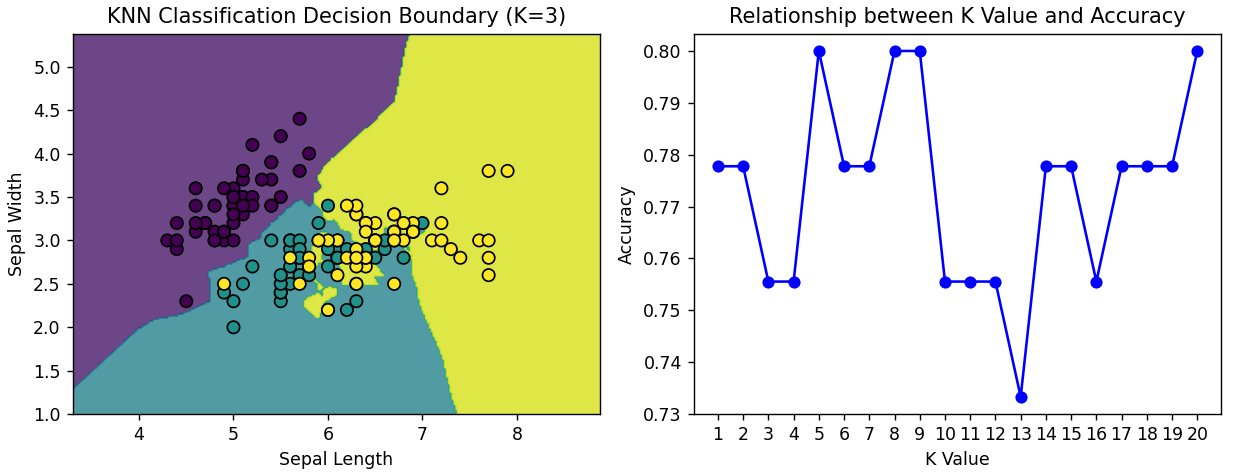
-
回归部分展示了KNN如何预测连续值
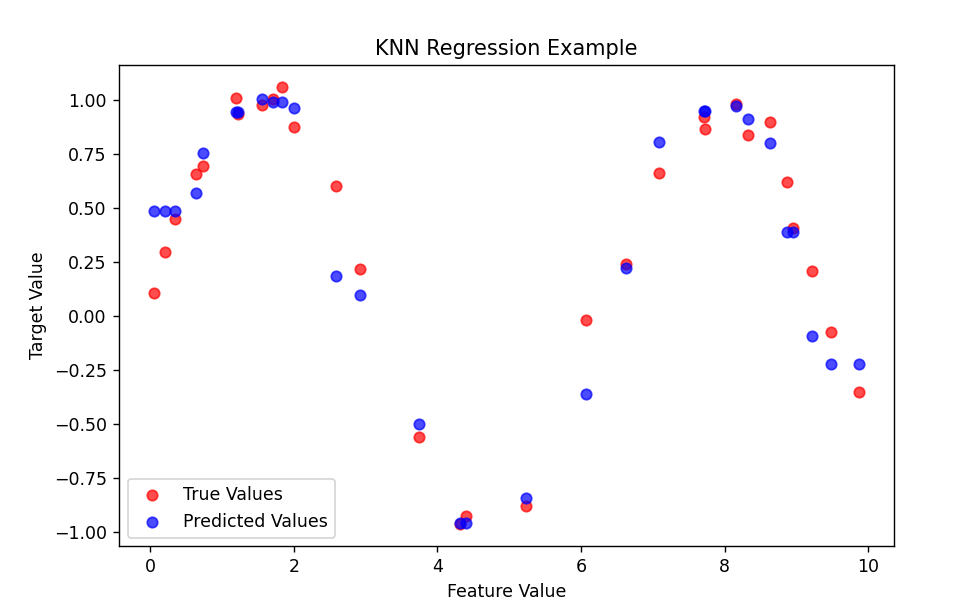 运行前请确保安装了必要的库:
运行前请确保安装了必要的库:
pip install numpy matplotlib scikit-learn
七、K值选择小技巧
-
K值过小:模型容易过拟合,对噪声敏感
-
K值过大:模型过于简单,可能欠拟合
-
通常选择奇数K值以避免投票平局
-
可以通过交叉验证寻找最优K值
KNN算法虽然简单,但在推荐系统、模式识别等领域有广泛应用。动手试试上面的代码,感受KNN的魅力吧!
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/Xer-N5M--UZmsYrYISdvWw
https://mp.weixin.qq.com/s/Xer-N5M--UZmsYrYISdvWw


















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









