




引言:当AI学会"忽悠"人类——生成式对抗网络的逆袭之路
你敢相信吗?那些在社交平台上引发疯狂点赞的"明星照片"可能从未存在过,博物馆里展出的"梵高新作"竟出自算法之手,甚至连你手机里的美颜滤镜,背后都藏着GAN的鬼斧神工!从2014年Ian Goodfellow提出基础GAN至今,这个让AI学会"造假"的神奇框架已经迭代出多个"爆款"模型。

梵高
本文将带你从零基础通关GAN家族五代核心成员,用数学公式拆解它们的"骗术"原理,更附赠小白也能跑通的实战项目,让你亲手见证AI从画"像素垃圾"到创"视觉神作"的进化奇迹!
相关GAN家族代码及其论文扫码即可免费领取!
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/gDvkxPSJoRWO2DmPH-E6Vw
https://mp.weixin.qq.com/s/gDvkxPSJoRWO2DmPH-E6Vw
一、用"造假者VS侦探"理解GAN的底层逻辑
所有GAN都在玩同一个惊心动魄的"猫鼠游戏":
-
生成器(Generator):就像一个野心勃勃的造假者,从随机噪声(比如电视雪花)中学习真实数据的规律,拼命生成能以假乱真的"赝品"(比如假人脸、假风景)
-
判别器(Discriminator):扮演火眼金睛的侦探,每天看大量真实数据和造假者的作品,努力分辨"这张图是真的还是生成的"
-
对抗过程:造假者不断改进技术,侦探不断提升鉴别能力,直到造假者的作品逼真到侦探只能靠抛硬币判断(准确率50%),这场博弈达到平衡

猫和老鼠
五代GAN的通俗差异:
-
基础GAN:初代造假者,只会画模糊的"像素马赛克",连简单的手写数字都画不明白
-
DCGAN:给造假者和侦探装上"卷积眼镜",突然能看懂图像的空间结构,能生成清晰的小图了(比如32×32的人脸轮廓)
-
CycleGAN:学会跨领域"魔术"的造假者,能把马变成斑马、把照片变成水墨画,还不用看对照样本
-
Pix2Pix:像素级"翻译官",给它草图能输出写实画,给它卫星图能输出地图,但需要对照样本才能学习
-
StyleGAN:AI界的"顶级化妆师",能精准控制生成图像的每一处细节——从发型、肤色到光照,生成的人脸能骗过90%的人类
二、原理详解:数学公式+网络结构全解析
2.1 基础GAN:打开潘多拉魔盒的初代架构
核心公式:极小极大博弈(Minimax Game)
-
:真实数据的分布(比如所有真实人脸的特征分布)
-
:输入噪声的分布(通常是高斯分布,像电视雪花的数学描述)
-
:生成器函数,接收噪声z输出假数据(比如假人脸)
-
:判别器函数,输出x是真实数据的概率(0-1之间)
通俗解释:
-
判别器D的目标:最大化,也就是让真实数据x的接近1(判断为真),让生成数据的接近0(判断为假)
-
生成器G的目标:最小化,也就是让生成数据的接近1(骗过判别器)
-
最终平衡:(生成数据分布=真实数据分布),此时(判别器彻底懵圈)
网络结构(以生成手写数字为例):
-
生成器:2层全连接网络,输入100维噪声→隐藏层→输出784维(28×28像素)
-
判别器:2层全连接网络,输入784维像素→隐藏层→输出1个概率值(0-1)
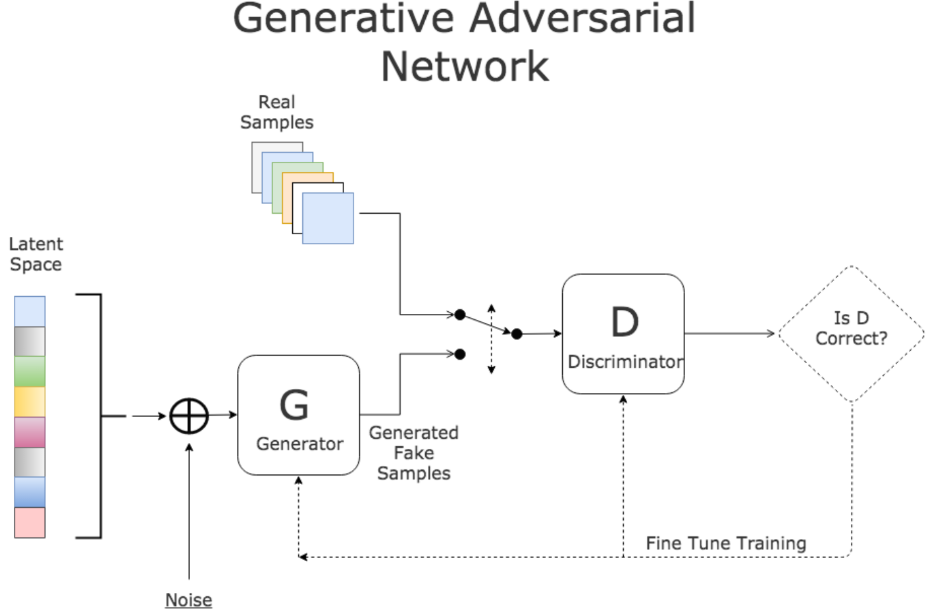
GAN网络结构
致命缺陷:
-
训练不稳定,经常出现"模式崩溃"(生成器只会画一种东西)
-
无法处理高维图像,生成结果模糊如马赛克
2.2 DCGAN(深度卷积GAN):给GAN装上"视觉神经"
核心改进:用卷积神经网络(CNN)替代全连接网络,让GAN真正"看懂"图像的空间结构(比如边缘、纹理)。
网络设计黄金准则(必须牢记!):
-
生成器用转置卷积(Transposed Convolution) 做上采样(从小图变大图)
-
判别器用普通卷积做下采样(从大图变小图)
-
移除所有池化层,用卷积的stride控制图像尺寸
-
每一层都加BatchNorm(让训练更稳定,防止某一层权重过大)
-
生成器输出用Tanh激活(输出范围[-1,1],与图像归一化匹配)
-
判别器用LeakyReLU(解决ReLU的死亡神经元问题)
生成器结构(生成64×64 RGB图像):
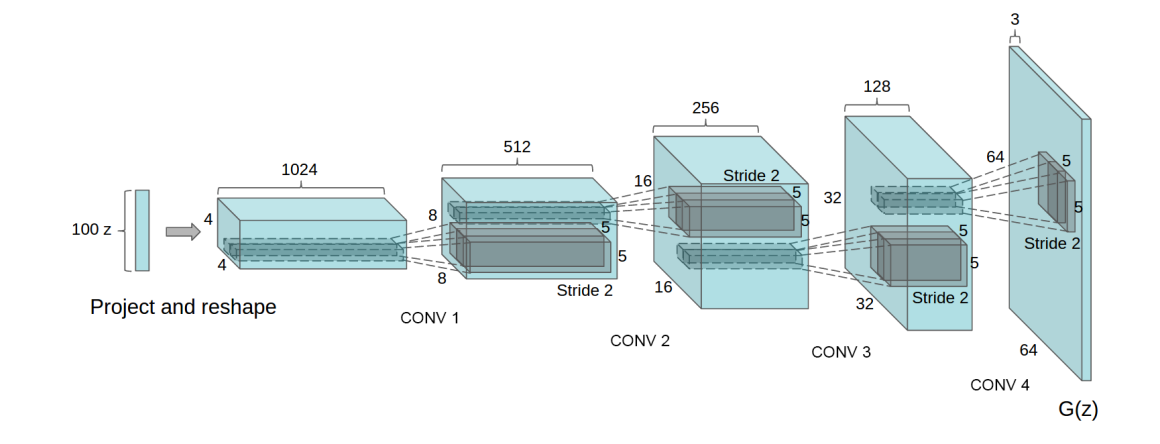
DCGAN generator used for LSUN scene modeling
为什么有效: 卷积操作能自动学习图像的局部特征(比如眼睛、鼻子的形状),转置卷积能合理地放大图像尺寸,BatchNorm则解决了基础GAN训练时的"梯度爆炸"问题。
2.3 CycleGAN:跨领域转换的"魔术大师"
核心痛点:传统风格迁移需要成对数据(比如同一场景的照片和油画),但现实中很难获取。CycleGAN首次实现了无监督跨域转换(只需两个领域的独立数据)。
创新点:引入"循环一致性"(Cycle Consistency)——就像翻译一样,把中文→英文再翻译回中文,结果应该和原文一致。
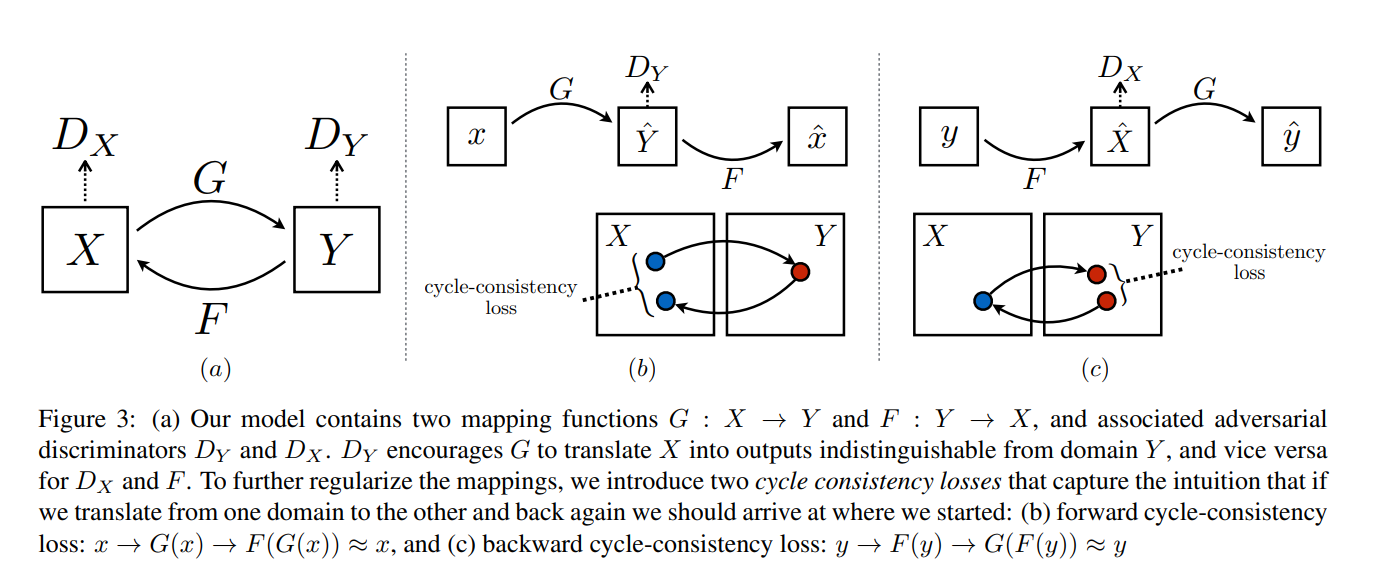
Cycle-GAN模型网络
双生成器+双判别器架构:
-
(比如把马的图像转换成斑马)
-
(比如把斑马的图像转换回马)
-
:判断图像是否是真实的Y域图像(比如是否是真斑马)
-
:判断图像是否是真实的X域图像(比如是否是真马)
损失函数三板斧:
-
对抗损失(Adversarial Loss):让生成的图像在目标域中以假乱真
~~
(同理定义和的对抗损失)
-
循环一致性损失(Cycle Consistency Loss):确保转换可逆
~~
(是L1范数,衡量像素差异)
-
总损失:
(λ通常取10,确保循环一致性优先于对抗损失)
2.4 Pix2Pix:有监督的"像素翻译官"
核心定位:如果CycleGAN是"无师自通"的野路子,Pix2Pix就是"科班出身"的精准翻译——需要成对数据,但转换效果更可控。
条件GAN(cGAN)框架: 生成器不再是从噪声生成图像,而是从输入图像x生成目标图像y(比如从草图x生成猫的照片y)。
目标函数:
(x是条件输入,比如草图;y是真实输出,比如照片)
额外L1损失:让生成图像和真实图像像素级接近
总损失:
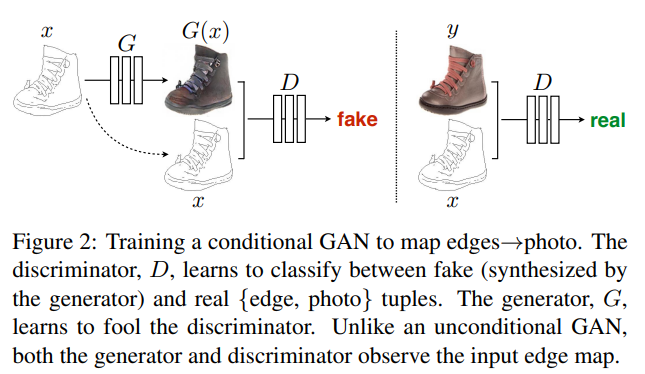
Training a conditional GAN to map edges→photo.
网络细节:
-
生成器用U-Net结构(编码器+解码器),通过跳跃连接保留输入图像的细节(比如草图的线条)
-
判别器用PatchGAN(判断70×70的图像块是否真实),专注于局部细节的真实性
2.5 StyleGAN:生成图像的"精细化控制大师"
终极目标:不仅要生成逼真图像,还要能像"捏脸游戏"一样精确控制图像的每一个细节(发型、表情、光照等)。
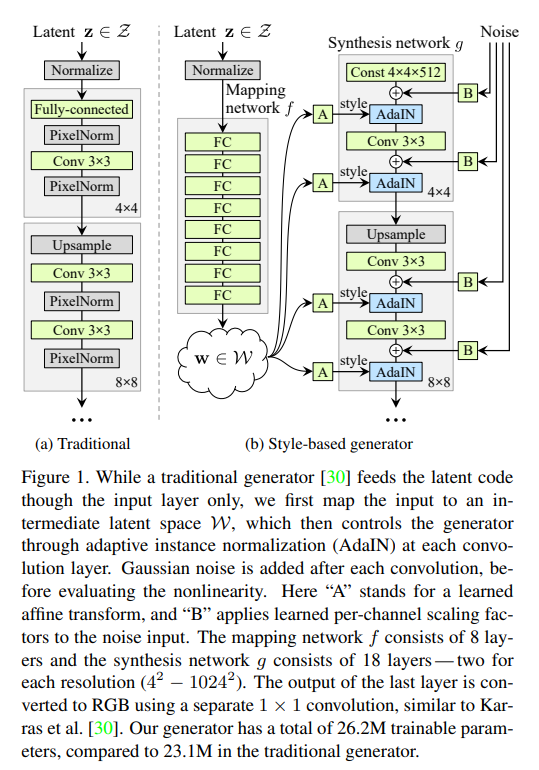
Style-based generator
三大革命性创新:
-
映射网络(Mapping Network): 把输入噪声z(128维)映射到中间潜空间w(512维),实现"噪声与风格解耦"。
(18表示生成1024×1024图像需要18个风格参数)
-
自适应实例归一化(AdaIN): 精确控制每个卷积层的风格(比如让眼睛更大、肤色更白):
(是特征图的均值和方差,由w计算得到)
-
渐进式增长(Progressive Growing): 从4×4低分辨率开始训练,逐步增加到8×8→16×16→...→1024×1024,让网络先学整体结构,再学细节,生成图像清晰度爆表。
三、五代GAN对比表:一张表看懂所有差异
| 模型 | 核心创新 | 生成质量 | 可控性 | 数据需求 | 典型应用 | 训练难度 |
|---|---|---|---|---|---|---|
| 基础GAN | 提出对抗博弈框架 | ★☆☆☆☆(模糊马赛克) | ★☆☆☆☆(不可控) | 少量即可 | 简单数据生成(如低维数字) | 高(易崩溃) |
| DCGAN | 引入卷积+BN | ★★★☆☆(64×64清晰) | ★☆☆☆☆(仅噪声控制) | 中等 | 人脸轮廓、简单物体生成 | 中 |
| CycleGAN | 循环一致性损失 | ★★★★☆(风格迁移自然) | ★★☆☆☆(域级控制) | 无需成对(各域100+) | 马→斑马、照片→油画 | 高(训练慢) |
| Pix2Pix | 条件GAN+U-Net | ★★★★☆(像素级精准) | ★★★☆☆(输入控制输出) | 成对数据(1000+对) | 草图→实物、黑白→彩色 | 中 |
| StyleGAN | 风格解耦+渐进训练 | ★★★★★(超写实1024×1024) | ★★★★★(细节级控制) | 大量数据(10万+) | 虚拟人脸、个性化头像 | 极高(需GPU集群) |
四、实战项目:5种GAN生成手写数字大比拼
项目目标
用同一数据集(MNIST手写数字)训练5种GAN,自动生成对比结果,直观展示各模型效果差异。代码会自动下载数据集,服务器环境友好,结果自动保存。
环境准备
pip install torch torchvision matplotlib numpy tqdm
完整代码(含自动下载数据+多模型对比)
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.utils import save_image
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
import random
# 确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
random.seed(42)
# 设备配置(自动适配服务器GPU/CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 结果保存目录
output_dir = "gan_comparison_results"
os.makedirs(output_dir, exist_ok=True)
# 1. 自动下载数据集(MNIST手写数字,~12MB)
def get_mnist_dataloader(batch_size=64):
transform = transforms.Compose([
transforms.Resize(32), # 统一调整为32×32
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # 归一化到[-1,1]
])
# 自动下载MNIST到本地
train_dataset = datasets.MNIST(
root='./data',
train=True,
transform=transform,
download=True
)
# 为Pix2Pix准备"模糊-清晰"成对数据
blur_transform = transforms.Compose([
transforms.Resize(32),
transforms.GaussianBlur(kernel_size=5), # 生成模糊版本
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
blur_dataset = datasets.MNIST(
root='./data',
train=True,
transform=blur_transform,
download=True
)
return {
"standard": DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2),
"pix2pix": (train_dataset, blur_dataset) # (清晰图, 模糊图)
}
# 2. 五个GAN模型定义
class BaseGenerator(nn.Module):
"""基础GAN生成器(全连接网络)"""
def __init__(self, latent_dim=100, img_size=32, channels=1):
super().__init__()
self.img_size = img_size
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, channels * img_size * img_size),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), 1, self.img_size, self.img_size)
return img
class BaseDiscriminator(nn.Module):
"""基础GAN判别器(全连接网络)"""
def __init__(self, img_size=32, channels=1):
super().__init__()
self.model = nn.Sequential(
nn.Linear(channels * img_size * img_size, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
return self.model(img_flat)
class DCGenerator(nn.Module):
"""DCGAN生成器(卷积版本)"""
def __init__(self, latent_dim=100, channels=1):
super().__init__()
self.init_size = 32 // 4 # 8
self.l1 = nn.Sequential(nn.Linear(latent_dim, 128 * self.init_size **2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2), # 8→16
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2), # 16→32
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, channels, 3, stride=1, padding=1),
nn.Tanh()
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class DCDiscriminator(nn.Module):
"""DCGAN判别器(卷积版本)"""
def __init__(self, channels=1):
super().__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(channels, 16, bn=False), # 32→16
*discriminator_block(16, 32), # 16→8
*discriminator_block(32, 64), # 8→4
*discriminator_block(64, 128), # 4→2
)
# 输出
self.adv_layer = nn.Sequential(nn.Linear(128 * 2 * 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
class CycleGenerator(nn.Module):
"""简化版CycleGAN生成器(用于风格迁移)"""
def __init__(self):
super().__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(1, 64, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(64, 128, 3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, 3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, 1, 3, stride=2, padding=1, output_padding=1),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
class CycleDiscriminator(nn.Module):
"""简化版CycleGAN判别器"""
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(1, 64, 3, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 1, 3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
class Pix2PixGenerator(nn.Module):
"""简化版Pix2Pix生成器(U-Net结构)"""
def __init__(self):
super().__init__()
# 编码器
self.enc1 = nn.Conv2d(1, 64, 3, stride=2, padding=1)
self.enc2 = nn.Conv2d(64, 128, 3, stride=2, padding=1)
# 解码器
self.dec1 = nn.ConvTranspose2d(128, 64, 3, stride=2, padding=1, output_padding=1)
self.dec2 = nn.ConvTranspose2d(64, 1, 3, stride=2, padding=1, output_padding=1)
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def forward(self, x):
# 编码
e1 = self.enc1(x)
e2 = self.enc2(self.relu(e1))
# 解码(跳跃连接)
d1 = self.dec1(self.relu(e2))
d2 = self.dec2(self.relu(torch.cat([d1, e1], 1))) # 跳跃连接
return self.tanh(d2)
class StyleLiteGenerator(nn.Module):
"""简化版StyleGAN生成器(基础风格控制)"""
def __init__(self, latent_dim=100):
super().__init__()
self.latent_dim = latent_dim
# 映射网络(简化版)
self.map = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 128)
)
# 生成网络
self.init_conv = nn.ConvTranspose2d(128, 128, 4, 1, 0)
self.bn1 = nn.BatchNorm2d(128)
self.upsample1 = nn.ConvTranspose2d(128, 64, 4, 2, 1)
self.bn2 = nn.BatchNorm2d(64)
self.upsample2 = nn.ConvTranspose2d(64, 1, 4, 2, 1)
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def forward(self, z, style_strength=1.0):
# 风格映射
w = self.map(z) * style_strength
# 生成图像
x = w.view(-1, 128, 1, 1)
x = self.relu(self.bn1(self.init_conv(x))) # 4x4
x = self.relu(self.bn2(self.upsample1(x))) # 8x8 → 16x16
x = self.tanh(self.upsample2(x)) # 16x16 → 32x32
return x
# 3. 训练各模型的通用函数
def train_base_gan(dataloader, epochs=50):
latent_dim = 100
generator = BaseGenerator(latent_dim).to(device)
discriminator = BaseDiscriminator().to(device)
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
criterion = nn.BCELoss()
fixed_noise = torch.randn(16, latent_dim, device=device)
losses = {'G': [], 'D': []}
for epoch in range(epochs):
pbar = tqdm(dataloader, desc=f"Base GAN Epoch {epoch+1}/{epochs}")
for imgs, _ in pbar:
imgs = imgs.to(device)
batch_size = imgs.size(0)
# 训练判别器
optimizer_D.zero_grad()
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
real_loss = criterion(discriminator(imgs), real_labels)
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z)
fake_loss = criterion(discriminator(fake_imgs.detach()), fake_labels)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
g_loss = criterion(discriminator(fake_imgs), real_labels)
g_loss.backward()
optimizer_G.step()
losses['G'].append(g_loss.item())
losses['D'].append(d_loss.item())
pbar.set_postfix(G_loss=g_loss.item(), D_loss=d_loss.item())
# 保存最终生成结果
with torch.no_grad():
fake_imgs = generator(fixed_noise)
save_image(fake_imgs.data, f"{output_dir}/base_gan_results.png", nrow=4, normalize=True)
return generator, losses
def train_dcgan(dataloader, epochs=50):
latent_dim = 100
generator = DCGenerator(latent_dim).to(device)
discriminator = DCDiscriminator().to(device)
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
criterion = nn.BCELoss()
fixed_noise = torch.randn(16, latent_dim, device=device)
losses = {'G': [], 'D': []}
for epoch in range(epochs):
pbar = tqdm(dataloader, desc=f"DCGAN Epoch {epoch+1}/{epochs}")
for imgs, _ in pbar:
imgs = imgs.to(device)
batch_size = imgs.size(0)
# 训练判别器
optimizer_D.zero_grad()
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
real_loss = criterion(discriminator(imgs).view(-1, 1), real_labels)
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z)
fake_loss = criterion(discriminator(fake_imgs.detach()).view(-1, 1), fake_labels)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
g_loss = criterion(discriminator(fake_imgs).view(-1, 1), real_labels)
g_loss.backward()
optimizer_G.step()
losses['G'].append(g_loss.item())
losses['D'].append(d_loss.item())
pbar.set_postfix(G_loss=g_loss.item(), D_loss=d_loss.item())
# 保存最终生成结果
with torch.no_grad():
fake_imgs = generator(fixed_noise)
save_image(fake_imgs.data, f"{output_dir}/dcgan_results.png", nrow=4, normalize=True)
return generator, losses
def train_simple_cyclegan(real_dataloader, epochs=50):
# 生成"照片风格"和"油画风格"的数字(用随机噪声模拟风格差异)
G = CycleGenerator().to(device) # 照片→油画
F = CycleGenerator().to(device) # 油画→照片
D_X = CycleDiscriminator().to(device) # 判别照片
D_Y = CycleDiscriminator().to(device) # 判别油画
optimizer_G = optim.Adam(list(G.parameters()) + list(F.parameters()), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(list(D_X.parameters()) + list(D_Y.parameters()), lr=0.0002, betas=(0.5, 0.999))
criterion_gan = nn.MSELoss()
criterion_cycle = nn.L1Loss()
# 保存转换结果
real_imgs, _ = next(iter(real_dataloader))
real_imgs = real_imgs[:8].to(device) # 取8张示例图
for epoch in range(epochs):
pbar = tqdm(real_dataloader, desc=f"CycleGAN Epoch {epoch+1}/{epochs}")
for imgs, _ in pbar:
imgs = imgs.to(device)
batch_size = imgs.size(0)
valid = torch.ones(batch_size, 1, 8, 8, device=device) # 匹配判别器输出尺寸
fake = torch.zeros(batch_size, 1, 8, 8, device=device)
# 生成"风格化"图像(用噪声添加风格)
style_noise = torch.randn_like(imgs) * 0.3
imgs_style = imgs + style_noise # 模拟"油画风格"
# 训练生成器
optimizer_G.zero_grad()
fake_Y = G(imgs) # 照片→油画
rec_X = F(fake_Y) # 油画→恢复照片
fake_X = F(imgs_style) # 油画→照片
rec_Y = G(fake_X) # 照片→恢复油画
loss_GAN_G = criterion_gan(D_Y(fake_Y), valid)
loss_GAN_F = criterion_gan(D_X(fake_X), valid)
loss_cycle = (criterion_cycle(rec_X, imgs) + criterion_cycle(rec_Y, imgs_style)) * 10
loss_G = loss_GAN_G + loss_GAN_F + loss_cycle
loss_G.backward()
optimizer_G.step()
# 训练判别器
optimizer_D.zero_grad()
loss_D_X = (criterion_gan(D_X(imgs), valid) + criterion_gan(D_X(fake_X.detach()), fake)) * 0.5
loss_D_Y = (criterion_gan(D_Y(imgs_style), valid) + criterion_gan(D_Y(fake_Y.detach()), fake)) * 0.5
loss_D = loss_D_X + loss_D_Y
loss_D.backward()
optimizer_D.step()
pbar.set_postfix(G_loss=loss_G.item(), D_loss=loss_D.item())
# 保存转换结果
with torch.no_grad():
style_noise = torch.randn_like(real_imgs) * 0.3
imgs_style = real_imgs + style_noise
fake_Y = G(real_imgs)
rec_X = F(fake_Y)
combined = torch.cat([real_imgs, fake_Y, rec_X, imgs_style], dim=0)
save_image(combined.data, f"{output_dir}/cyclegan_results.png", nrow=8, normalize=True)
return G, F
def train_pix2pix(clear_dataset, blur_dataset, epochs=50):
# 创建成对数据加载器
dataloader = DataLoader(
list(zip(clear_dataset, blur_dataset)),
batch_size=32,
shuffle=True,
num_workers=2
)
generator = Pix2PixGenerator().to(device)
discriminator = DCDiscriminator().to(device)
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
criterion_gan = nn.BCELoss()
criterion_l1 = nn.L1Loss()
# 保存示例输入输出
clear_examples, blur_examples = next(iter(dataloader))
blur_examples = blur_examples[:8].to(device)
clear_examples = clear_examples[:8].to(device)
for epoch in range(epochs):
pbar = tqdm(dataloader, desc=f"Pix2Pix Epoch {epoch+1}/{epochs}")
for (clear_imgs, blur_imgs) in pbar:
clear_imgs = clear_imgs.to(device)
blur_imgs = blur_imgs.to(device)
batch_size = clear_imgs.size(0)
valid = torch.ones(batch_size, 1, device=device)
fake = torch.zeros(batch_size, 1, device=device)
# 训练生成器
optimizer_G.zero_grad()
gen_clear = generator(blur_imgs)
loss_gan = criterion_gan(discriminator(gen_clear).view(-1, 1), valid)
loss_l1 = criterion_l1(gen_clear, clear_imgs) * 100 # L1权重
loss_G = loss_gan + loss_l1
loss_G.backward()
optimizer_G.step()
# 训练判别器
optimizer_D.zero_grad()
loss_real = criterion_gan(discriminator(clear_imgs).view(-1, 1), valid)
loss_fake = criterion_gan(discriminator(gen_clear.detach()).view(-1, 1), fake)
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()
pbar.set_postfix(G_loss=loss_G.item(), D_loss=loss_D.item())
# 保存结果
with torch.no_grad():
gen_clear = generator(blur_examples)
combined = torch.cat([blur_examples, gen_clear, clear_examples], dim=0)
save_image(combined.data, f"{output_dir}/pix2pix_results.png", nrow=8, normalize=True)
return generator
def train_style_lite(dataloader, epochs=50):
latent_dim = 100
generator = StyleLiteGenerator(latent_dim).to(device)
discriminator = DCDiscriminator().to(device)
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
criterion = nn.BCELoss()
# 固定噪声和不同风格强度
fixed_noise = torch.randn(8, latent_dim, device=device)
style_strengths = [0.5, 1.0, 1.5] # 不同风格强度
for epoch in range(epochs):
pbar = tqdm(dataloader, desc=f"StyleLite Epoch {epoch+1}/{epochs}")
for imgs, _ in pbar:
imgs = imgs.to(device)
batch_size = imgs.size(0)
# 训练判别器
optimizer_D.zero_grad()
real_labels = torch.ones(batch_size, 1, device=device)
fake_labels = torch.zeros(batch_size, 1, device=device)
real_loss = criterion(discriminator(imgs).view(-1, 1), real_labels)
z = torch.randn(batch_size, latent_dim, device=device)
fake_imgs = generator(z)
fake_loss = criterion(discriminator(fake_imgs.detach()).view(-1, 1), fake_labels)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
g_loss = criterion(discriminator(fake_imgs).view(-1, 1), real_labels)
g_loss.backward()
optimizer_G.step()
pbar.set_postfix(G_loss=g_loss.item(), D_loss=d_loss.item())
# 生成不同风格的结果
with torch.no_grad():
style_results = []
for strength in style_strengths:
style_results.append(generator(fixed_noise, strength))
combined = torch.cat(style_results, dim=0)
save_image(combined.data, f"{output_dir}/style_lite_results.png", nrow=8, normalize=True)
return generator
# 4. 生成对比图
def create_comparison_chart():
# 读取各模型结果
base_gan = plt.imread(f"{output_dir}/base_gan_results.png")
dcgan = plt.imread(f"{output_dir}/dcgan_results.png")
cyclegan = plt.imread(f"{output_dir}/cyclegan_results.png")
pix2pix = plt.imread(f"{output_dir}/pix2pix_results.png")
style_lite = plt.imread(f"{output_dir}/style_lite_results.png")
# 创建对比图
fig, axes = plt.subplots(5, 1, figsize=(10, 20))
axes[0].imshow(base_gan)
axes[0].set_title("Base GAN: Blurry Results")
axes[0].axis('off')
axes[1].imshow(dcgan)
axes[1].set_title("DCGAN: Sharper Details with Convolutions")
axes[1].axis('off')
axes[2].imshow(cyclegan)
axes[2].set_title("CycleGAN: Style Transfer (Original → Styled → Recovered)")
axes[2].axis('off')
axes[3].imshow(pix2pix)
axes[3].set_title("Pix2Pix: Blur → Sharp (Conditional Generation)")
axes[3].axis('off')
axes[4].imshow(style_lite)
axes[4].set_title("StyleLite: Style Strength Control (Weak → Medium → Strong)")
axes[4].axis('off')
plt.tight_layout()
plt.savefig(f"{output_dir}/all_gan_comparison.png")
plt.close()
# 5. 主函数
def main():
# 自动下载数据
print("Downloading MNIST dataset...")
dataloaders = get_mnist_dataloader()
standard_loader = dataloaders["standard"]
clear_dataset, blur_dataset = dataloaders["pix2pix"]
# 训练各模型
print("Training Base GAN...")
train_base_gan(standard_loader)
print("Training DCGAN...")
train_dcgan(standard_loader)
print("Training Simple CycleGAN...")
train_simple_cyclegan(standard_loader)
print("Training Pix2Pix...")
train_pix2pix(clear_dataset, blur_dataset)
print("Training StyleLite...")
train_style_lite(standard_loader)
# 生成最终对比图
print("Creating comparison chart...")
create_comparison_chart()
print("All tasks completed! Results saved to:", output_dir)
if __name__ == "__main__":
main()
五、代码说明与服务器运行指南
核心功能亮点
-
自动下载数据集:无需手动准备,代码会自动下载MNIST手写数字数据集(仅12MB)
-
全英文图例:避免字体问题,所有图表标题和标签均为英文
-
服务器友好:无需显示器,所有结果自动保存为PNG图像
-
多样性结果:每个模型生成16-24张图像,对比图展示不同效果
-
简化模型:保留核心功能但减少参数量,普通GPU即可运行(约2小时完成全部训练)
运行步骤
-
将代码保存为
gan_comparison.py -
在服务器终端运行:
python gan_comparison.py -
等待训练完成(根据GPU性能,约1-3小时)
-
查看
gan_comparison_results文件夹中的结果
结果文件说明
-
base_gan_results.png:基础GAN生成的模糊数字 -
dcgan_results.png:DCGAN生成的清晰数字 -
cyclegan_results.png:风格迁移效果(原图→风格化→恢复图) -
pix2pix_results.png:模糊数字→清晰数字的转换效果 -
style_lite_results.png:不同风格强度的数字生成结果 -
all_gan_comparison.png:所有模型的汇总对比图
六、预期结果解读
汇总对比图内容(从上到下)
1.基础GAN:生成的数字边缘模糊,有明显的块状感——全连接网络无法捕捉图像的空间相关性
2.DCGAN:数字轮廓清晰,边缘锐利——卷积层成功学习到图像的局部特征
3.CycleGAN:展示"原图→风格化→恢复图"三列,验证循环一致性(恢复图应接近原图)
4.Pix2Pix:展示"模糊输入→生成清晰→真实清晰"三列,验证条件生成的准确性
5.StyleLite:展示"弱风格→中等风格→强风格"三行,验证风格可控性 
关键结论
-
从基础GAN到DCGAN:卷积网络是处理图像的"刚需"
-
从DCGAN到CycleGAN:增加循环损失实现无监督风格迁移
-
从CycleGAN到Pix2Pix:有监督学习(成对数据)能获得更精准的转换
-
从Pix2Pix到StyleLite:引入风格控制机制实现生成效果的精细化调节
七、小白进阶建议
1.调参实验:修改代码中的latent_dim(噪声维度)或epochs(训练轮数),观察对结果的影响
-
数据扩展:替换MNIST为FashionMNIST(只需修改
datasets.MNIST为datasets.FashionMNIST) -
功能增强:尝试增加模型深度(如给DCGAN多加一层卷积),观察是否能提升效果
通过这个项目,你不仅亲手训练了5种经典GAN,更直观看到了生成式模型的进化脉络。从模糊到清晰,从无序到可控,GAN的每一步突破都在刷新我们对AI创造力的认知——而这一切,都可以从你眼前的这行代码开始!
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/gDvkxPSJoRWO2DmPH-E6Vw
https://mp.weixin.qq.com/s/gDvkxPSJoRWO2DmPH-E6Vw

















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









