




1. 为啥要提出VisRAG?
检索增强生成(Retrieval-augmented generation, RAG) 已经成为解决LLM幻觉和知识更新的经典方案,典型的RAG流程是基于文本的(以下简称TextRAG),以分割后的文本作为检索单元。
但是在真实场景中,知识往往以多模态的形式出现,比如教科书、手册等。这些文档中的文本与图像交织在一起。为了从这类数据源中提取文本,通常需要一个解析阶段,这包括布局识别、光学字符识别(OCR)和文本合并等后处理步骤。虽然这种方法在大多数情况下是有效的,但解析过程还是会不可避免地引入错误,从而对检索和生成阶段产生负面影响。
TextRAG只利用了文本信息,忽略了其他模态,如图像中可能包含的信息。尽管已经对图像检索和多模态RAG进行了研究,但这些研究主要集中在预定义场景中,其中图像和描述性文本已经被正确提取和配对,与现实世界中文本和图像(包括图形)常常交错在单个文档页面内的情况有所不同。
所以,本文作者提出了一种VisRAG,旨在探索完全基于视觉语言模型(VLMs)构建纯视觉RAG流程的可行性。
2. 什么是VisRAG?
VisRAG是一种新型视觉检索增强生成系统,由VLM驱动的检索器VisRAG-Ret和生成器VisRAG-Gen组成。
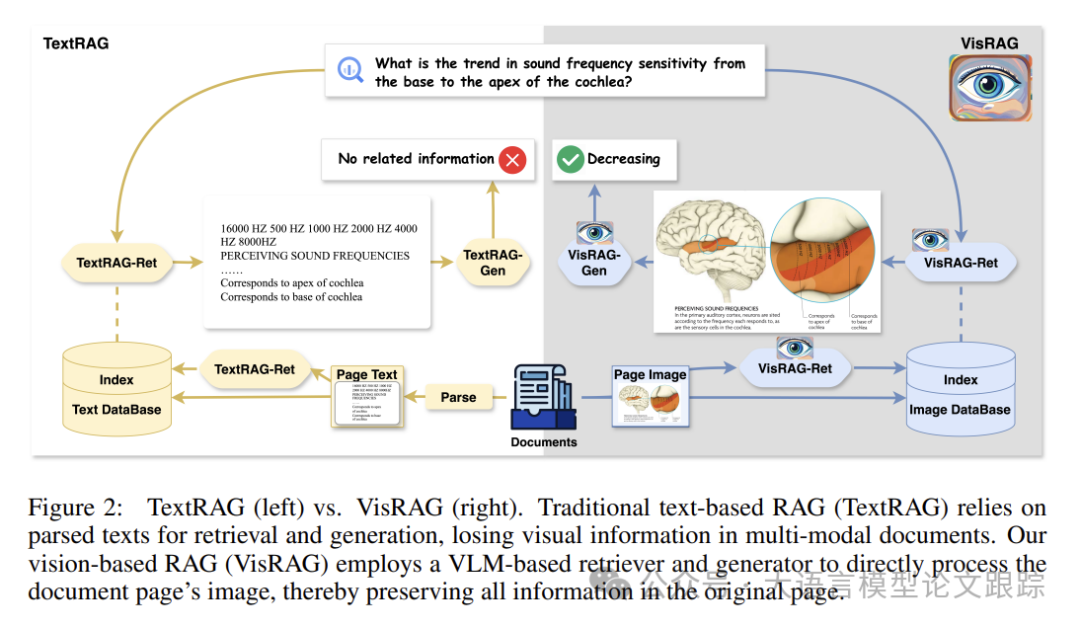
如上图(左边)所示,TextRAG 通常使用基于文本的单元进行检索和生成。右边是 VisRAG,与传统RAG框架利用文本片段进行检索和生成不同,VisRAG通过文档图像来保留全部信息,确保数据的完整性。
2.1 检索阶段
VisRAG的首个环节,即VisRAG-Ret,在给定查询q的情况下,从文档集合D中检索出一系列页面。
借鉴了文本密集检索器的 Bi-Encoder
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









