






一、函数模板
(1)使用
内置类型
template <typename T>//先定义模板,T代表的是类型
void Swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 1, b = 2;
double c = 1.1, d = 2.2;
swap(a, b);
swap(c, d);
cout << a << " " << b << endl;
cout << c << " " << d << endl;
return 0;
}自定义类型
class A
{
public:
A(int a = 0)
:_a(a)
{
}
int get()
{
return _a;
}
private:
int _a;
};
template <typename T>//先声明模板,T代表的是类型
void Swap(T& a, T& b)
{
//以下对自定义类型进行分析
T tmp = a;//调用编译器生成的拷贝构造函数
//下面两个调用编译器生成的赋值运算符重载函数
a = b;
b = tmp;
}
int main()
{
A a(1);
A b(2);
swap(a, b);//这个交换要理解底层
cout << a.get() << " " << b.get() << endl;
return 0;
}注意:typename是用来定义模板参数的关键字,也可以用class(不能用struct)
template<里面可以声明不止一个类型>
(2)原理

可以看到,两个swap调用的不是同一个函数,我们使用函数时调用的不是模板,而是编译器用这个模板生成的函数
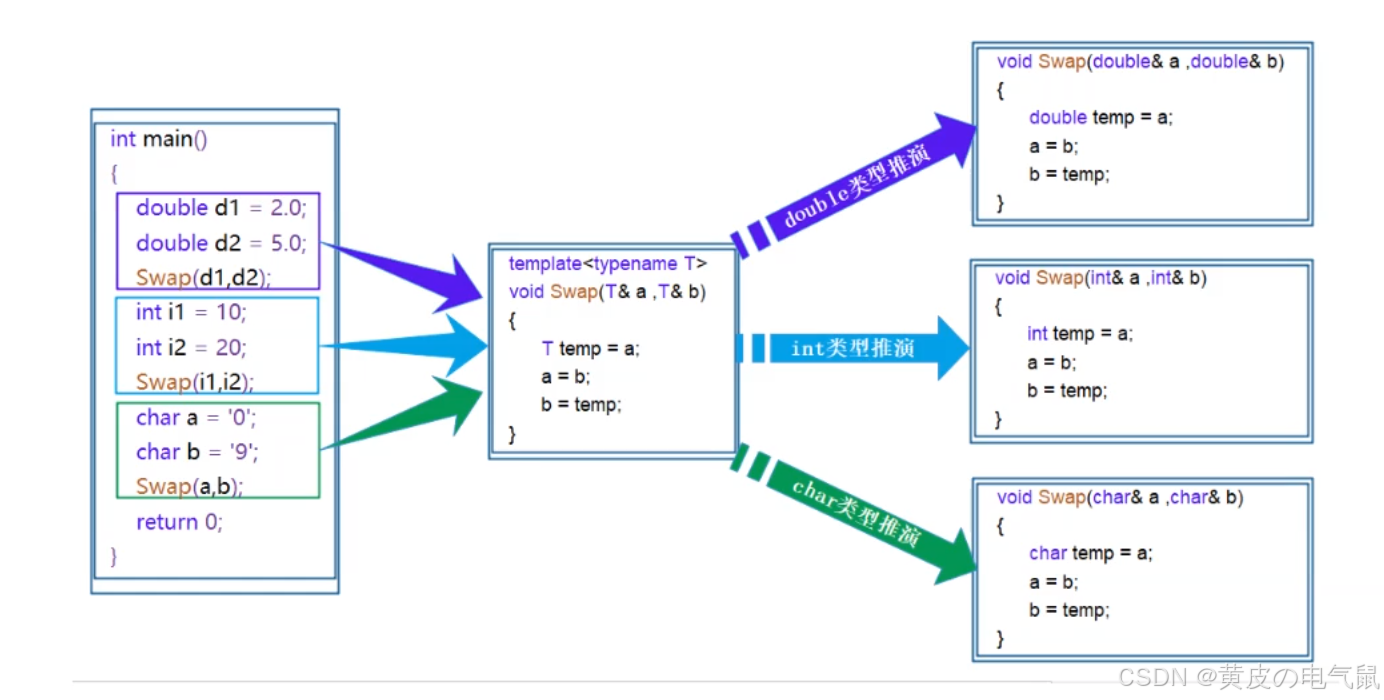
(3)函数模板实例化
template<typename T>
T Sum(const T& a, const T& b)
{
return a + b;
}
int main()
{
int a = 1;
double b = 1.1;
Sum(a, b);//这句报错,编译器用模板推导函数时发生返回值类型冲突(无法推导T是int还是double)
Sum(a, (int)b);//解法一,用户自己强制类型转化
// 注意:发生强转,要生成具有常性的临时变量,所以模板函数要用const的引用接收,实现权限平移
Sum < int >(a, b);//解法二,显式实例化
return 0;
}(4)模板参数匹配原则
1.一个非模板函数可以和一一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
//专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
//通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2);//与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本,变成第一个函数
}2.对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数,那么将选择模板
3.模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
二、类模板
类模板一定要显示实例化
template<typename T>
//可以看到模板类不想模板函数一样,它没有形参,无法通过1编译器判断参数类型,因此模板类调用时一定是显式调用
class A
{
public:
A(T a)
:_a(a)
{
}
private:
T _a;
};
int main()
{
//模板类在实例化是一定要显式调用
A<int>(1);
A<double>(2);
A<char>('a');
return 0;
}定义与声明分离时
template<typename T>
//template<typename T>,这句话的作用范围只能是下方的那个类或者是那个函数或者类型
class A
{
public:
A(T a)
:_a(a)
{
}
void print(const T& _a);//类中声明
private:
T _a;
};
//类外定义
template<typename T>//定义时要写模板关键字
void A<T>::print(const T& _a)//注意这里:类名<模板参数>=类型,这是模板类的类外定义要求
{
cout << _a << endl;
}
int main()
{
//模板类在实例化是一定要显式调用
//A是类名,A<int> 才是类型
A<int>(1);
A<double>(2);
A<char>('a');
return 0;
}三、模板进阶
(1)来看下面这个模板函数
#include<iostream>
#include<vector>
using namespace std;
template<class Container>
void Print(const Container& v)
{
//Container::const_iterator it = v.begin();这个是错误的写法
typename Container::const_iterator it = v.begin();
//auto it = v.begin();这个是auto的写法
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
Print(v);
return 0;
}按道理讲,每个容器都应该有const迭代器,这个模板应该可用于各种模板的打印,但这里编译会报错,需要在前面加上typename才会编译通过
原因如下:不加typename会使编译器无法判断it前面那坨是类型的名称还是类中的一个静态成员变量(静态成员变量的类外定义),加typename等于告诉它这坨是类型,当::前面的那个不是实例化(<int>)过的东西,就要加typename
如果直接用auto就没什么事了,因为auto跟据=右边来推导auto的类型
(2)非类型模板参数
以下是一个例子
#include<iostream>
#include<vector>
using namespace std;
//静态栈
template<class T,size_t N>
class Stack
{
private:
T _a[N];
int _top;
};
int main()
{
Stack<int, 10> st1;
Stack<int, 100> st1;
return 0;
}非类型模板参数(N)必须是一个整形常量,并且不能在类中修改
这就让人联想起库中的arry容器

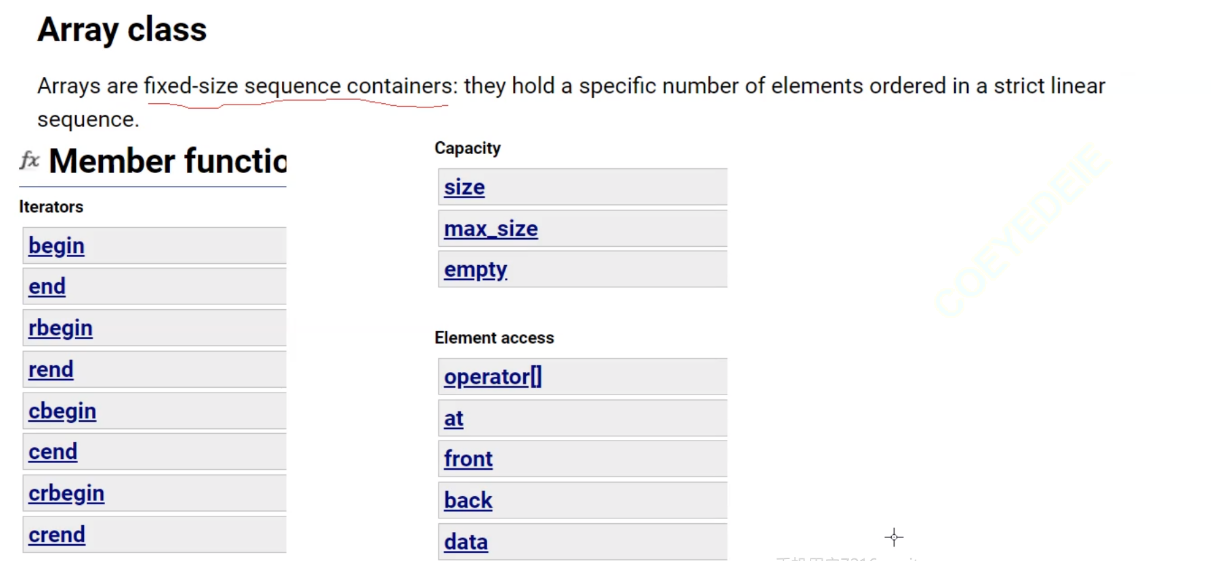 它的本质是一个定长数组,有迭代器,没有插入,[ ]访问
它的本质是一个定长数组,有迭代器,没有插入,[ ]访问
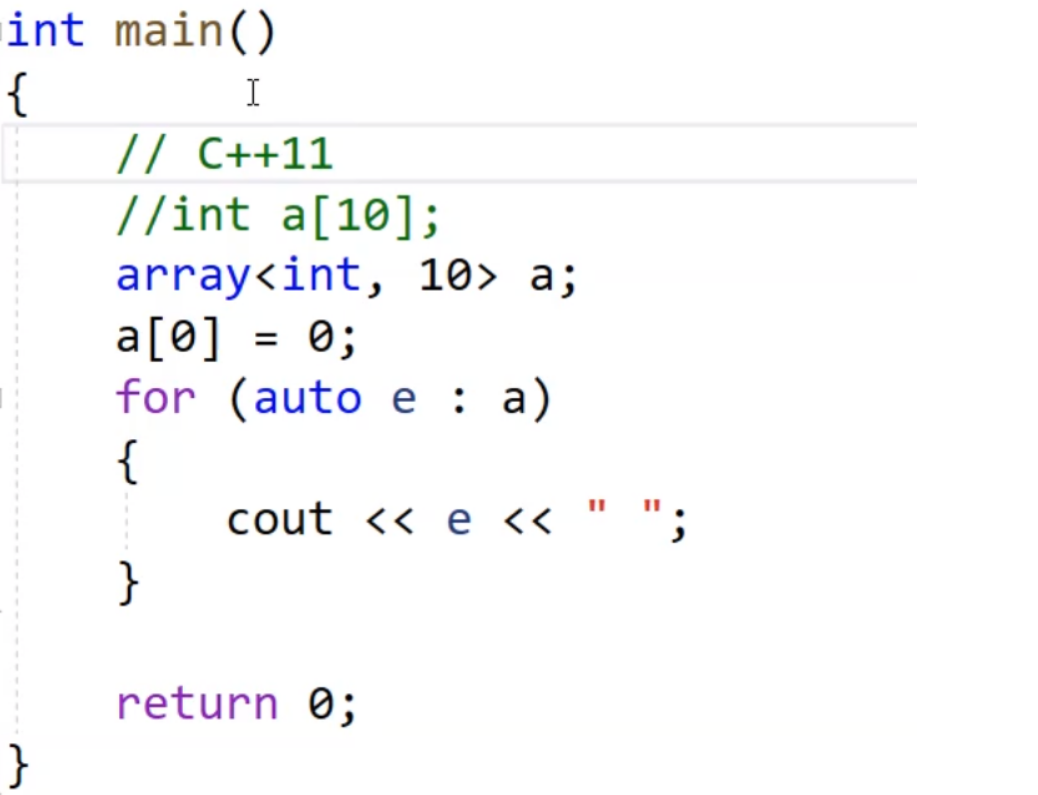 其实它和c的数组没有什么区别 ,arry的唯一好处就是越界检查严格,array对越界的检验非常严格,越界读写都能检查,普通数组,不能检查越界读,少部分越界写可以检查,是vector本身就有检查严格的特性(因为重载了[ ])
其实它和c的数组没有什么区别 ,arry的唯一好处就是越界检查严格,array对越界的检验非常严格,越界读写都能检查,普通数组,不能检查越界读,少部分越界写可以检查,是vector本身就有检查严格的特性(因为重载了[ ])
(3)模板的特化
先举几个个例子
#include<iostream>
using namespace std;
//T为一般类型时,调用这个
template<class T>
int Less(T left, T right)
{
return left < right;
}
//函数模板的特化
//T为int*时,调用这个
template<>
int Less<int*>(int* left, int* right)
{
return *left < *right;
}
//下面这个也可以
template<class T>
int Less(T* left, T* right)
{
return *left < *right;
}
#include<iostream>
using namespace std;
//一般模板
template<class T1,class T2>
class Data
{
public:
Data()
{
cout << "Data<T1,T2>" << endl;
}
private:
T1 _d1;
T2 _d2
};
//对interesting,double特化处理,可优先调用
template<>
class Data<int,double>
{
public:
Data()
{
cout << "Data<int,double>" << endl;
}
private:
int _d1;
double _d2;
};全特化与偏特化
// 全特化
template<>
class Data<int,double>
{
public:
Data() { cout << "Data<int,double>" << endl; }
private:
int _d1;
double _d2
};
// 偏特化
template<class T1>
class Data<T1, double>
{
public:
Data() { cout << "Data<T1, double>" << endl; }
private:
T1 _d1;
double _d2
};
// 偏特化:可能是对某些类型的进一步限制
template<class T1, class T2>
class Data<T1*, T2*>
{
public:
Data() { cout << "Data<T1*, T2*>" << endl; }
private:
T1* _d1;
T2* _d2;
};特化后的类相当于一个新类,可以在里面有不同的变量和函数,但是特化类不能独立存在
(4)模板的分离编译
1.以自创的stack类来举例
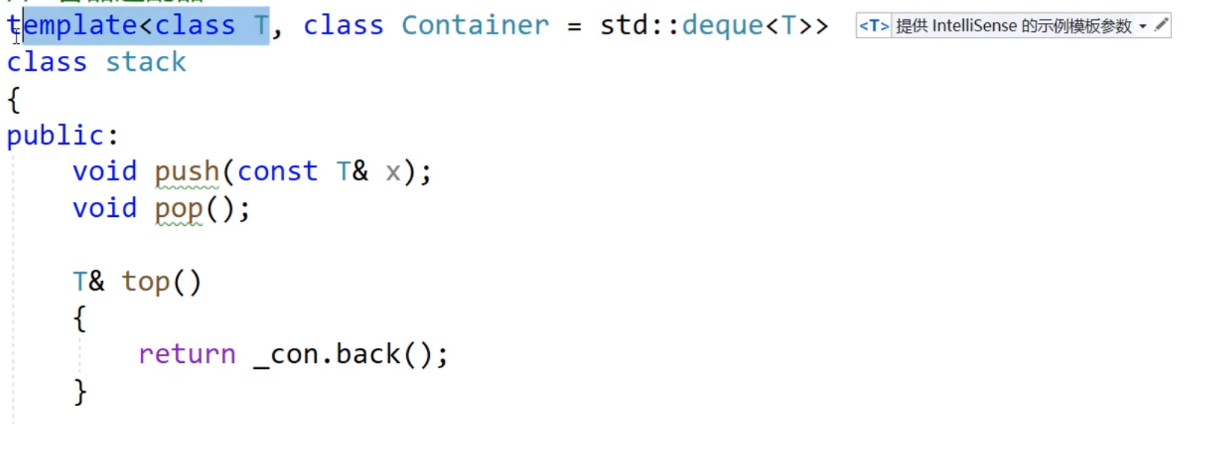
在stack类中写了push与pop函数的声明(.h文件中)

在.cpp文件中定义
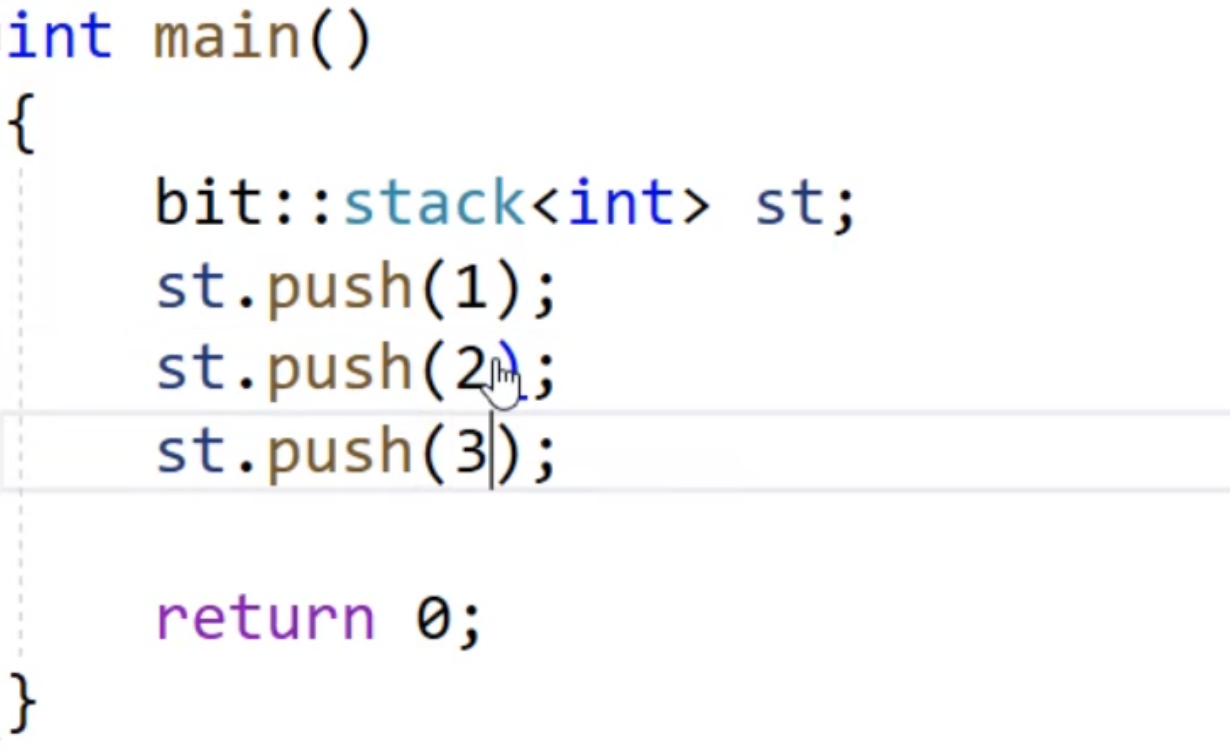 在test文件的main函数中调用
在test文件的main函数中调用
运行一下就会发生编译报错
2.以A类的两个func函数举例

.h文件中的A类创建,与func函数的声明
 在.cpp文件中对func1定义,对func2不定义
在.cpp文件中对func1定义,对func2不定义
运行一下也会编译报错
3.原因解释
 对于func例子
对于func例子
声明与定义分离会导致编译器在编译时无法确定函数的地址,编译能过是因为你有声明,声明是一种承诺,链接的时候再到其他文件去找定义,如果找到定义就不报错,找不到就编译报错
对于push与size的例子
可以看到push有模板,因为不知道T是什么,虽然可以通过声明承诺,但不能兑现地址,进而导致链接错误
所有模板不能实现声明与定义的分离,那么怎么解决捏?看看这个例子的解决方法
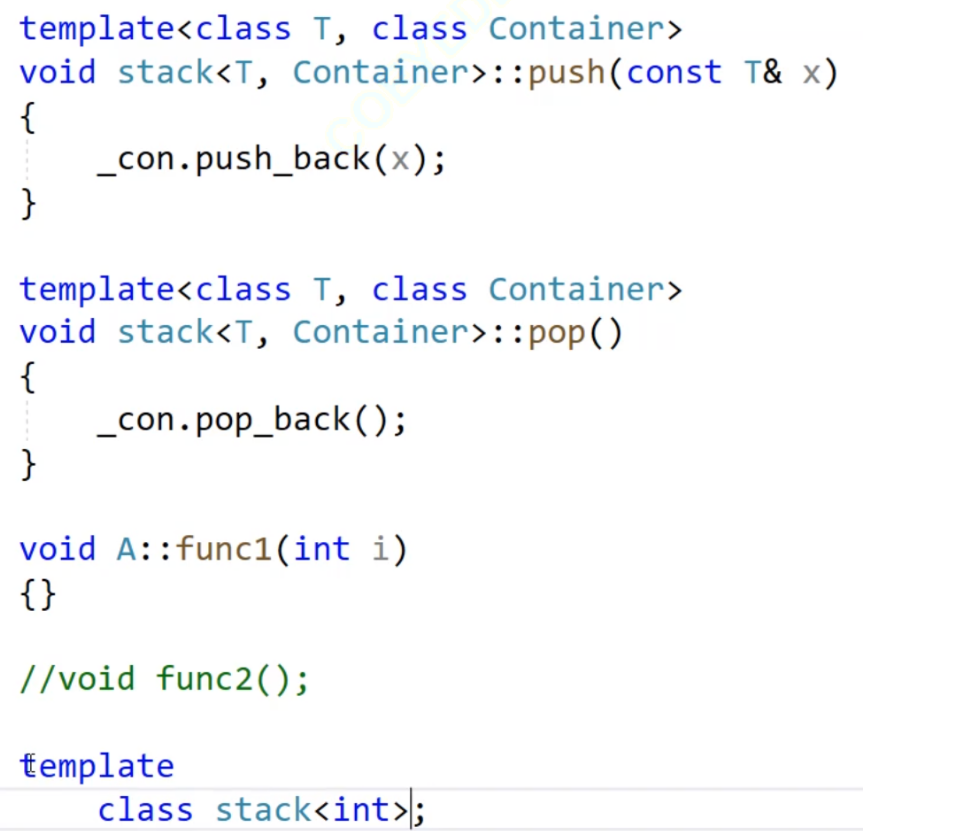
在定义底部加上模板实例化,你模板不知道怎么实例化,进而无法得出地址,所有我们采用直接告诉编译器的方式
但如果你还要实现其他模板类,就还要加上实例化声明
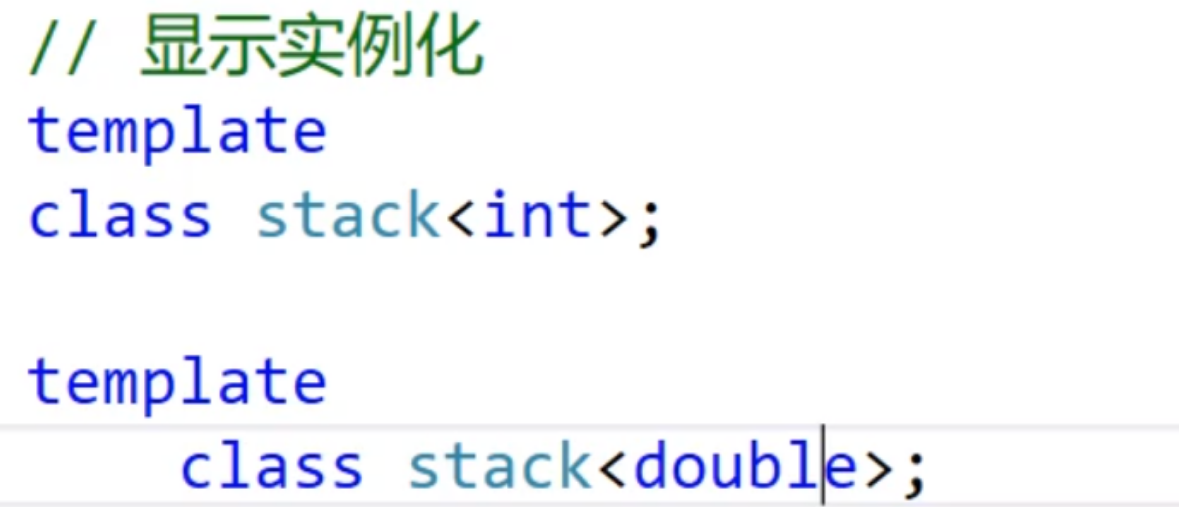
这样是很麻烦的,在看看其他方法
我们采用在当前文件(.h中)声明和定义分离,就是直接在声明的文件中实现声明与定义分离就好
小结:


















 3404
3404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









