






文章内容主要是数据集的转换、DETR的训练过程、以及TXT格式文件计算mAP值的方法。
一、准备数据集
DETR训练需要的是.json格式的标注文件,而我们准备的是.txt格式的标注文件,因此,首先要把txt格式的标注文件转为.json格式的标注文件。
注意:标注文件和对应的图片文件最好是全数字命名。
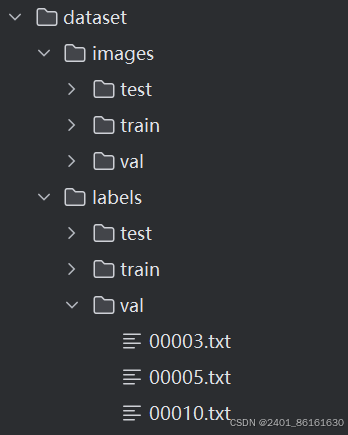
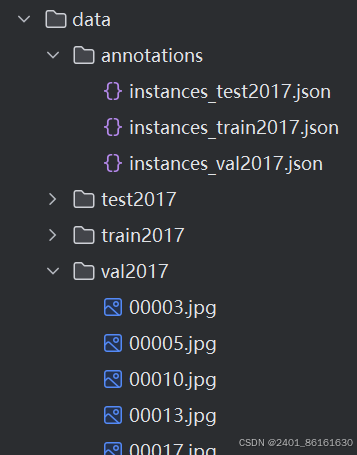
以上是txt格式数据集的结构,通过代码将其转为.json格式的数据集。
txt2json
import os
import cv2
import json
import argparse
from tqdm import tqdm
COCO_DICT = ['images', 'annotations', 'categories']
IMAGES_DICT = ['file_name', 'height', 'width', 'id']
ANNOTATIONS_DICT = ['image_id', 'iscrowd', 'area', 'bbox', 'category_id', 'id']
CATEGORIES_DICT = ['id', 'name']
YOLO_CATEGORIES = ['a','b','c','d','e','f'] # 替换为自己的标签名
parser = argparse.ArgumentParser(description='2COCO')
parser.add_argument('--image_path', type=str, default=r'C:/Users/Desktop/under/test2017/images/',
help='config file') # 照片路径,train和val
parser.add_argument('--annotation_path', type=str, default=r'C:/Users/Desktop/under/test2017/labels/',
help='config file') # label路径,train和val
parser.add_argument('--dataset', type=str, default='YOLO', help='config file')
parser.add_argument('--save', type=str, default='D:/ZZZ_My_file/detr-0.2/data/annotations/instances_test2017.json',
help='config file') # 最后的json文件名
args = parser.parse_args()
def load_json(path):
with open(path, 'r') as f:
json_dict = json.load(f)
for i in json_dict:
print(i)
print(json_dict['annotations'])
def save_json(dict, path):
print('SAVE_JSON...')
with open(path, 'w') as f:
json.dump(dict, f)
print('SUCCESSFUL_SAVE_JSON:', path)
def load_image(path):
img = cv2.imread(path)
return img.shape[0], img.shape[1]
def generate_categories_dict(category): # ANNOTATIONS_DICT=['image_id','iscrowd','area','bbox','category_id','id']
print('GENERATE_CATEGORIES_DICT...')
return [{CATEGORIES_DICT[0]: category.index(x) + 1, CATEGORIES_DICT[1]: x} for x in
category] # CATEGORIES_DICT=['id','name']
def generate_images_dict(imagelist, image_path,
start_image_id=11725): # IMAGES_DICT=['file_name','height','width','id']
print('GENERATE_IMAGES_DICT...')
images_dict = []
with tqdm(total=len(imagelist)) as load_bar:
for x in imagelist: # x就是图片的名称
# print(start_image_id)
dict = {IMAGES_DICT[0]: x, IMAGES_DICT[1]: load_image(image_path + x)[0], \
IMAGES_DICT[2]: load_image(image_path + x)[1], IMAGES_DICT[3]: imagelist.index(x) + start_image_id}
load_bar.update(1)
images_dict.append(dict)
return images_dict
def YOLO_Dataset(image_path, annotation_path, start_image_id=0, start_id=0):
categories_dict = generate_categories_dict(YOLO_CATEGORIES)
imgname = os.listdir(image_path)
images_dict = generate_images_dict(imgname, image_path)
print('GENERATE_ANNOTATIONS_DICT...')
annotations_dict = []
id = start_id
for i in images_dict:
image_id = i['id']
image_name = i['file_name']
W, H = i['width'], i['height']
annotation_txt = annotation_path + image_name.split('.')[0] + '.txt'
txt = open(annotation_txt, 'r')
lines = txt.readlines()
for j in lines:
category_id = int(j.split(' ')[0]) + 1
category = YOLO_CATEGORIES
x = float(j.split(' ')[1])
y = float(j.split(' ')[2])
w = float(j.split(' ')[3])
h = float(j.split(' ')[4])
x_min = (x - w / 2) * W
y_min = (y - h / 2) * H
w = w * W
h = h * H
area = w * h
bbox = [x_min, y_min, w, h]
dict = {'image_id': image_id, 'iscrowd': 0, 'area': area, 'bbox': bbox, 'category_id': category_id,
'id': id}
annotations_dict.append(dict)
id = id + 1
print('SUCCESSFUL_GENERATE_YOLO_JSON')
return {COCO_DICT[0]: images_dict, COCO_DICT[1]: annotations_dict, COCO_DICT[2]: categories_dict}
return {COCO_DICT[0]: images_dict, COCO_DICT[1]: annotations_dict, COCO_DICT[2]: categories_dict}
if __name__ == '__main__':
dataset = args.dataset # 数据集名字
save = args.save # json的保存路径
image_path = args.image_path # 对于coco是图片的路径
annotation_path = args.annotation_path # coco的annotation路径
if dataset == 'YOLO':
json_dict = YOLO_Dataset(image_path, annotation_path, 0)
save_json(json_dict, save)
代码要修改的部分:

将列表中的类别替换为自己的数据集类别。
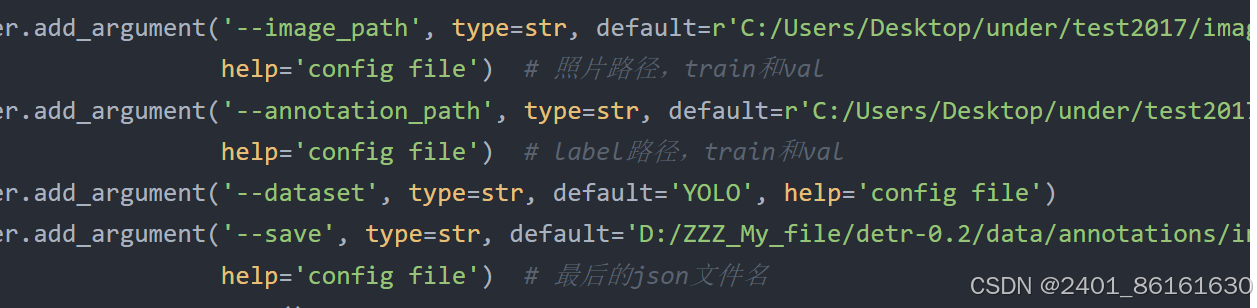
图片和标签改为自己的数据集路径,--save保存的格式要严格按照官方要求的格式,保存为如下名称,train和val保存格式与test的相同。

二、训练过程
1.修改相关参数
首先到官网上下载官方提供的预训练权重,通过代码将其转为自己的预训练权重。建议直接使用预训练权重训练,DETR从头开始训练很难,我在从头训练的过程中出现了AP值始终为0的问题,尚未解决。
import torch
pretrained_weights = torch.load('detr-r50-e632da11.pth', weights_only=True)
#NWPU数据集,10类
num_class = 7 #类别数+1,1为背景
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1, 256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights, "detr-r50_%d.pth"%num_class)
因为训练中有一个类是背景类,所以这里面的num_class要改为自己的数据集类别加1。我的数据集是6个类别,因此这里的总类别数为7,运行后会得到新的权重文件。![]()
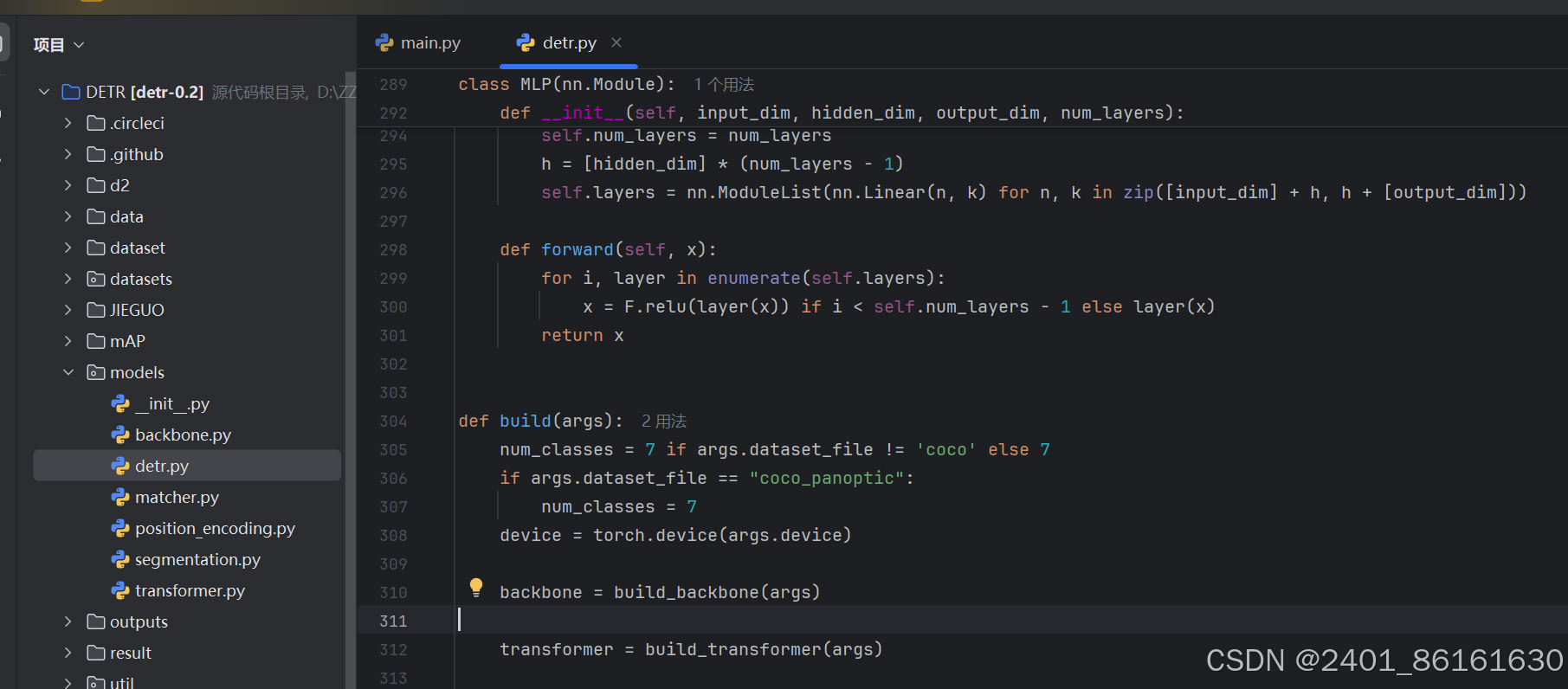
在detr.py文件中找到build函数,将类别数改为自己的类别数加1,如上图。
接下来在coco.py中找到make_coco_transform函数,将image_set分别改为‘train2017’、‘val2017’、‘test2017’。
在main.py中设置以下参数:

设置完成即可运行代码,开始训练。
2.训练过程可视化
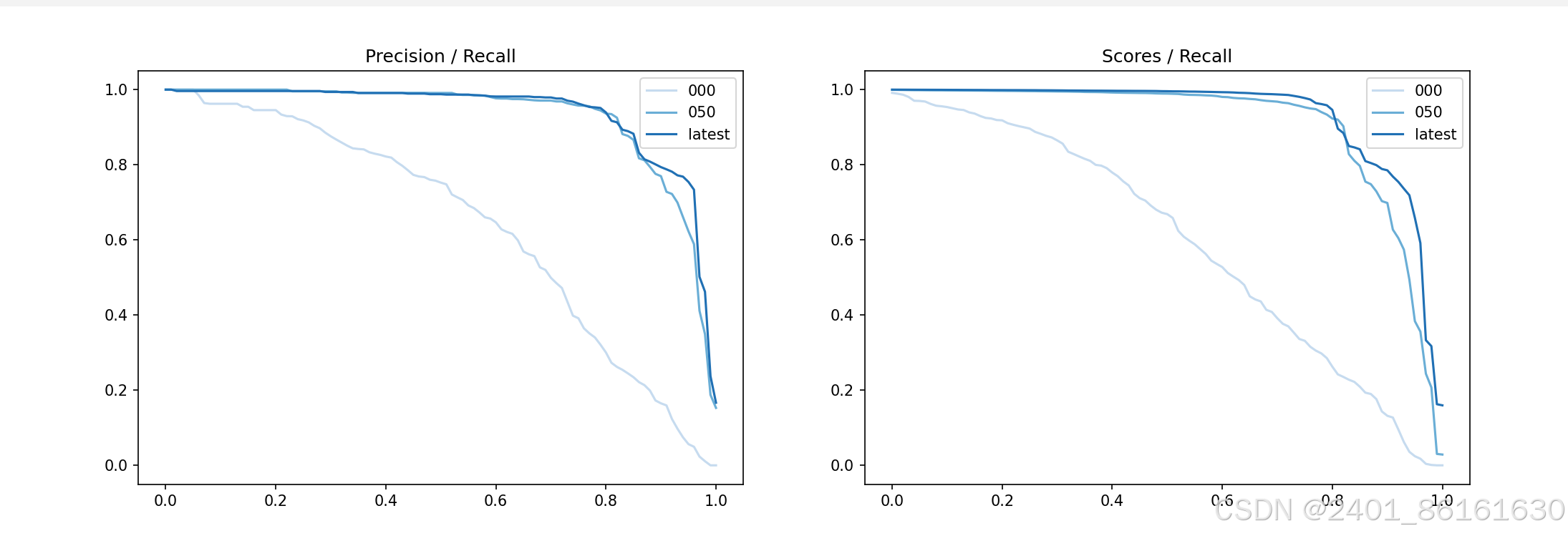
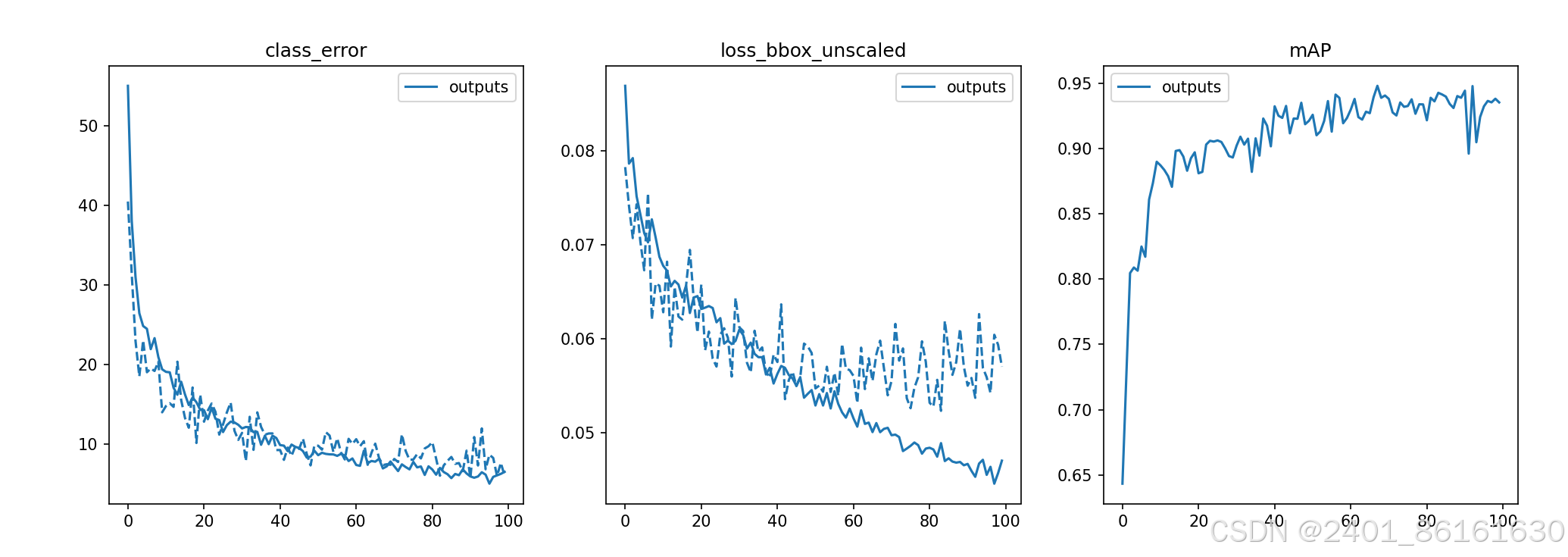
在plot_utils.py文件中加上如下代码运行,就可以得到图像。
关于这个地址中的\,如果运行不会出错,建议不要修改,我将其修改为/,会出现图片为空的情况。
if __name__ == '__main__':
files = list(Path(r'D:\ZZZ_My_file\DETR\outputs\eval').glob('*.pth'))
plot_precision_recall(files)
plt.show()
plot_logs(logs=Path(r'D:\ZZZ_My_file\DETR\outputs'),fields=('class_error', 'loss_bbox_unscaled', 'mAP'), ewm_col=0, log_name='log.txt')
plt.show()
三、推理过程
1.进行测试集的检测
代码如下(示例):
import os
import cv2 as cv
import torch
from pathlib import Path
import numpy as np
from torch.utils.data import DataLoader
import datasets
import util.misc as utils
from datasets import build_dataset, get_coco_api_from_dataset
from engine import evaluate, train_one_epoch
from models import position_encoding, backbone, transformer, detr
from datasets import coco, coco_eval
def build_model():
num_classes = 7
device = torch.device('cuda')
position_embedding = position_encoding.PositionEmbeddingSine(128, normalize=True)
train_backbone = False
# Backbone
test_backbone = backbone.Backbone('resnet50', train_backbone, False, False)
test_model = backbone.Joiner(test_backbone, position_embedding)
test_model.num_channels = test_backbone.num_channels
# Transformer
test_transformer = transformer.Transformer(
d_model=256,
dropout=0.1,
nhead=8,
dim_feedforward=2048,
num_encoder_layers=6,
num_decoder_layers=6,
normalize_before=False,
return_intermediate_dec=True
)
# DETR Model
model = detr.DETR(test_model, test_transformer, num_classes, num_queries=100, aux_loss=True)
return model
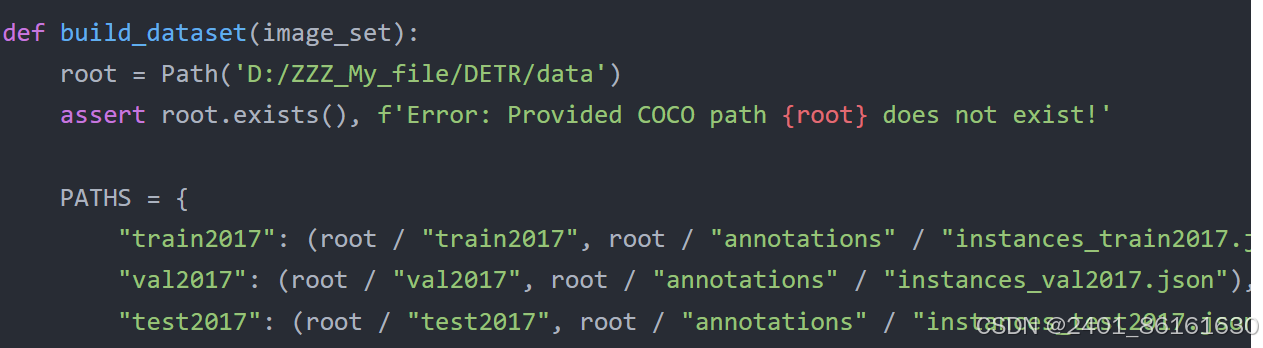
def build_dataset(image_set):
root = Path('D:/ZZZ_My_file/DETR/data')
assert root.exists(), f'Error: Provided COCO path {root} does not exist!'
PATHS = {
"train2017": (root / "train2017", root / "annotations" / "instances_train2017.json"),
"val2017": (root / "val2017", root / "annotations" / "instances_val2017.json"),
"test2017": (root / "test2017", root / "annotations" / "instances_test2017.json"),
}
img_folder, ann_file = PATHS[image_set]
print(f"Received image_set: {image_set}")
dataset = coco.CocoDetection(str(img_folder), str(ann_file), transforms=coco.make_coco_transforms(image_set),
return_masks=False)
return dataset
def save_predictions(image_info, predictions, output_dir):
"""
将预测结果保存到txt文件中
:param image_info: 图像信息,包含file_name
:param predictions: 预测结果,格式为[[class_id, confidence, x_min, y_min, x_max, y_max]]
:param output_dir: 输出目录
"""
# 创建输出目录如果不存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 构建输出文件路径,去掉.jpg扩展名
file_name_without_ext = os.path.splitext(image_info['file_name'])[0]
output_file = os.path.join(output_dir, f"{file_name_without_ext}.txt")
# 写入预测结果到文件
with open(output_file, 'w') as f:
for pred in predictions:
f.write(f"{pred[0]} {pred[1]:.6f} {pred[2]:.6f} {pred[3]:.6f} {pred[4]:.6f} {pred[5]:.6f}\n")
def main(dataset_type):
device = torch.device('cuda')
model = build_model()
model.to(device)
# 加载数据集
dataset_test = build_dataset(dataset_type)
sampler_test = torch.utils.data.SequentialSampler(dataset_test)
data_loader_test = DataLoader(dataset_test, batch_size=1, sampler=sampler_test,
drop_last=False, collate_fn=utils.collate_fn, num_workers=0)
base_ds = get_coco_api_from_dataset(dataset_test)
# 加载模型权重
load_path = 'D:\ZZZ_My_file\DETR\outputs\checkpoint.pth'
checkpoint = torch.load(load_path, map_location='cpu') # 修正错误
model.load_state_dict(checkpoint["model"], strict=False)
model.eval()
postprocessors = {'bbox': detr.PostProcess()}
coco_evaluator = coco_eval.CocoEvaluator(base_ds, ('bbox',))
output_dir = f"D:/ZZZ_My_file/DETR/data/{dataset_type}/predictions"
image_dir = f"D:/ZZZ_My_file/DETR/data/{dataset_type}"
for img_data, target in data_loader_test:
img_data = img_data.to(device)
target = [{k: v.to(device) for k, v in t.items()} for t in target]
if not target:
print("❌ 错误:target 为空,无法获取 image_id!")
continue
output = model(img_data)
orig_target_sizes = torch.stack([t["orig_size"] for t in target], dim=0)
result = postprocessors['bbox'](output, orig_target_sizes)
res = {t['image_id'].item(): output for t, output in zip(target, result)}
if coco_evaluator is not None:
coco_evaluator.update(res)
for t in target:
image_id = t['image_id'].item()
res = res[image_id]
# 从 COCO 数据集中查找文件名
image_info = next((img for img in dataset_test.coco.dataset["images"] if img["id"] == image_id), None)
if image_info:
file_name = image_info["file_name"]
else:
print(f"⚠️ 警告:找不到 image_id {image_id} 对应的 file_name!")
continue
img_path = os.path.join(str(dataset_test.root), file_name)
if not os.path.exists(img_path):
print(f"❌ 错误:文件 {img_path} 不存在!")
continue
img = cv.imread(img_path)
if img is None:
print(f"❌ 错误:无法加载图片 {img_path},请检查文件格式!")
continue
res_index = []
score = []
min_score = 0.25
res_label = []
res_bbox = []
num_detections = len(res['scores'])
for i in range(num_detections):
if float(res['scores'][i]) > min_score:
score.append(float(res['scores'][i]))
res_index.append(i)
res_label.append(int(res['labels'][i].cpu().numpy().item()))
res_bbox.append(res['boxes'][i].cpu().numpy().tolist())
print(f"Processing {image_id}")
print("Result:", score, res_label, res_bbox)
# 画框
for bbox in res_bbox:
x_min, y_min, x_max, y_max = map(int, bbox)
cv.rectangle(img, (x_min, y_min), (x_max, y_max), (255, 0, 0), 1)
cv.imshow("Faceimglabel", img)
cv.waitKey(20) # 每张图片显示0.5秒后自动跳转
cv.destroyAllWindows() # 关闭窗口,防止图片重叠
# 保存预测结果到txt文件
predictions = [[res_label[i], score[i], bbox[0], bbox[1], bbox[2], bbox[3]] for i, bbox in enumerate(res_bbox)]
save_predictions(image_info, predictions, output_dir)
if coco_evaluator is not None:
coco_evaluator.synchronize_between_processes()
coco_evaluator.accumulate()
coco_evaluator.summarize()
print(coco_evaluator)
if __name__ == '__main__':
dataset_type = "test2017"
main(dataset_type)修改类别数、修改路径、修改模型权重、



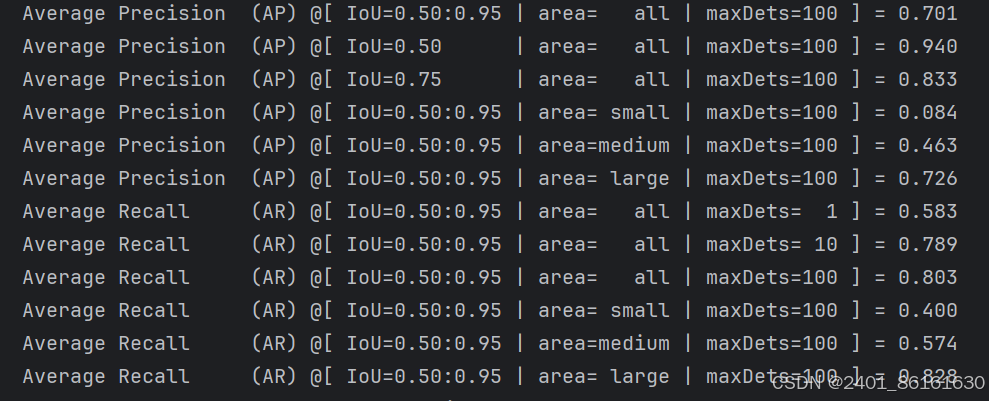
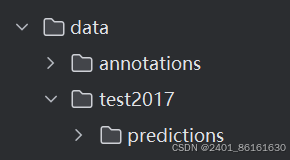
运行后会得到coco格式的评价指标,并在data文件夹下生成predictions文件夹,里面包含检测框信息。
2.txt格式的标注文件进行mAP的计算
yolo格式的标注文件中的真实框信息是经过归一化的,运行get_GT.py,将真实框信息转换为实际的坐标与尺寸。
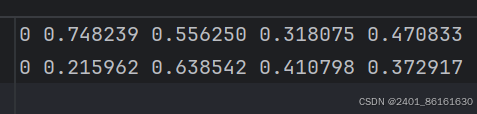

第一个数字是类别,后面四个分别是坐标和宽高。
get_GT.py
import numpy as np
import cv2
import torch
import os
label_path = '../dataset/labels/test'
image_path = '../dataset/images/test'
# 坐标转换,原始存储的是YOLOv5格式
# Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
def xywhn2xyxy(x, w=800, h=800, padw=0, padh=0):
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
return y
folder = os.path.exists('GT')
if not folder:
os.makedirs('GT')
folderlist = os.listdir(label_path)
for i in folderlist:
label_path_new = os.path.join(label_path, i)
with open(label_path_new, 'r') as f:
lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # predict_label
read_label = label_path_new.replace(".txt", ".jpg")
read_label_path = read_label.replace('labels/test', 'images/test')
print(read_label_path)
img = cv2.imread(str(read_label_path))
h, w = img.shape[:2]
lb[:, 1:] = xywhn2xyxy(lb[:, 1:], w, h, 0, 0) # 反归一化
for _, x in enumerate(lb):
class_label = int(x[0]) # class
cv2.rectangle(img, (round(x[1]), round(x[2])), (round(x[3]), round(x[4])), (0, 255, 0))
with open('GT/' + i, 'a') as fw:
fw.write(str(x[0]) + ' ' + str(x[1]) + ' ' + str(x[2]) + ' ' + str(x[3]) + ' ' + str(
x[4]) + '\n')
运行测试代码后生成的预测框信息中的类别,因为多了一个空白类,因此要减去1,同时为了和真实框的类别匹配,转为小数点后一位。


运行代码,会将predictions文件夹中的txt文件中类别数减1,并转为小数点后一位。第二个数字是置信度分数。同时显示删除了predictions文件夹中几个空文件,因为如果存在空文件,计算mAP时,真实框文件夹和预测框文件夹无法匹配,导致计算错误。
import os
def delete_empty_txt_files(directory):
deleted_count = 0
# 遍历目录中的所有文件
for filename in os.listdir(directory):
file_path = os.path.join(directory, filename)
# 如果是txt文件
if filename.endswith('.txt'):
if os.path.getsize(file_path) == 0:
os.remove(file_path)
deleted_count += 1
else:
# 处理每个文件的内容
modify_first_number_in_file(file_path)
print(f"总共删除了 {deleted_count} 个文件。")
def modify_first_number_in_file(file_path):
with open(file_path, 'r') as file:
lines = file.readlines()
# 修改每行的第一个数字(先减1,再变为小数点后一位)
modified_lines = []
for line in lines:
parts = line.split()
if parts:
try:
parts[0] = f"{(float(parts[0]) - 1):.1f}"
except ValueError:
pass # 如果无法转换为浮点数,则跳过
modified_lines.append(' '.join(parts) + '\n') # 保持换行符
# 将修改后的内容写回文件
with open(file_path, 'w') as file:
file.writelines(modified_lines)
# 使用示例
directory = "D:/ZZZ_My_file/DETR/data/test2017/predictions" # 替换为你的目标目录
delete_empty_txt_files(directory)
上面已经将没有预测框的空文件删除了,但是为了mAP计算的准确性,要为没有预测框的文件制作虚拟预测框文件,我们运行generate_virtual_DR_files.py代码,他会检测GT和DR文件夹的区别,同时将DR文件夹中没有的文件,从GT中复制一份并改为置信度为0,保存在DR文件夹下的ZJ文件夹中,将ZJ中的虚拟框文件复制到DR中,即可完成两个文件夹的制作。
generate_virtual_DR_files.py
import sys
import os
import glob
import shutil
# Paths to the folders
GT_PATH = 'D:/ZZZ_My_file/DETR/mAP/GT'
DR_PATH = 'D:/ZZZ_My_file/DETR/mAP/DR'
backup_folder = 'ZJ' # Backup folder where modified files will be stored
# Make sure the current working directory is correct
os.chdir(GT_PATH)
gt_files = glob.glob('*.txt')
if len(gt_files) == 0:
print("Error: no .txt files found in", GT_PATH)
sys.exit()
os.chdir(DR_PATH)
dr_files = glob.glob('*.txt')
if len(dr_files) == 0:
print("Error: no .txt files found in", DR_PATH)
sys.exit()
gt_files = set(gt_files)
dr_files = set(dr_files)
print('Total ground-truth files:', len(gt_files))
print('Total detection-results files:', len(dr_files))
print()
# Find the files that are in GT_PATH but not in DR_PATH
gt_backup = gt_files - dr_files
def backup_and_modify(src_folder, backup_files, backup_folder):
# Create the backup folder if it doesn't exist
if not os.path.exists(backup_folder):
os.makedirs(backup_folder)
# Process each file that needs to be backed up and modified
for file in backup_files:
# Copy the file to the backup folder
shutil.copy(os.path.join(src_folder, file), os.path.join(backup_folder, file))
# Open the file and modify its content
with open(os.path.join(src_folder, file), 'r') as f:
lines = f.readlines()
# Modify the content of the file
modified_lines = []
for line in lines:
parts = line.split()
# Insert '0' after the first position (class_id), shifting the rest
parts.insert(1, '0')
modified_lines.append(' '.join(parts) + '\n')
# Write the modified content back to the file in the backup folder
with open(os.path.join(backup_folder, file), 'w') as f:
f.writelines(modified_lines)
# Perform the backup and modification for the files that need to be moved
backup_and_modify(GT_PATH, gt_backup, backup_folder)
# Print the results
if gt_backup:
print('Total ground-truth backup files:', len(gt_backup))
print("Backup and modification completed!")
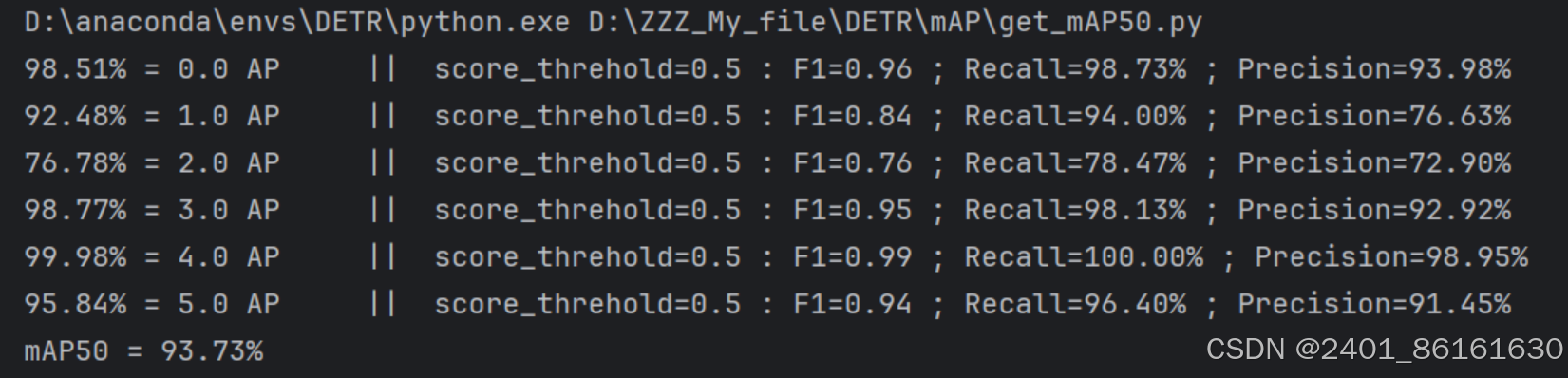
此时运行get_mAP50.py,就可以计算出IOU为0.5时的mAP值。
import glob
import json
import os
import shutil
import operator
import sys
import argparse
import math
import numpy as np
MINOVERLAP = 0.5
parser = argparse.ArgumentParser()
parser.add_argument('-na', '--no-animation', help="no animation is shown.", action="store_true")
parser.add_argument('-np', '--no-plot', help="no plot is shown.", action="store_true")
parser.add_argument('-q', '--quiet', help="minimalistic console output.", action="store_true")
parser.add_argument('-i', '--ignore', nargs='+', type=str, help="ignore a list of classes.")
parser.add_argument('--set-class-iou', nargs='+', type=str, help="set IoU for a specific class.")
args = parser.parse_args()
'''
0,0 ------> x (width)
|
| (Left,Top)
| *_________
| | |
| |
y |_________|
(height) *
(Right,Bottom)
'''
if args.ignore is None:
args.ignore = []
specific_iou_flagged = False
if args.set_class_iou is not None:
specific_iou_flagged = True
os.chdir(os.path.dirname(os.path.abspath(__file__)))
GT_PATH = 'D:/ZZZ_My_file/DETR/mAP/GT'
DR_PATH = 'D:/ZZZ_My_file/DETR/mAP/DR'
IMG_PATH = '../dataset/images/test'
if os.path.exists(IMG_PATH):
for dirpath, dirnames, files in os.walk(IMG_PATH):
if not files:
args.no_animation = True
else:
args.no_animation = True
show_animation = False
if not args.no_animation:
try:
import cv2
show_animation = True
except ImportError:
print("\"opencv-python\" not found, please install to visualize the results.")
args.no_animation = True
draw_plot = False
if not args.no_plot:
try:
import matplotlib.pyplot as plt
draw_plot = True
except ImportError:
print("\"matplotlib\" not found, please install it to get the resulting plots.")
args.no_plot = True
def log_average_miss_rate(precision, fp_cumsum, num_images):
"""
log-average miss rate:
Calculated by averaging miss rates at 9 evenly spaced FPPI points
between 10e-2 and 10e0, in log-space.
output:
lamr | log-average miss rate
mr | miss rate
fppi | false positives per image
references:
[1] Dollar, Piotr, et al. "Pedestrian Detection: An Evaluation of the
State of the Art." Pattern Analysis and Machine Intelligence, IEEE
Transactions on 34.4 (2012): 743 - 761.
"""
if precision.size == 0:
lamr = 0
mr = 1
fppi = 0
return lamr, mr, fppi
fppi = fp_cumsum / float(num_images)
mr = (1 - precision)
fppi_tmp = np.insert(fppi, 0, -1.0)
mr_tmp = np.insert(mr, 0, 1.0)
ref = np.logspace(-2.0, 0.0, num=9)
for i, ref_i in enumerate(ref):
j = np.where(fppi_tmp <= ref_i)[-1][-1]
ref[i] = mr_tmp[j]
lamr = math.exp(np.mean(np.log(np.maximum(1e-10, ref))))
return lamr, mr, fppi
"""
throw error and exit
"""
def error(msg):
print(msg)
sys.exit(0)
"""
check if the number is a float between 0.0 and 1.0
"""
def is_float_between_0_and_1(value):
try:
val = float(value)
if val > 0.0 and val < 1.0:
return True
else:
return False
except ValueError:
return False
"""
Calculate the AP given the recall and precision array
1st) We compute a version of the measured precision/recall curve with
precision monotonically decreasing
2nd) We compute the AP as the area under this curve by numerical integration.
"""
def voc_ap(rec, prec):
"""
--- Official matlab code VOC2012---
mrec=[0 ; rec ; 1];
mpre=[0 ; prec ; 0];
for i=numel(mpre)-1:-1:1
mpre(i)=max(mpre(i),mpre(i+1));
end
i=find(mrec(2:end)~=mrec(1:end-1))+1;
ap=sum((mrec(i)-mrec(i-1)).*mpre(i));
"""
rec.insert(0, 0.0) # insert 0.0 at begining of list
rec.append(1.0) # insert 1.0 at end of list
mrec = rec[:]
prec.insert(0, 0.0) # insert 0.0 at begining of list
prec.append(0.0) # insert 0.0 at end of list
mpre = prec[:]
"""
This part makes the precision monotonically decreasing
(goes from the end to the beginning)
matlab: for i=numel(mpre)-1:-1:1
mpre(i)=max(mpre(i),mpre(i+1));
"""
for i in range(len(mpre) - 2, -1, -1):
mpre[i] = max(mpre[i], mpre[i + 1])
"""
This part creates a list of indexes where the recall changes
matlab: i=find(mrec(2:end)~=mrec(1:end-1))+1;
"""
i_list = []
for i in range(1, len(mrec)):
if mrec[i] != mrec[i - 1]:
i_list.append(i) # if it was matlab would be i + 1
"""
The Average Precision (AP) is the area under the curve
(numerical integration)
matlab: ap=sum((mrec(i)-mrec(i-1)).*mpre(i));
"""
ap = 0.0
for i in i_list:
ap += ((mrec[i] - mrec[i - 1]) * mpre[i])
return ap, mrec, mpre
"""
Convert the lines of a file to a list
"""
def file_lines_to_list(path):
# open txt file lines to a list
with open(path) as f:
content = f.readlines()
# remove whitespace characters like `\n` at the end of each line
content = [x.strip() for x in content]
return content
"""
Draws text in image
"""
def draw_text_in_image(img, text, pos, color, line_width):
font = cv2.FONT_HERSHEY_PLAIN
fontScale = 1
lineType = 1
bottomLeftCornerOfText = pos
cv2.putText(img, text,
bottomLeftCornerOfText,
font,
fontScale,
color,
lineType)
text_width, _ = cv2.getTextSize(text, font, fontScale, lineType)[0]
return img, (line_width + text_width)
"""
Plot - adjust axes
"""
def adjust_axes(r, t, fig, axes):
# get text width for re-scaling
bb = t.get_window_extent(renderer=r)
text_width_inches = bb.width / fig.dpi
# get axis width in inches
current_fig_width = fig.get_figwidth()
new_fig_width = current_fig_width + text_width_inches
propotion = new_fig_width / current_fig_width
# get axis limit
x_lim = axes.get_xlim()
axes.set_xlim([x_lim[0], x_lim[1] * propotion])
"""
Draw plot using Matplotlib
"""
def draw_plot_func(dictionary, n_classes, window_title, plot_title, x_label, output_path, to_show, plot_color,
true_p_bar):
# sort the dictionary by decreasing value, into a list of tuples
sorted_dic_by_value = sorted(dictionary.items(), key=operator.itemgetter(1))
# unpacking the list of tuples into two lists
sorted_keys, sorted_values = zip(*sorted_dic_by_value)
#
if true_p_bar != "":
"""
Special case to draw in:
- green -> TP: True Positives (object detected and matches ground-truth)
- red -> FP: False Positives (object detected but does not match ground-truth)
- orange -> FN: False Negatives (object not detected but present in the ground-truth)
"""
fp_sorted = []
tp_sorted = []
for key in sorted_keys:
fp_sorted.append(dictionary[key] - true_p_bar[key])
tp_sorted.append(true_p_bar[key])
plt.barh(range(n_classes), fp_sorted, align='center', color='crimson', label='False Positive')
plt.barh(range(n_classes), tp_sorted, align='center', color='forestgreen', label='True Positive',
left=fp_sorted)
# add legend
plt.legend(loc='lower right')
"""
Write number on side of bar
"""
fig = plt.gcf() # gcf - get current figure
axes = plt.gca()
r = fig.canvas.get_renderer()
for i, val in enumerate(sorted_values):
fp_val = fp_sorted[i]
tp_val = tp_sorted[i]
fp_str_val = " " + str(fp_val)
tp_str_val = fp_str_val + " " + str(tp_val)
# trick to paint multicolor with offset:
# first paint everything and then repaint the first number
t = plt.text(val, i, tp_str_val, color='forestgreen', va='center', fontweight='bold')
plt.text(val, i, fp_str_val, color='crimson', va='center', fontweight='bold')
if i == (len(sorted_values) - 1): # largest bar
adjust_axes(r, t, fig, axes)
else:
plt.barh(range(n_classes), sorted_values, color=plot_color)
"""
Write number on side of bar
"""
fig = plt.gcf() # gcf - get current figure
axes = plt.gca()
r = fig.canvas.get_renderer()
for i, val in enumerate(sorted_values):
str_val = " " + str(val) # add a space before
if val < 1.0:
str_val = " {0:.2f}".format(val)
t = plt.text(val, i, str_val, color=plot_color, va='center', fontweight='bold')
# re-set axes to show number inside the figure
if i == (len(sorted_values) - 1): # largest bar
adjust_axes(r, t, fig, axes)
# set window title
#fig.canvas.set_window_title(window_title)
fig.canvas.manager.window.title(window_title)
# write classes in y axis
tick_font_size = 12
plt.yticks(range(n_classes), sorted_keys, fontsize=tick_font_size)
"""
Re-scale height accordingly
"""
init_height = fig.get_figheight()
# comput the matrix height in points and inches
dpi = fig.dpi
height_pt = n_classes * (tick_font_size * 1.4) # 1.4 (some spacing)
height_in = height_pt / dpi
# compute the required figure height
top_margin = 0.15 # in percentage of the figure height
bottom_margin = 0.05 # in percentage of the figure height
figure_height = height_in / (1 - top_margin - bottom_margin)
# set new height
if figure_height > init_height:
fig.set_figheight(figure_height)
# set plot title
plt.title(plot_title, fontsize=14)
# set axis titles
# plt.xlabel('classes')
plt.xlabel(x_label, fontsize='large')
# adjust size of window
fig.tight_layout()
# save the plot
fig.savefig(output_path)
# show image
if to_show:
plt.show()
# close the plot
plt.close()
"""
Create a ".temp_files/" and "results/" directory
"""
TEMP_FILES_PATH = ".temp_files"
if not os.path.exists(TEMP_FILES_PATH): # if it doesn't exist already
os.makedirs(TEMP_FILES_PATH)
results_files_path = "mAP50"
if os.path.exists(results_files_path): # if it exist already
# reset the results directory
shutil.rmtree(results_files_path)
os.makedirs(results_files_path)
if draw_plot:
os.makedirs(os.path.join(results_files_path, "AP"))
os.makedirs(os.path.join(results_files_path, "F1"))
os.makedirs(os.path.join(results_files_path, "Recall"))
os.makedirs(os.path.join(results_files_path, "Precision"))
if show_animation:
os.makedirs(os.path.join(results_files_path, "images", "detections_one_by_one"))
"""
ground-truth
Load each of the ground-truth files into a temporary ".json" file.
Create a list of all the class names present in the ground-truth (gt_classes).
"""
# get a list with the ground-truth files
ground_truth_files_list = glob.glob(GT_PATH + '/*.txt')
if len(ground_truth_files_list) == 0:
error("Error: No ground-truth files found!")
ground_truth_files_list.sort()
# dictionary with counter per class
gt_counter_per_class = {}
counter_images_per_class = {}
for txt_file in ground_truth_files_list:
# print(txt_file)
file_id = txt_file.split(".txt", 1)[0]
file_id = os.path.basename(os.path.normpath(file_id))
# check if there is a correspondent detection-results file
temp_path = os.path.join(DR_PATH, (file_id + ".txt"))
if not os.path.exists(temp_path):
error_msg = "Error. File not found: {}\n".format(temp_path)
error_msg += "(You can avoid this error message by running extra/intersect-gt-and-dr.py)"
error(error_msg)
lines_list = file_lines_to_list(txt_file)
# create ground-truth dictionary
bounding_boxes = []
is_difficult = False
already_seen_classes = []
for line in lines_list:
try:
if "difficult" in line:
class_name, left, top, right, bottom, _difficult = line.split()
is_difficult = True
else:
class_name, left, top, right, bottom = line.split()
except:
if "difficult" in line:
line_split = line.split()
_difficult = line_split[-1]
bottom = line_split[-2]
right = line_split[-3]
top = line_split[-4]
left = line_split[-5]
class_name = ""
for name in line_split[:-5]:
class_name += name + " "
class_name = class_name[:-1]
is_difficult = True
else:
line_split = line.split()
bottom = line_split[-1]
right = line_split[-2]
top = line_split[-3]
left = line_split[-4]
class_name = ""
for name in line_split[:-4]:
class_name += name + " "
class_name = class_name[:-1]
if class_name in args.ignore:
continue
bbox = left + " " + top + " " + right + " " + bottom
if is_difficult:
bounding_boxes.append({"class_name": class_name, "bbox": bbox, "used": False, "difficult": True})
is_difficult = False
else:
bounding_boxes.append({"class_name": class_name, "bbox": bbox, "used": False})
if class_name in gt_counter_per_class:
gt_counter_per_class[class_name] += 1
else:
gt_counter_per_class[class_name] = 1
if class_name not in already_seen_classes:
if class_name in counter_images_per_class:
counter_images_per_class[class_name] += 1
else:
counter_images_per_class[class_name] = 1
already_seen_classes.append(class_name)
with open(TEMP_FILES_PATH + "/" + file_id + "_ground_truth.json", 'w') as outfile:
json.dump(bounding_boxes, outfile)
gt_classes = list(gt_counter_per_class.keys())
gt_classes = sorted(gt_classes)
n_classes = len(gt_classes)
"""
Check format of the flag --set-class-iou (if used)
e.g. check if class exists
"""
if specific_iou_flagged:
n_args = len(args.set_class_iou)
error_msg = \
'\n --set-class-iou [class_1] [IoU_1] [class_2] [IoU_2] [...]'
if n_args % 2 != 0:
error('Error, missing arguments. Flag usage:' + error_msg)
# [class_1] [IoU_1] [class_2] [IoU_2]
# specific_iou_classes = ['class_1', 'class_2']
specific_iou_classes = args.set_class_iou[::2] # even
# iou_list = ['IoU_1', 'IoU_2']
iou_list = args.set_class_iou[1::2] # odd
if len(specific_iou_classes) != len(iou_list):
error('Error, missing arguments. Flag usage:' + error_msg)
for tmp_class in specific_iou_classes:
if tmp_class not in gt_classes:
error('Error, unknown class \"' + tmp_class + '\". Flag usage:' + error_msg)
for num in iou_list:
if not is_float_between_0_and_1(num):
error('Error, IoU must be between 0.0 and 1.0. Flag usage:' + error_msg)
"""
detection-results
Load each of the detection-results files into a temporary ".json" file.
"""
dr_files_list = glob.glob(DR_PATH + '/*.txt')
dr_files_list.sort()
for class_index, class_name in enumerate(gt_classes):
bounding_boxes = []
for txt_file in dr_files_list:
file_id = txt_file.split(".txt", 1)[0]
file_id = os.path.basename(os.path.normpath(file_id))
temp_path = os.path.join(GT_PATH, (file_id + ".txt"))
if class_index == 0:
if not os.path.exists(temp_path):
error_msg = "Error. File not found: {}\n".format(temp_path)
error_msg += "(You can avoid this error message by running extra/intersect-gt-and-dr.py)"
error(error_msg)
lines = file_lines_to_list(txt_file)
for line in lines:
try:
tmp_class_name, confidence, left, top, right, bottom = line.split()
except:
line_split = line.split()
bottom = line_split[-1]
right = line_split[-2]
top = line_split[-3]
left = line_split[-4]
confidence = line_split[-5]
tmp_class_name = ""
for name in line_split[:-5]:
tmp_class_name += name + " "
tmp_class_name = tmp_class_name[:-1]
if tmp_class_name == class_name:
bbox = left + " " + top + " " + right + " " + bottom
bounding_boxes.append({"confidence": confidence, "file_id": file_id, "bbox": bbox})
bounding_boxes.sort(key=lambda x: float(x['confidence']), reverse=True)
with open(TEMP_FILES_PATH + "/" + class_name + "_dr.json", 'w') as outfile:
json.dump(bounding_boxes, outfile)
"""
Calculate the AP for each class
"""
sum_AP = 0.0
ap_dictionary = {}
lamr_dictionary = {}
with open(results_files_path + "/results.txt", 'w') as results_file:
results_file.write("# AP and precision/recall per class\n")
count_true_positives = {}
for class_index, class_name in enumerate(gt_classes):
count_true_positives[class_name] = 0
"""
Load detection-results of that class
"""
dr_file = TEMP_FILES_PATH + "/" + class_name + "_dr.json"
dr_data = json.load(open(dr_file))
"""
Assign detection-results to ground-truth objects
"""
nd = len(dr_data)
tp = [0] * nd
fp = [0] * nd
score = [0] * nd
score05_idx = 0
for idx, detection in enumerate(dr_data):
file_id = detection["file_id"]
score[idx] = float(detection["confidence"])
if score[idx] > 0.5:
score05_idx = idx
if show_animation:
ground_truth_img = glob.glob1(IMG_PATH, file_id + ".*")
if len(ground_truth_img) == 0:
error("Error. Image not found with id: " + file_id)
elif len(ground_truth_img) > 1:
error("Error. Multiple image with id: " + file_id)
else:
img = cv2.imread(IMG_PATH + "/" + ground_truth_img[0])
img_cumulative_path = results_files_path + "/images/" + ground_truth_img[0]
if os.path.isfile(img_cumulative_path):
img_cumulative = cv2.imread(img_cumulative_path)
else:
img_cumulative = img.copy()
bottom_border = 60
BLACK = [0, 0, 0]
img = cv2.copyMakeBorder(img, 0, bottom_border, 0, 0, cv2.BORDER_CONSTANT, value=BLACK)
gt_file = TEMP_FILES_PATH + "/" + file_id + "_ground_truth.json"
ground_truth_data = json.load(open(gt_file))
ovmax = -1
gt_match = -1
bb = [float(x) for x in detection["bbox"].split()]
for obj in ground_truth_data:
if obj["class_name"] == class_name:
bbgt = [float(x) for x in obj["bbox"].split()]
bi = [max(bb[0], bbgt[0]), max(bb[1], bbgt[1]), min(bb[2], bbgt[2]), min(bb[3], bbgt[3])]
iw = bi[2] - bi[0] + 1
ih = bi[3] - bi[1] + 1
if iw > 0 and ih > 0:
# compute overlap (IoU) = area of intersection / area of union
ua = (bb[2] - bb[0] + 1) * (bb[3] - bb[1] + 1) + (bbgt[2] - bbgt[0]
+ 1) * (bbgt[3] - bbgt[1] + 1) - iw * ih
ov = iw * ih / ua
if ov > ovmax:
ovmax = ov
gt_match = obj
if show_animation:
status = "NO MATCH FOUND!"
min_overlap = MINOVERLAP
if specific_iou_flagged:
if class_name in specific_iou_classes:
index = specific_iou_classes.index(class_name)
min_overlap = float(iou_list[index])
if ovmax >= min_overlap:
if "difficult" not in gt_match:
if not bool(gt_match["used"]):
tp[idx] = 1
gt_match["used"] = True
count_true_positives[class_name] += 1
with open(gt_file, 'w') as f:
f.write(json.dumps(ground_truth_data))
if show_animation:
status = "MATCH!"
else:
fp[idx] = 1
if show_animation:
status = "REPEATED MATCH!"
else:
fp[idx] = 1
if ovmax > 0:
status = "INSUFFICIENT OVERLAP"
"""
Draw image to show animation
"""
if show_animation:
height, widht = img.shape[:2]
# colors (OpenCV works with BGR)
white = (255, 255, 255)
light_blue = (255, 200, 100)
green = (0, 255, 0)
light_red = (30, 30, 255)
# 1st line
margin = 10
v_pos = int(height - margin - (bottom_border / 2.0))
text = "Image: " + ground_truth_img[0] + " "
img, line_width = draw_text_in_image(img, text, (margin, v_pos), white, 0)
text = "Class [" + str(class_index) + "/" + str(n_classes) + "]: " + class_name + " "
img, line_width = draw_text_in_image(img, text, (margin + line_width, v_pos), light_blue, line_width)
if ovmax != -1:
color = light_red
if status == "INSUFFICIENT OVERLAP":
text = "IoU: {0:.2f}% ".format(ovmax * 100) + "< {0:.2f}% ".format(min_overlap * 100)
else:
text = "IoU: {0:.2f}% ".format(ovmax * 100) + ">= {0:.2f}% ".format(min_overlap * 100)
color = green
img, _ = draw_text_in_image(img, text, (margin + line_width, v_pos), color, line_width)
# 2nd line
v_pos += int(bottom_border / 2.0)
rank_pos = str(idx + 1) # rank position (idx starts at 0)
text = "Detection #rank: " + rank_pos + " confidence: {0:.2f}% ".format(
float(detection["confidence"]) * 100)
img, line_width = draw_text_in_image(img, text, (margin, v_pos), white, 0)
color = light_red
if status == "MATCH!":
color = green
text = "Result: " + status + " "
img, line_width = draw_text_in_image(img, text, (margin + line_width, v_pos), color, line_width)
font = cv2.FONT_HERSHEY_SIMPLEX
if ovmax > 0: # if there is intersections between the bounding-boxes
bbgt = [int(round(float(x))) for x in gt_match["bbox"].split()]
cv2.rectangle(img, (bbgt[0], bbgt[1]), (bbgt[2], bbgt[3]), light_blue, 2)
cv2.rectangle(img_cumulative, (bbgt[0], bbgt[1]), (bbgt[2], bbgt[3]), light_blue, 2)
cv2.putText(img_cumulative, class_name, (bbgt[0], bbgt[1] - 5), font, 0.6, light_blue, 1,
cv2.LINE_AA)
bb = [int(i) for i in bb]
cv2.rectangle(img, (bb[0], bb[1]), (bb[2], bb[3]), color, 2)
cv2.rectangle(img_cumulative, (bb[0], bb[1]), (bb[2], bb[3]), color, 2)
cv2.putText(img_cumulative, class_name, (bb[0], bb[1] - 5), font, 0.6, color, 1, cv2.LINE_AA)
# show image
cv2.imshow("Animation", img)
cv2.waitKey(20) # show for 20 ms
# save image to results
output_img_path = results_files_path + "/images/detections_one_by_one/" + class_name + "_detection" + str(
idx) + ".jpg"
cv2.imwrite(output_img_path, img)
# save the image with all the objects drawn to it
cv2.imwrite(img_cumulative_path, img_cumulative)
cumsum = 0
for idx, val in enumerate(fp):
fp[idx] += cumsum
cumsum += val
cumsum = 0
for idx, val in enumerate(tp):
tp[idx] += cumsum
cumsum += val
rec = tp[:]
for idx, val in enumerate(tp):
rec[idx] = float(tp[idx]) / np.maximum(gt_counter_per_class[class_name], 1)
prec = tp[:]
for idx, val in enumerate(tp):
prec[idx] = float(tp[idx]) / np.maximum((fp[idx] + tp[idx]), 1)
ap, mrec, mprec = voc_ap(rec[:], prec[:])
F1 = np.array(rec) * np.array(prec) * 2 / np.where((np.array(prec) + np.array(rec)) == 0, 1,
(np.array(prec) + np.array(rec)))
sum_AP += ap
text = "{0:.2f}%".format(ap * 100) + " = " + class_name + " AP " # class_name + " AP = {0:.2f}%".format(ap*100)
if len(prec) > 0:
F1_text = "{0:.2f}".format(F1[score05_idx]) + " = " + class_name + " F1 "
Recall_text = "{0:.2f}%".format(rec[score05_idx] * 100) + " = " + class_name + " Recall "
Precision_text = "{0:.2f}%".format(prec[score05_idx] * 100) + " = " + class_name + " Precision "
else:
F1_text = "0.00" + " = " + class_name + " F1 "
Recall_text = "0.00%" + " = " + class_name + " Recall "
Precision_text = "0.00%" + " = " + class_name + " Precision "
rounded_prec = ['%.2f' % elem for elem in prec]
rounded_rec = ['%.2f' % elem for elem in rec]
results_file.write(text + "\n Precision: " + str(rounded_prec) + "\n Recall :" + str(rounded_rec) + "\n\n")
if not args.quiet:
if len(prec) > 0:
print(text + "\t||\tscore_threhold=0.5 : " + "F1=" + "{0:.2f}".format(F1[score05_idx]) \
+ " ; Recall=" + "{0:.2f}%".format(rec[score05_idx] * 100) + " ; Precision=" + "{0:.2f}%".format(
prec[score05_idx] * 100))
else:
print(text + "\t||\tscore_threhold=0.5 : F1=0.00% ; Recall=0.00% ; Precision=0.00%")
ap_dictionary[class_name] = ap
n_images = counter_images_per_class[class_name]
lamr, mr, fppi = log_average_miss_rate(np.array(rec), np.array(fp), n_images)
lamr_dictionary[class_name] = lamr
"""
Draw plot
"""
if draw_plot:
plt.plot(rec, prec, '-o')
area_under_curve_x = mrec[:-1] + [mrec[-2]] + [mrec[-1]]
area_under_curve_y = mprec[:-1] + [0.0] + [mprec[-1]]
plt.fill_between(area_under_curve_x, 0, area_under_curve_y, alpha=0.2, edgecolor='r')
fig = plt.gcf()
#fig.canvas.set_window_title('AP ' + class_name)
plt.title('class: ' + text)
plt.xlabel('Recall')
plt.ylabel('Precision')
axes = plt.gca()
axes.set_xlim([0.0, 1.0])
axes.set_ylim([0.0, 1.05])
fig.savefig(results_files_path + "/AP/" + class_name + ".png")
plt.cla()
plt.plot(score, F1, "-", color='orangered')
plt.title('class: ' + F1_text + "\nscore_threhold=0.5")
plt.xlabel('Score_Threhold')
plt.ylabel('F1')
axes = plt.gca()
axes.set_xlim([0.0, 1.0])
axes.set_ylim([0.0, 1.05])
fig.savefig(results_files_path + "/F1/" + class_name + ".png")
plt.cla()
plt.plot(score, rec, "-H", color='gold')
plt.title('class: ' + Recall_text + "\nscore_threhold=0.5")
plt.xlabel('Score_Threhold')
plt.ylabel('Recall')
axes = plt.gca()
axes.set_xlim([0.0, 1.0])
axes.set_ylim([0.0, 1.05])
fig.savefig(results_files_path + "/Recall/" + class_name + ".png")
plt.cla()
plt.plot(score, prec, "-s", color='palevioletred')
plt.title('class: ' + Precision_text + "\nscore_threhold=0.5")
plt.xlabel('Score_Threhold')
plt.ylabel('Precision')
axes = plt.gca()
axes.set_xlim([0.0, 1.0])
axes.set_ylim([0.0, 1.05])
fig.savefig(results_files_path + "/Precision/" + class_name + ".png")
plt.cla()
if show_animation:
cv2.destroyAllWindows()
results_file.write("\n# mAP50 of all classes\n")
mAP = sum_AP / n_classes
text = "mAP50 = {0:.2f}%".format(mAP * 100)
results_file.write(text + "\n")
print(text)
# remove the temp_files directory
shutil.rmtree(TEMP_FILES_PATH)
"""
Count total of detection-results
"""
# iterate through all the files
det_counter_per_class = {}
for txt_file in dr_files_list:
# get lines to list
lines_list = file_lines_to_list(txt_file)
for line in lines_list:
class_name = line.split()[0]
# check if class is in the ignore list, if yes skip
if class_name in args.ignore:
continue
# count that object
if class_name in det_counter_per_class:
det_counter_per_class[class_name] += 1
else:
# if class didn't exist yet
det_counter_per_class[class_name] = 1
# print(det_counter_per_class)
dr_classes = list(det_counter_per_class.keys())
"""
Plot the total number of occurences of each class in the ground-truth
"""
if draw_plot:
window_title = "ground-truth-info"
plot_title = "ground-truth\n"
plot_title += "(" + str(len(ground_truth_files_list)) + " files and " + str(n_classes) + " classes)"
x_label = "Number of objects per class"
output_path = results_files_path + "/ground-truth-info.png"
to_show = False
plot_color = 'forestgreen'
draw_plot_func(
gt_counter_per_class,
n_classes,
window_title,
plot_title,
x_label,
output_path,
to_show,
plot_color,
'',
)
"""
Write number of ground-truth objects per class to results.txt
"""
with open(results_files_path + "/results.txt", 'a') as results_file:
results_file.write("\n# Number of ground-truth objects per class\n")
for class_name in sorted(gt_counter_per_class):
results_file.write(class_name + ": " + str(gt_counter_per_class[class_name]) + "\n")
"""
Finish counting true positives
"""
for class_name in dr_classes:
# if class exists in detection-result but not in ground-truth then there are no true positives in that class
if class_name not in gt_classes:
count_true_positives[class_name] = 0
# print(count_true_positives)
"""
Plot the total number of occurences of each class in the "detection-results" folder
"""
if draw_plot:
window_title = "detection-results-info"
# Plot title
plot_title = "detection-results\n"
plot_title += "(" + str(len(dr_files_list)) + " files and "
count_non_zero_values_in_dictionary = sum(int(x) > 0 for x in list(det_counter_per_class.values()))
plot_title += str(count_non_zero_values_in_dictionary) + " detected classes)"
# end Plot title
x_label = "Number of objects per class"
output_path = results_files_path + "/detection-results-info.png"
to_show = False
plot_color = 'forestgreen'
true_p_bar = count_true_positives
draw_plot_func(
det_counter_per_class,
len(det_counter_per_class),
window_title,
plot_title,
x_label,
output_path,
to_show,
plot_color,
true_p_bar
)
"""
Write number of detected objects per class to results.txt
"""
with open(results_files_path + "/results.txt", 'a') as results_file:
results_file.write("\n# Number of detected objects per class\n")
for class_name in sorted(dr_classes):
n_det = det_counter_per_class[class_name]
text = class_name + ": " + str(n_det)
text += " (tp:" + str(count_true_positives[class_name]) + ""
text += ", fp:" + str(n_det - count_true_positives[class_name]) + ")\n"
results_file.write(text)
"""
Draw log-average miss rate plot (Show lamr of all classes in decreasing order)
"""
if draw_plot:
window_title = "lamr"
plot_title = "log-average miss rate"
x_label = "log-average miss rate"
output_path = results_files_path + "/lamr.png"
to_show = False
plot_color = 'royalblue'
draw_plot_func(
lamr_dictionary,
n_classes,
window_title,
plot_title,
x_label,
output_path,
to_show,
plot_color,
""
)
"""
Draw mAP50 plot (Show AP's of all classes in decreasing order)
"""
if draw_plot:
window_title = "mAP50"
plot_title = "mAP50 = {0:.2f}%".format(mAP * 100)
x_label = "Average Precision"
output_path = results_files_path + "/mAP50.png"
to_show = True
plot_color = 'royalblue'
draw_plot_func(
ap_dictionary,
n_classes,
window_title,
plot_title,
x_label,
output_path,
to_show,
plot_color,
""
)
运行结果如图:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









