







目标检测算法-transformer系列-DETR论文解析(附论文与源码)
一,DETR:
前言
之前我们介绍的目标检测算法都是基于卷积网络的,近年来Transformer被广泛的应用到计算机视觉的物体分类领域,例如iGPT,ViT等。这里要介绍的DETR是第一篇将Transformer应用到目标检测方向的算法。DETR是一个经典的Encoder-Decoder结构的算法,它的骨干网络是一个卷积网络,Encoder和Decoder则是两个基于Transformer的结构。DETR的输出层则是一个MLP。
DETR使用了一个基于二部图匹配(bipartite matching)的损失函数,这个二部图是基于ground truth和预测的bounding box进行匹配的。
1. 网络结构
DETR的网络结构如图1所示,从图中可以看出DETR由四个主要模块组成:backbone,编码器,解码器以及预测头。
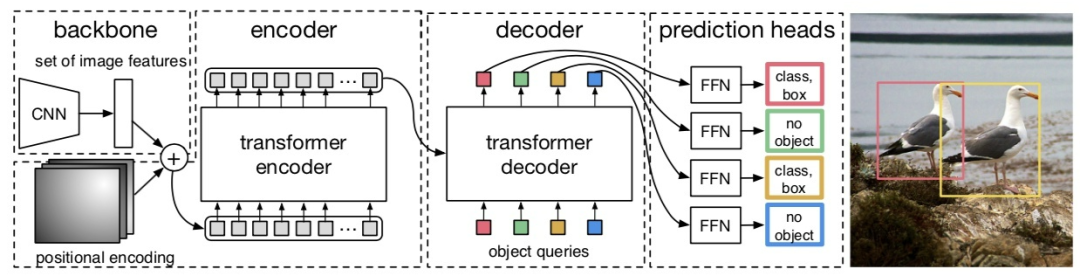
图1:DETR的预测流程
1.1 骨干网络
DETR的骨干网络是经典的卷积网络,它的输入定义为:Ximg∈3×H0×W0,它的输出是降采样32 倍的Feature Map,表示为:f∈C×H×W,其中C=2048 , H =H_0/32以及W=W_0/32 。在实验中作者使用的是ResNet-50或者ResNet-101作为基础网络。
1.2 Transformer编码器
Transformer编码器的详细结构如图2左侧部分所示。在得到Feature Map之后,DETR首先通过一个1×1卷积将其通道数调整为更小的d ,得到一个大小为d×H×W的新的Feature Map。DETR的下一步则是将其转换为序列数据,这一步是通过reshape操作完成的,转换之后的数据维度是d×H×W。因为Transformer是与输入数据的顺序无关的,因此它需要加上位置编码加入位置信息。这一部分会作为编码器的输入。DETR的编码器的Transformer使用的是多头自注意力模型加上一个MLP。
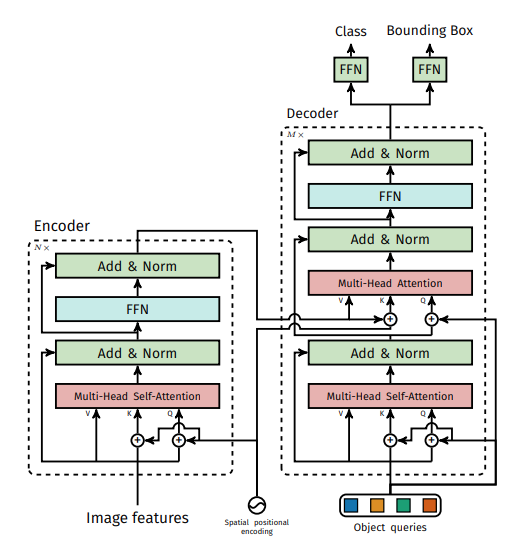
图2:DETR的编码器和解码器的网络结构
DETR的位置编码是分别计算了两个维度的位置编码,然后将它们拼接到一起。其中每个维度的位置编码使用的是和Transformer相同的计算方式。
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
1.3 Transformer解码器
DETR的解码器如图2右侧部分所示,它有两个输入,一个是编码器得到的特征,另外一个是object querie。这里我们重点讲一下object queries。
在DETR中,object queries的作用类似于基于CNN的目标检测算法中的anchor boxes。它共有N个( N 是一个事先设定好的超参,它的值远大于一个图片中的目标数)。N个不同的object queries输入的解码器中便会得到N个decoder output embedding,它们经过最后的MLP得到N个预测结果。不同的N个Object queries保证了N个不同的预测结果,Object queries是一个可以训练的嵌入向量,它通过和ground truth的匈牙利匹配来向不同的ground truth进行优化。
注意这N个结果不是顺序得到的,而是一次性得到N 个结果,这点和原始的Transformer的自回归计算是不同的。
1.4 MLP预测头
预测头是一个3层的Perceptron,激活函数使用的是ReLU,隐层节点数是 d 。每个Object queries通过预测头预测目标的bounding box和类别,其中bounding box有三个值,分别是目标的中心点以及宽和高。DETR共预测N个bounding box,N是一个远大于图片中目标个数的值,超过目标个数的ground truth使用背景元素来作为负样本。
2. 损失函数
2.1 目标检测
通过上面对DETR的模型的分析我们知道对于一张图片DETR会输出 N 个不同的bounding box,那么我们如何评估这N个bounding box的效果的好坏呢?在DETR中的策略是对这N个bounding box以及生成的N个ground truth进行最优二部图匹配,并根据匹配的结果计算loss来对模型进行优化。
上面提到了计算loss需要生成N个ground truth,但是一张图片的待检测目标的个数往往是不足N个的。为了解决这个问题,DETR构造了一个新的类ϕ,它表示没有目标物体的背景类。通过调整ϕ中的样本的大小我们可以将ground truth的样本数可控制在 N个,这样我们便得到了两个等容量的集合。
有了这 N 个ground truth,那么我们只要定义好ground truth和bounding box的匹配代价,便可以使用匈牙利匹配算法来得到ground truth和bounding box的最优二部图匹配方案了。
Bounding box和ground truth的匹配代价表示为式(1):
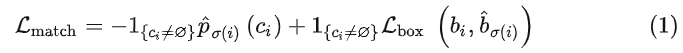
其中1{ci≠∅}是一个bool函数,当ci≠∅时为1 ,否则为0 。ci是第 i 个物体的类别标签。σ(i)是与第i个目标匹配的bounding box的index。
![]()
表示DETR预测的第σ(i)个预测的bounding box的类别为ci的概率。bi 和![]() 分别是第 i 个目标的位置的ground truth的坐标(中心点,宽,高)和预测的bounding box的坐标。
分别是第 i 个目标的位置的ground truth的坐标(中心点,宽,高)和预测的bounding box的坐标。
![]()
是两个矩形框之间的距离,下面我们详细介绍它。
![]()
由IoU损失和l1损失构成,它们通过
![]()
和
![]()
来控制两个损失的权值,表示为式(2):
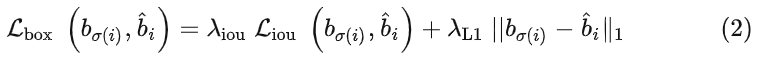
其中
![]()
使用的是GIoU损失,表示为式(3):
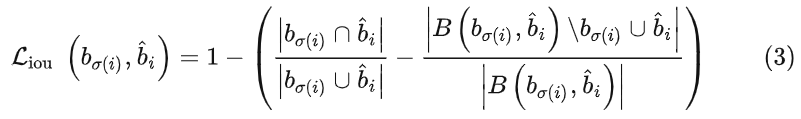
当我们通过上面的策略得到ground truth和预测bounding box的最优二部图匹配后,便可以根据匹配的结果计算损失函数了。DETR的损失函数和匹配代价非常类似,不同的是它的类别预测使用的是对数似然,表示为式(4)。
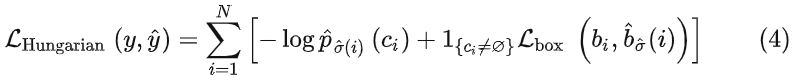
它们另外一个不同是bool函数作用的位置不同,在Lmatch中背景目标不参与匹配代价的计算,LHungarian则也要计算背景目标的分类损失。
2.2 全景分割
DETR的另一个应用场景是全景分割(panoptic segmentation),全景分割是继语义分割和实例分割之后的另一个更难的分割任务,它需要给图像中的每个像素点分配一个语义标签和一个实例id。其中语义标签是物体的类别,实例id是每个不同物体对应的编号。
在DETR中,它将全景分割任务分成 N 个在每个bounding box上的两个类别的分割任务,如图8所示。首先通过CNN将图像编码降采样的Feature Map,然后通过一组多头自注意力将Feature Map和bounding box的位置编码信息作为输入得到 NxM个小尺寸的Attention Maps。再通过一组类似FPN的架构将图像上采样的原图的1/4,得到 N 个mask logits,最后通过按像素点取softmax得到最终的分割效果。
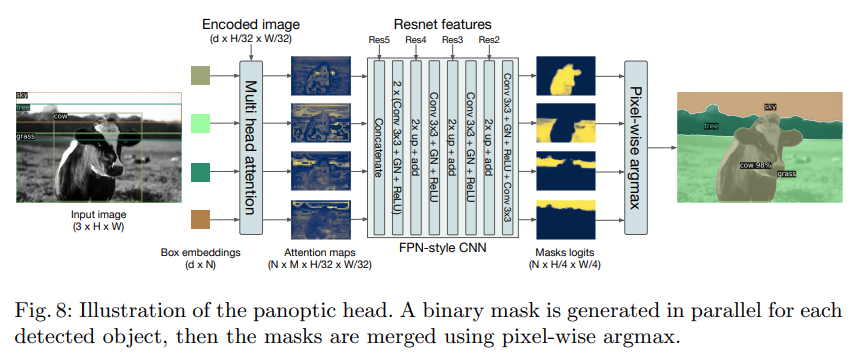
图8:DETR用于全景分割的输出头
骰子损失(DICE Loss)是在V-Net中提出的类似于IoU损失的专门用于分割任务的损失函数,它的主要应用场景是分割任务中类别不平衡的问题。DICE损失来自于DICE系数(DICE coefficient),也称索伦森-骰子系数(Sørensen–Dice coefficient),它是一个集合相似度的衡量函数,通常用来计算两个样本的相似度。
DETR的分割任务使用的损失函数表示为式(5)。
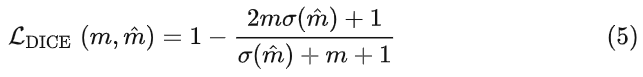
其中σ是sigmoid激活函数。
3. 总结
DETR是第一个将Transformer应用到目标检测的算法。在DETR中,它的Encoder可以看做一个编码器,图像经过由CNN和Transformer组成的解码器之后,将图像编码成一个特征向量。然后解码器通过对输入特征和不同的object queries得到不同的解码的特征向量。最后通过将这个解码的特征向量输入到MLP中得到 N 个不同的bounding box的坐标和类别。从上面角度看DETR也可以应用到其它任务中,它只需要根据不同的任务使用不同输出结果的MLP即可。
二,相关地址:
论文地址:https://arxiv.org/pdf/2005.12872v3.pdf
代码地址:https://github.com/facebookresearch/detr
三,参考文章:
https://arxiv.org/pdf/2005.12872v3.pdf
https://zhuanlan.zhihu.com/p/590462121
https://www.zhihu.com/search?q=DETR&utm_content=search_history&type=content

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









