






HELLO大家好,我是图欧君!
最近有小伙伴在群里说要求出一期关于AI知识库的教程,图欧君向来有求必应。
在精心的筹备之后,这它不就来啦~

当今环境,所有人都面临一个问题:信息过载。不知道你是否曾经遇到过以下困扰?
-
在海量数据中搜索时,是否难以迅速找到所需的信息?
-
在面对日益增长的专业知识,是否感到知识管理的需求愈发迫切?
-
对于敏感数据的存储,是否时常害怕一不小心就会泄露关键信息?
-
在日常工作中,是否因为工作效率不高而觉得时间不够用?

如果这些场景让你感同身受,那么你一定在思考:是否存在一种方案,能够一举解决这些棘手的问题?
经过图欧君的研究,发现确实有这么一个方案,它就是基于 FastGPT 搭建本地私有化知识库,一个为你量身定制专属的知识管理解决方案。
下面图欧君将带领大家揭示如何结合FastGPT、大语言模型和向量模型,构建属于你自己的本地私有化知识库。
话不多说,正文开始。
安装部署FastGPT
什么是FastGPT?FastGPT,是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。
同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
FastGPT 在线使用地址:https://cloud.fastgpt.in/login
FastGPT 在线GitHub地址:https://github.com/labring/FastGPT

推荐配置
为了满足广大用户的具体需求,FastGPT提供了PgVector、Milvus和zilliz cloud三种版本可供选择。我们可以根据自己的数据规模和性能要求,灵活地在Linux、Windows、Mac等不同的操作系统环境中部署合适的版本。
「PgVector版本」 —— 针对初体验与测试的完美起点
PgVector版本是进行初步体验和测试的理想选择。它简便易用,适合处理中小规模的向量数据,能够迅速掌握并开始工作。
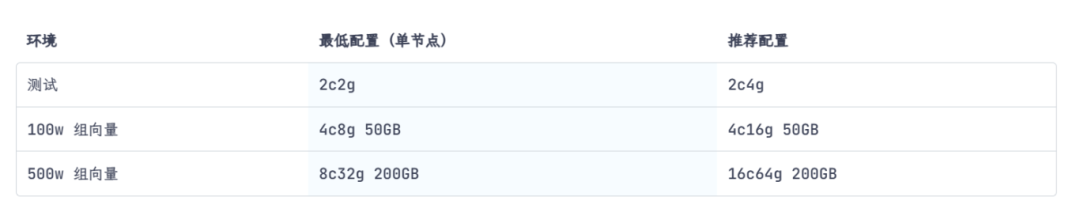
「Milvus版本」 —— 专为千万级向量数据设计的性能强者
当数据处理需求升级至千万级以上,Milvus版本较之其他版本具有卓越的性能优势,是处理大规模向量数据的首选方案。

「zilliz cloud版本」 —— 亿级向量数据的专业云服务解决方案
对于处理亿级及更高量级的海量向量数据,zilliz cloud版本提供了专业的云服务支持,确保您能够获得高效且稳定的数据处理体验。得益于向量库使用了 Cloud,无需占用本地资源,无需太关注配置。
环境准备
FastGpt的部署重度依赖于Docker环境。因此,在本地系统或所管理的服务器上安装Docker环境是确保FastGpt顺畅运行的必要条件。

什么是Docker?这么说吧,FastGpt就像一款需要特定玩具盒子才能玩的电子游戏。这个特定的玩具盒子的名字就叫“Docker”。所以,如果我们想在我们的电脑或服务器上顺利地运行FastGpt,就必须先安装这个玩具盒子,这样FastGpt才能正确地工作。
Windows 系统安装 Docker
在 Windows 系统上,建议将源代码和其他数据绑定到 Linux 容器时,使用 Linux 文件系统而非 Windows 文件系统,以避免兼容性问题。
-
「使用 Docker Desktop」
「推荐使用 WSL 2 后端」:可以通过 Docker 官方文档在 Windows 中安装 Docker Desktop。具体步骤请参考**:****https://docs.docker.com/desktop/wsl/**。
-
「使用命令行版本的 Docker」
「直接在 WSL 2 中安装」:如果不希望使用 Docker Desktop,也可以选择在 WSL 2 中直接安装命令行版本的 Docker。详细安装步骤请参考:https://nickjanetakis.com/blog/install-docker-in-wsl-2-without-docker-desktop。
macOS 系统安装 Docker
对于 macOS 用户,推荐使用 Orbstack 来安装 Docker。
- 「通过 Orbstack 安装」:
- 访问 Orbstack 官网 **(https://orbstack.dev/)**按照指示进行安装。
-
「通过 Homebrew 安装」:
brew install orbstack
- 在终端运行以上命令
Linux 系统安装 Docker
在 Linux 系统上安装 Docker 的步骤如下:
-
「打开终端,运行以下命令来安装 Docker:」
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun systemctl enable --now docker -
「接着安装
**docker-compose**:」`curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose ` -
「验证安装是否成功」:
docker -v docker-compose -v
- 运行以上命令来验证 Docker 和 docker-compose 是否正确安装
开始部署
-
下载
**docker-compose.yml**文件
首先,我们需要访问 FastGPT 的 GitHub 仓库。在仓库的根目录中找到**docker-compose.yml**文件。点击文件,然后点击 “Raw”(原始)按钮,文件内容将显示在浏览器中。接下来,右键点击页面,选择 “保存为”,将其保存到您的计算机上。 -
修改
**docker-compose.yml**环境变量
使用文本编辑器(如记事本、Notepad++、VSCode 等)打开下载的**docker-compose.yml**文件,接下来在文件中找到与向量库版本相关的部分。根据您选择的向量库(PgVector、Milvus 或 Zilliz),您需要修改相应的环境变量。注意:如果选择的是 Zilliz 版本,则需要找到包含
**MILVUS_ADDRESS**和**MILVUS_TOKEN**的行,将它们修改为您的 Milvus 服务地址和认证令牌,而另外的两个版本无需修改。 -
启动容器
打开命令行工具(如终端、命令提示符或 PowerShell)。
使用**cd**命令切换到包含**docker-compose.yml**文件的目录。例如:cd path/to/your/docker-compose.yml/directory然后运行以下命令来启动容器:
docker-compose up -d这个命令会在后台启动所有定义在
**docker-compose.yml**文件中的服务。 -
打开 OneAPI 添加模型
在浏览器中输入您的服务器 IP 地址后跟**:3001**,例如**http://192.168.1.100:3001**。
然后使用默认账号**root**和密码**123456**登录 OneAPI。登录后,根据指示添加 AI 模型渠道。 -
访问 FastGPT
在浏览器中输入您的服务器 IP 地址后跟**:3000**,例如**http://192.168.1.100:3000**。
使用默认用户名**root**和在**docker-compose.yml**文件中设置的**DEFAULT_ROOT_PSW**密码登录 FastGPT。 -
至此,FastGPT安装部署大功告成!

搭建私有化知识库
当第一次打开网站时,我们会发现界面一片白花花的啥也没有。这个时候,不要慌,来跟我按照以下步骤来搞定你的第一个个人知识库!
-
在左侧菜单栏选择“知识库”选项。
-
点击页面右上角的“新建”,开始构建您的第一个知识库。
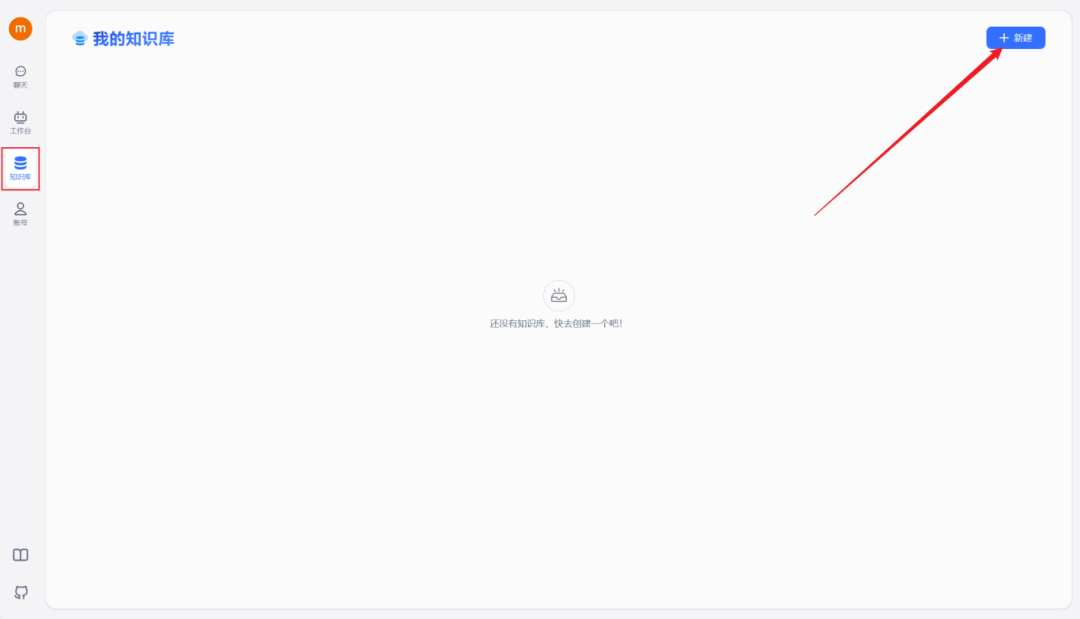
在此过程中,可以根据自身的需求选择合适的知识库类型。紧接着确定我们的知识库名称、索引模型和文件处理模型。
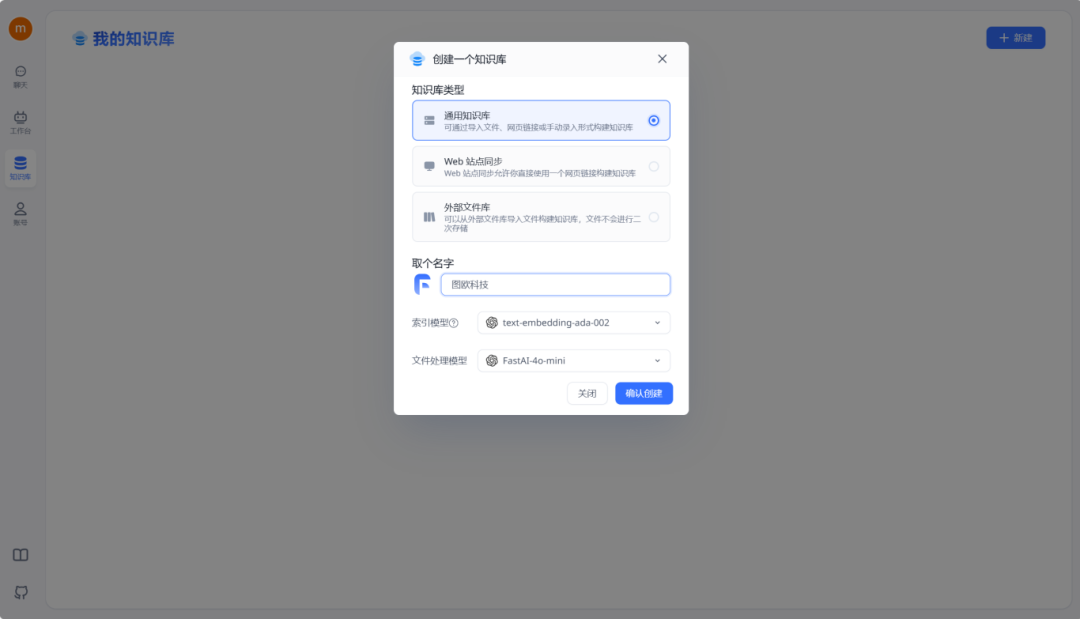
完成创建后,点击右上角的“新建/导入”,根据您的数据集类型选择相应的导入选项。
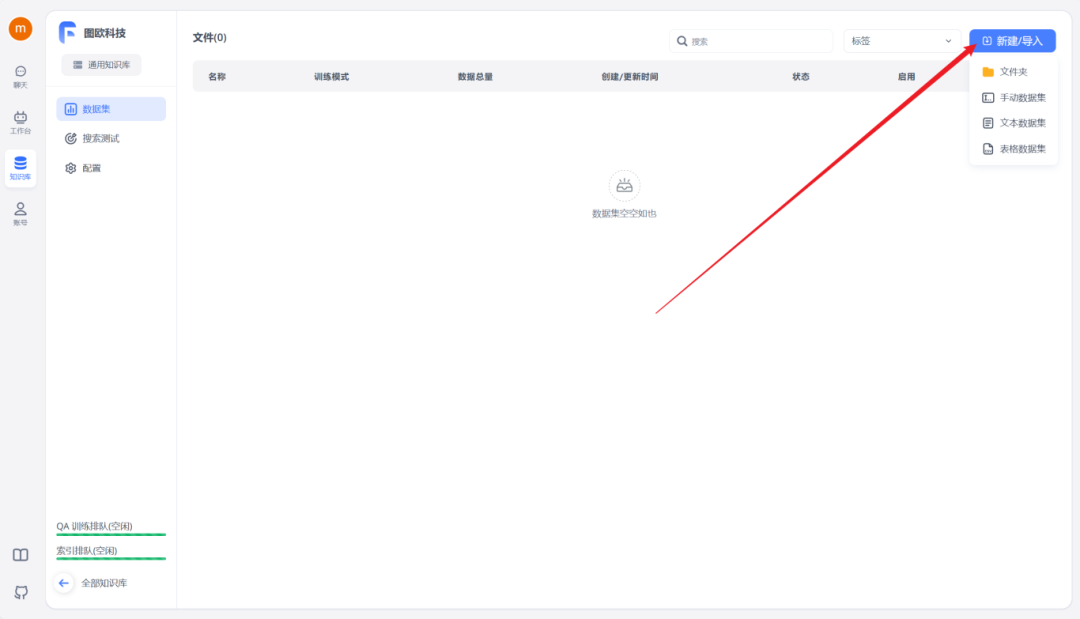
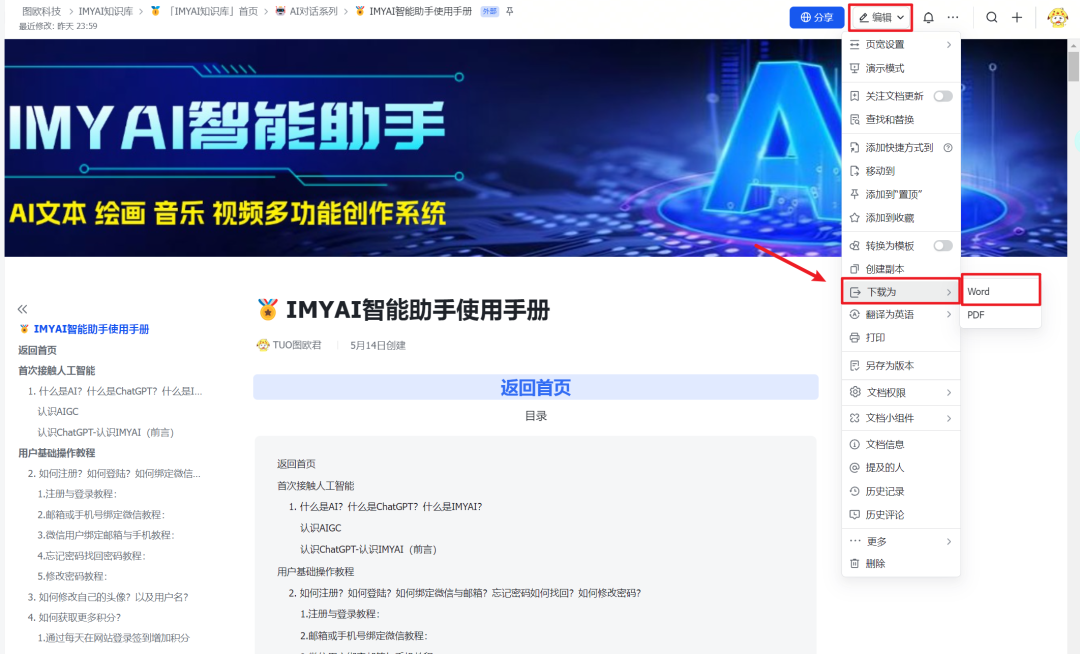
首先需要准备好知识库数据集,可以为DOCX、TXT或者PDF格式,然后选择文本数据集,选择本地文件导入。这里图欧君以咱们的IMYAI知识库为例子,进入飞书云文档《IMYAI智能助手使用手册》之后点击右上角导出为Word文档,文档权限我已经开放为人人都可以创建副本,导出下载,这个大可放心。
IMYAI知识库地址:https://new.imyai.top
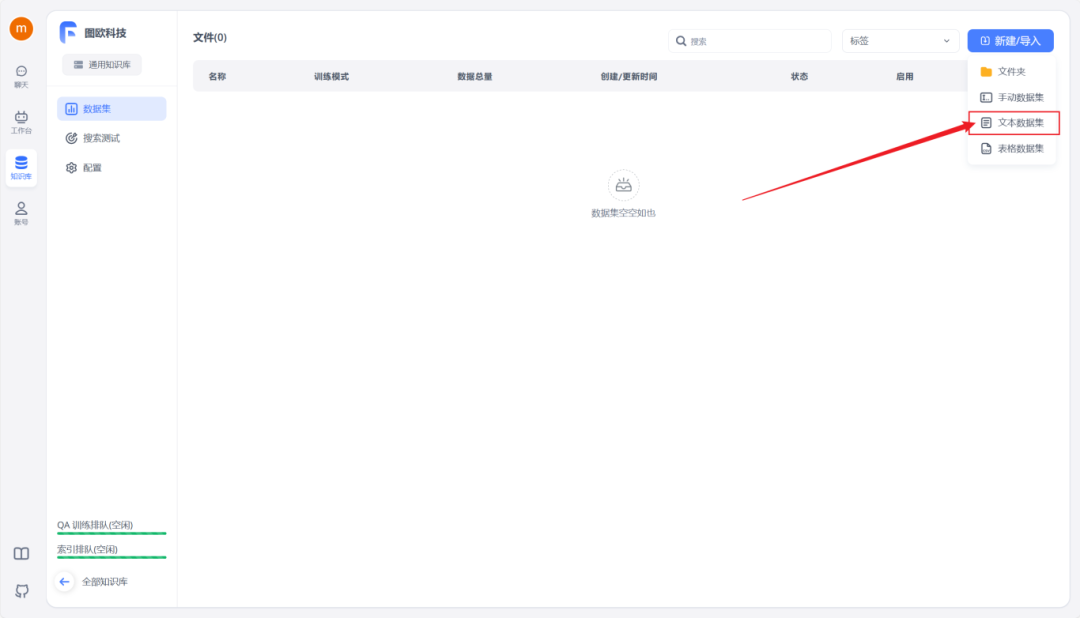
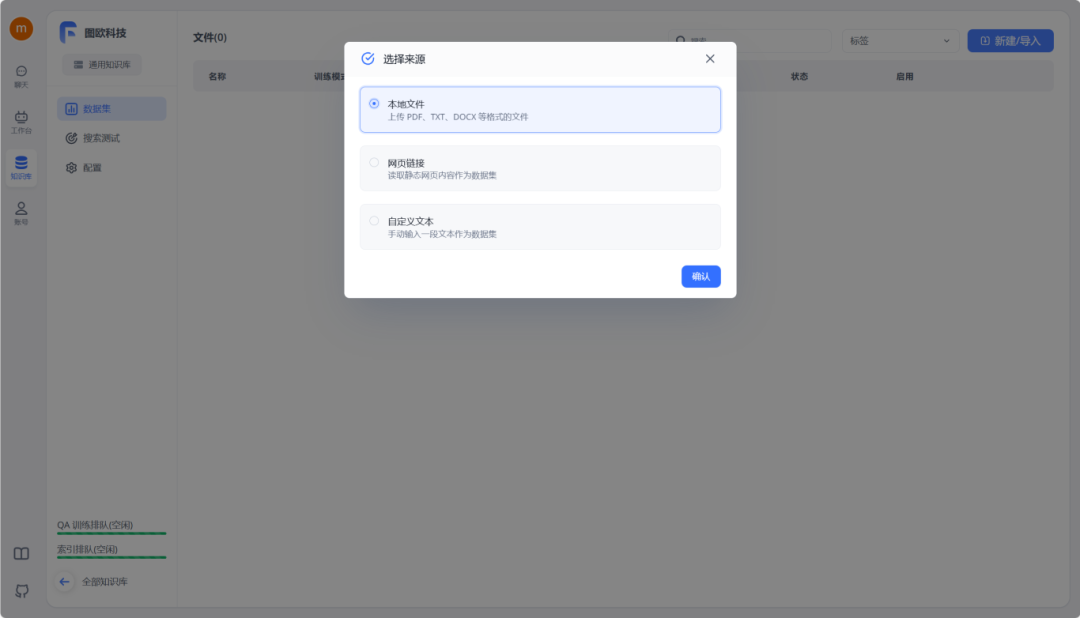
等待数据处理并成功上传后,状态栏将显示“已就绪”,这时知识库搭建就完成了。
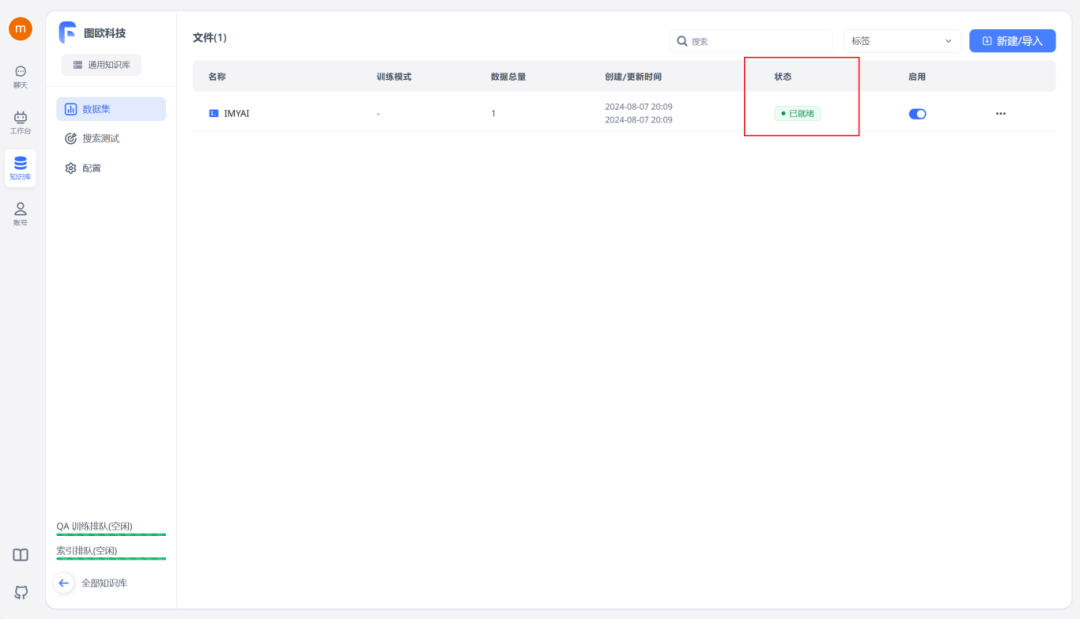
知识库搭建完成之后就可以转到工作台栏进行应用的创建了,一共是提供了四种类型的应用可供我们选择,只需根据自己的需要选择合适的应用即可,图欧君在这里选择了简易应用做个示范。
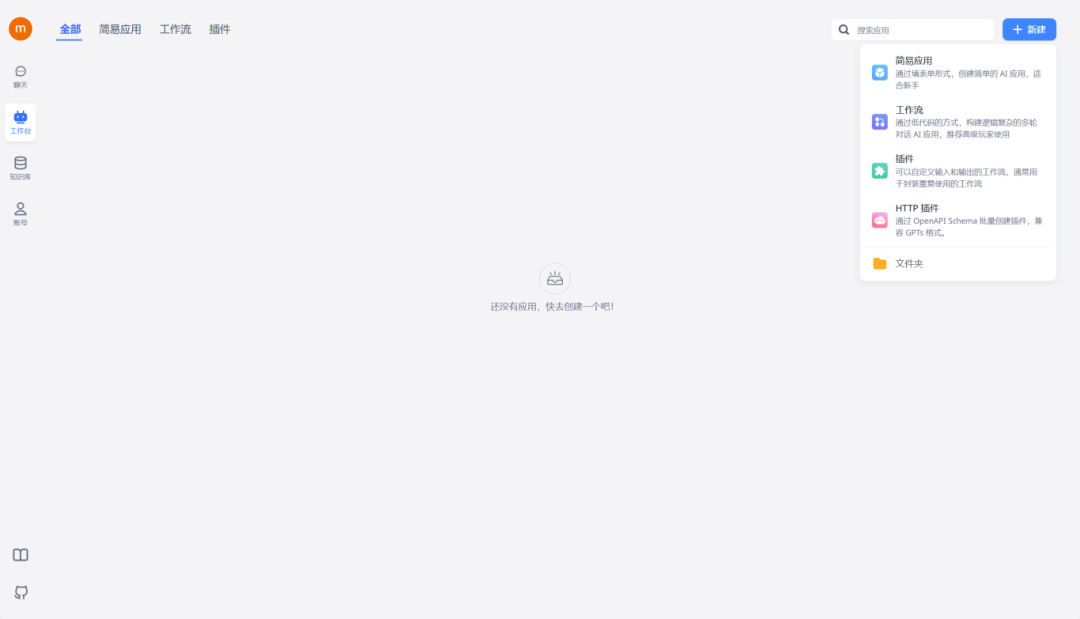
左侧你可以对创建的应用进行一些配置,最后不要忘了把刚刚建立的知识库,关联进来。
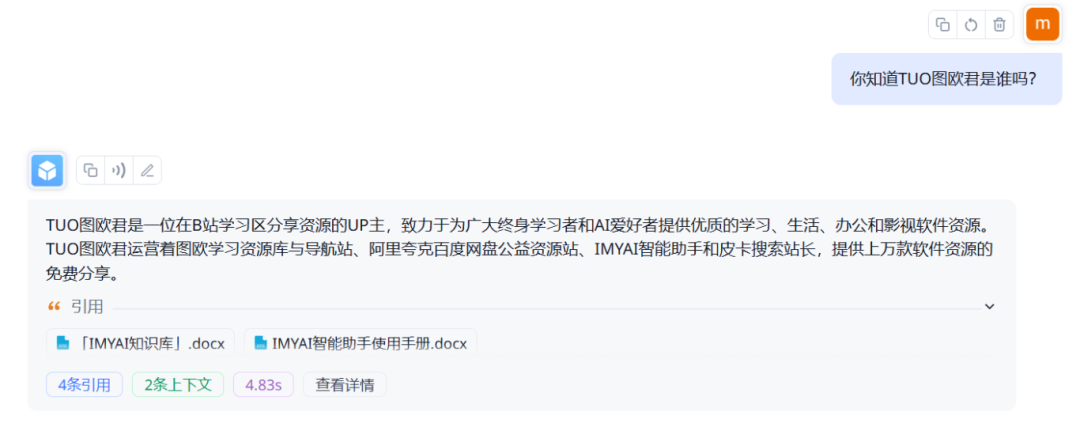
完成配置之后,我们可以在右侧调试一下。比如我问他 “你知道TUO图欧君是谁吗?”,不难发现它会先从知识库中检索到相关信息再回答我。
如果在使用IMYAI智能助手的过程中遇到其他问题,也可以随时进行提问,它会根据知识库内容进行梳理总结,减少你寻找答案的时间(不过要记得,先导入知识库内容哦~)
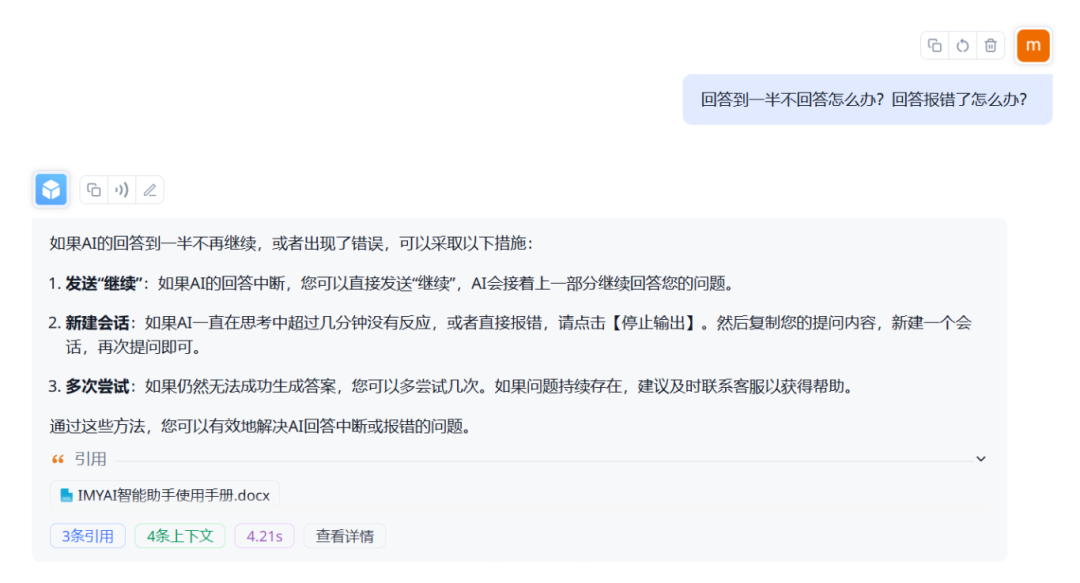
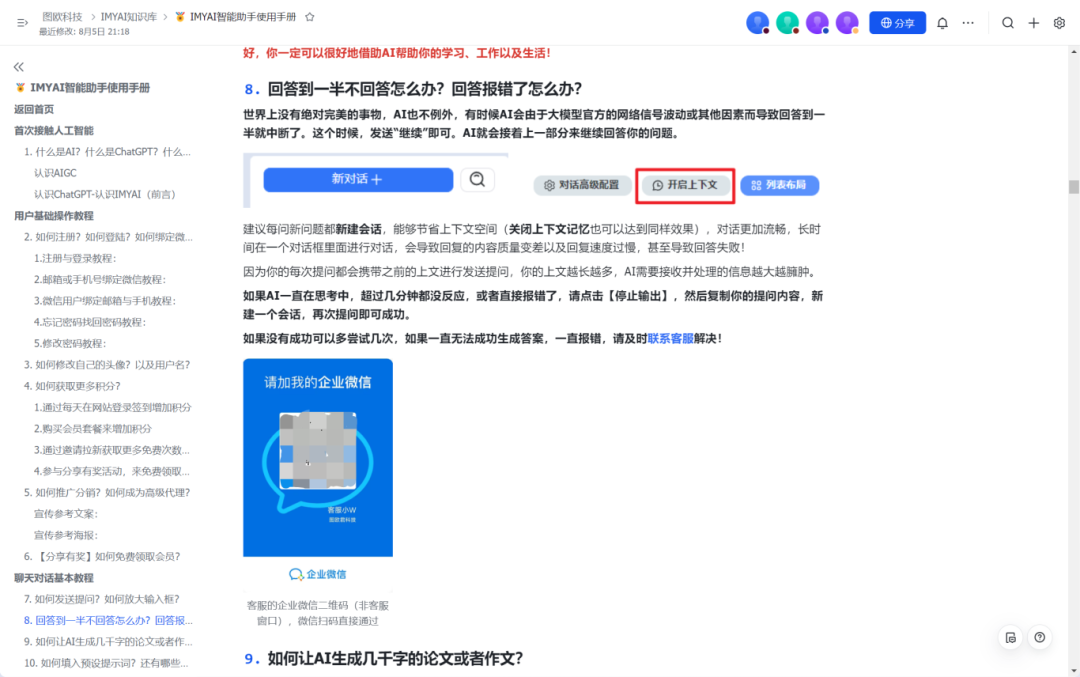
通过对比不难看出,FastGPT这波回答的还是不错的,将原本的内容进行梳理整合之后重新输出,能够更加直观地找到解决问题的答案。
确认调试无误后,点击右上角的“发布”。发布成功后,就可以拥有一个基于本地私有知识库增强的LLM(大型语言模型)啦~

至此,一个私有化的个人知识库就搭建完成了,大家可以随时对知识库中的内容进行提问。
如果你觉得本文的技术含量过高,无法实现的话,可以使用咱们主站(点击左下角阅读原文直达主站)的自定义工作台功能,在预设里面粘贴你的文档数据,这样子也可以实现一个简单的私人小应用~
六、如何系统学习AI大模型?(附全套学习资源)
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









