






大家好,今天要给大家介绍的是2025年2月19日最新发布的目标检测模型——YOLOv12。相信关注计算机视觉和深度学习的小伙伴们都已经听说过YOLO系列,作为目标检测领域的“老牌明星”,YOLO每次更新都会带来不少惊喜。那么,新鲜出炉的YOLOv12,它到底有哪些亮点呢?今天,就让我们一起来深入了解一下!
一、YOLOv12论文信息

论文题目:YOLOv12: Attention-Centric Real-Time Object Detectors
论文链接:https://arxiv.org/abs/2502.12524
代码链接:https://github.com/sunsmarterjie/yolov12
二、环境配置
网上都有,推荐新手下载python3.11版本的。有想要长期训练自己代码能力的推荐使用Anaconda
安装教程网上都有,不要听网上的人使用清华源,什么源的全是有问题的,最好是慢慢下载,用源下载的后续出问题自己负责
在pycharm中使用Anaconda的步骤
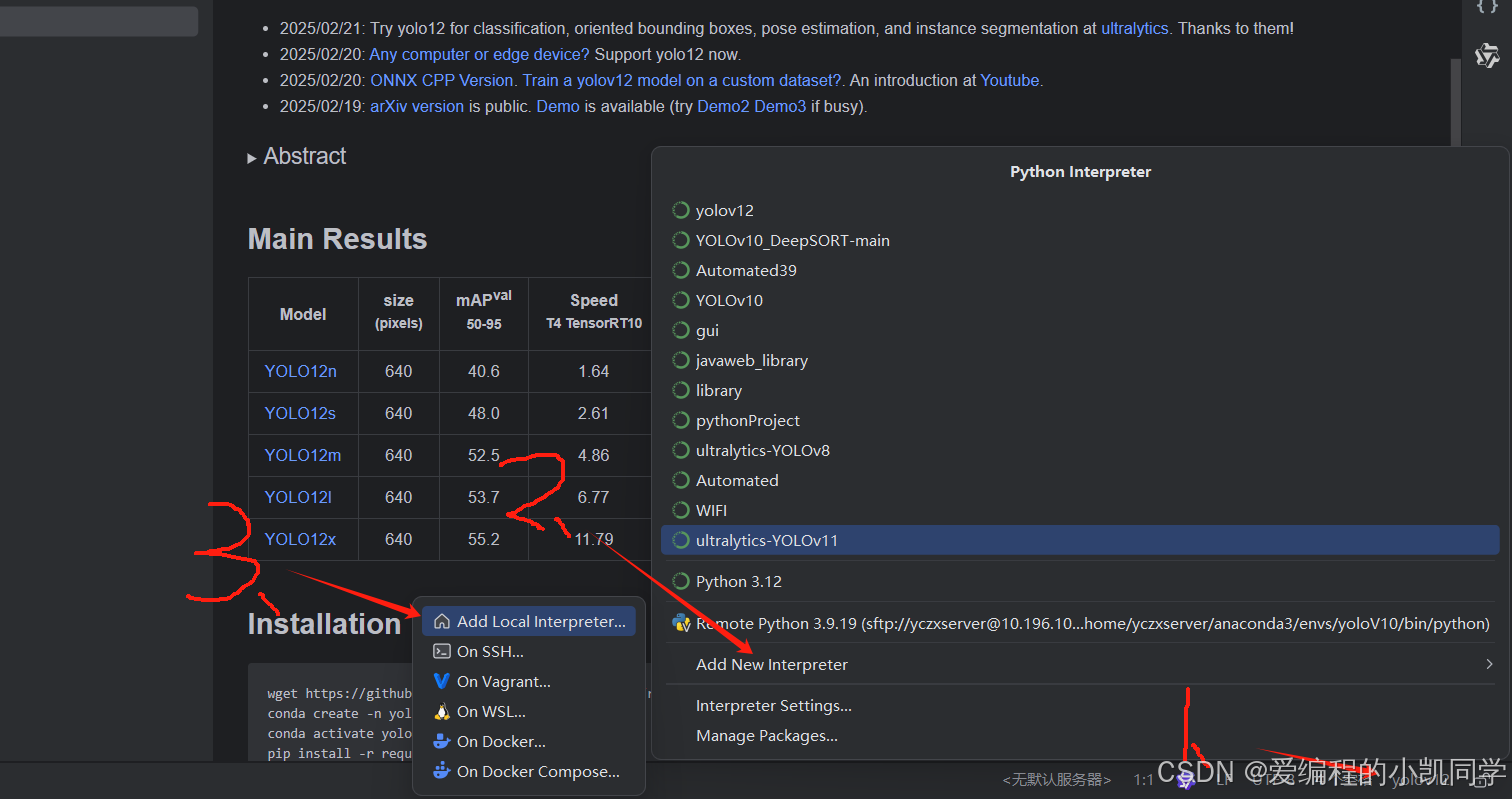
1、pycharm创建解释器
1、点击右下角的解释器
2、新建解释器
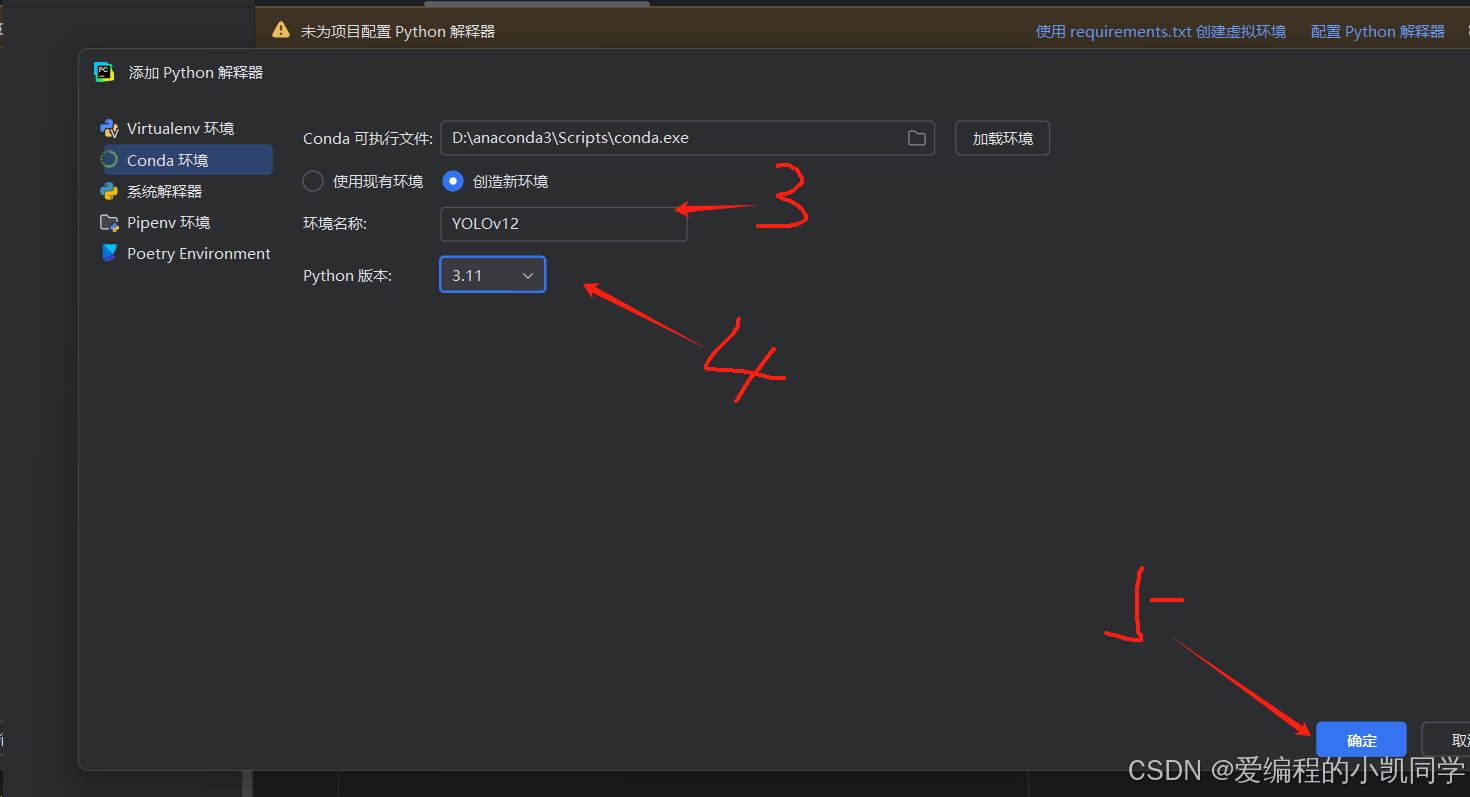
3、添加本地解释器4、取名最好取一个自己知道这是关于什么项目的python解释器名字
5、下拉框选择python版本
2、cmd创建python环境
conda create -n yolov12 python=3.11
conda activate yolov12
pip install -r requirements.txt
pip install -e .三、安装requirements环境
安装requirements.txt文件,尾缀加上清华源下载会快
下载之前, 由于我们的系统是win系统,下面的whl文件无法直接下载,txt里把whl文件加上#或者删除这一行,优先选用下载代码
//不加清华源
pip install -r requirements.txt
//加清华源
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simpleUltralytics YOLO12 默认不需要FlashAttention。不过,FlashAttention 可以选择与 YOLO12 一起编译和使用。要编译 FlashAttention,需要以下NVIDIA ®)图形处理器
本人下载的是
flash_attn-2.5.9.post2+cu122torch2.3.1cxx11abiFALSE-cp311-cp311-win_amd64.whl
分别是:CUDA 版本:12.2 PyTorch 版本:2.3.1 Python 版本:3.11 操作系统:Windows 64-bit
想和我下载一样的PyTorch 版本:2.3.1
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu121
!!真心提醒别用清华源下载pytorch,因为清华源下载的不一定GPU哦,关于pytorch使用GPU好还是CPU好请去网上询问以及为什么pytorch要用GPU版本
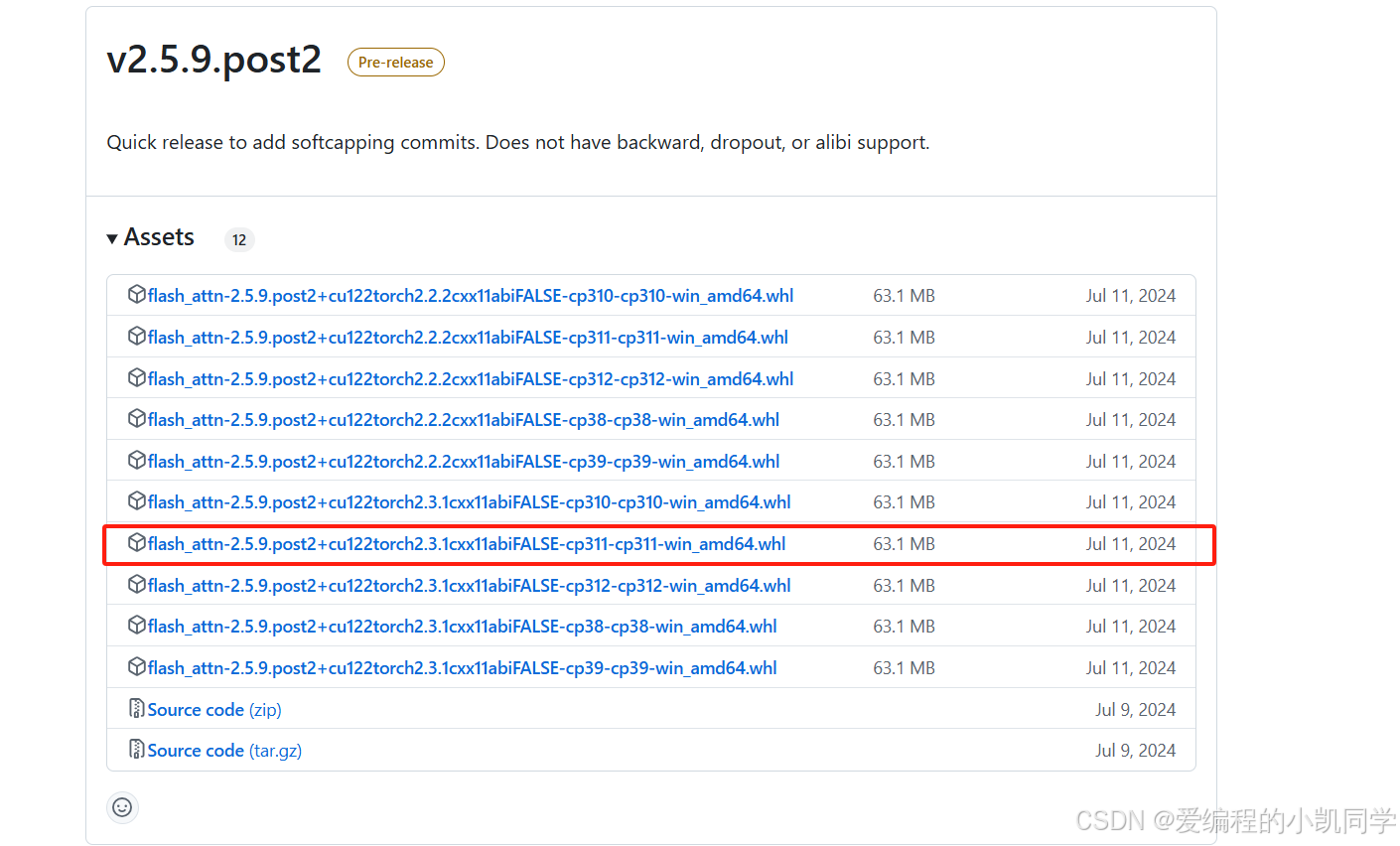
此时whl文件需要留意是属于适配于自己的环境,其中文件名称【flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-win_x86_64.whl】的具体含义为需要适配CUDA 11、PyTorch 2.2、python3.11
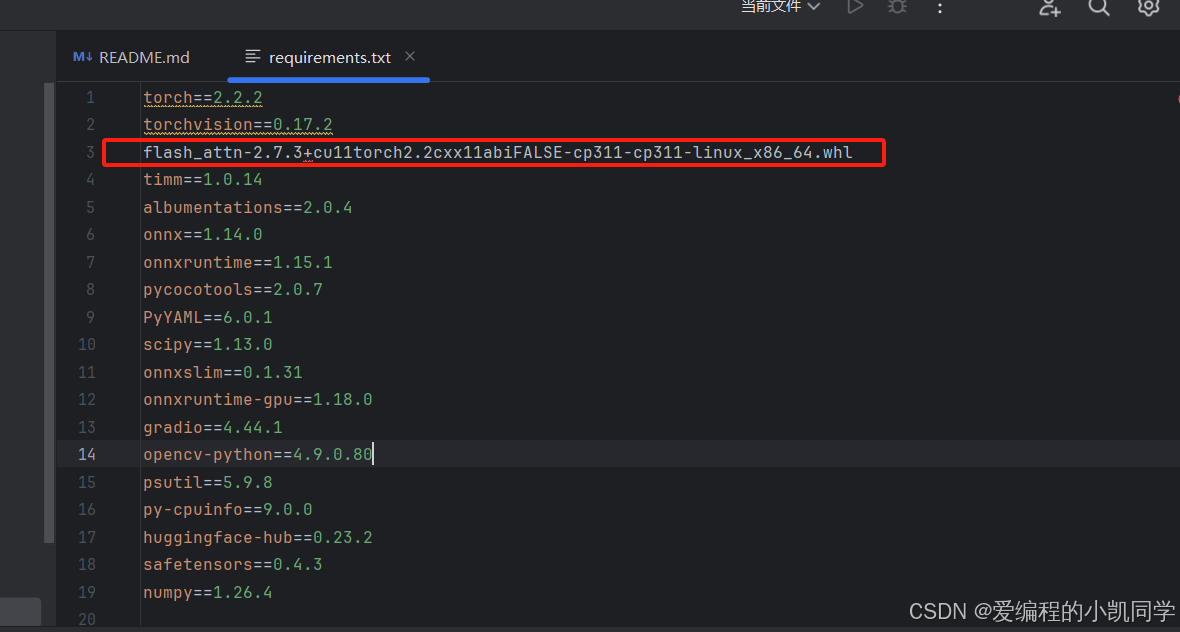
下载的whl文件放在yolov12的根目录下

//这个whl文件是我下载的文件,需根据你下载的whl文件名进行更改
pip install flash_attn-2.5.9.post2+cu122torch2.3.1cxx11abiFALSE-cp311-cp311-win_amd64.whl
四、开发环境中安装 Python 包的命令,用于开发和调试阶段
pip install -e
五、开始训练
下面展示 train.py 代码
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'D:\python\yolov12\datasets\yolov12.yaml')
# 代表使用yolov12的神经网络结构
# model.load(r'D:\python\yolov12\yolov12n.pt')
# 代表使用yolov12n的预训练权重
model.train(data=r'D:\python\yolov12\datasets\data.yaml', # 数据集yaml路径
epochs=300, # 训练300轮
batch=4, # 每一批样本的数量
workers=0, # 同时32个线程
project=r'D:\python\yolov12',
name='yolov12n',
)
六、yolov12提供了使用 TensorRT-YOLO 在 NVIDIA 设备上加速 YOLOv12 推理
!!!需注意ultralytics >= 8.3.78!!!
1、下面提供从 .pt 格式转换为 ONNX 格式,准备进行后续的 TensorRT 优化
trtyolo export -w yolov12n.pt -v ultralytics -o ./ -b 1 -s
2、将 ONNX 格式的 YOLOv12 模型(yolov12n.onnx)转换为 TensorRT Engine 格式
trtexec --onnx=yolov12n.onnx --saveEngine=yolov12n.engine
3、或者不用1、2命令行进行修改,改用py文件代码进行转换格式
from ultralytics import YOLO
model = YOLO('yolov12{n/s/m/l/x}.pt')
model.export(format="engine", half=True) # 或者 format="onnx"
4、正式TensorRT+YOLO进行推理代码
下面展示 detect_TensorRT.py 代码
import cv2
from tensorrt_yolo.infer import InferOption, DetectModel, generatelabels, visualizedef main():
# 初始化
option = InferOption()
option.enableswaprb() # 将BGR转换为RGB# 加载模型
model = DetectModel(engine_path="yolo12n-with-plugin.engine", option=option)
# 读取输入图像
input_img = cv2.imread("testimage.jpg")
if input_img is None:
raise FileNotFoundError("加载测试图像失败。")# 推理过程
detection_result = model.predict(input_img)
print(f"==> 检测结果: {detection_result}")# 可视化结果
class_labels = generate_labels(labelsfile="labels.txt")
visualized_img = visualize(image=input_img, result=detection_result, labels=class_labels)
cv2.imwrite("visimage.jpg", visualized_img)# 模型克隆示范
cloned_model = model.clone()
cloned_result = cloned_model.predict(input_img)
print(f"==> 克隆模型结果: {cloned_result}")if __name__ == "__main__":
main()
疑难解惑
1、tensorrtyolo是什么
如果您希望获取最新的开发版本或者为项目做出贡献,可以按照以下步骤从 GitHub 克隆代码库并安装:请看md文件
通过pip安装
tensorrt_yolo模块,您只需执行以下命令即可:pip install -U tensorrt_yolo

















 9040
9040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









