






病理图像的弱监督分类问题,通常使用多示例学习,在这这一步需要我们将一张全切片变成一个特征组,在这里使用CLAM进行特征提取。
本教程基于Ubuntu22.04,不是在Windows下。
首先下载CLAM的代码,你可以从https://github.com/mahmoodlab/CLAM直接下载zip解压,或者使用
git clone https://github.com/mahmoodlab/CLAM.git通常git clone会因为网络问题而失败,我推荐下载zip。
下载上传到服务器,然后开始配置环境。虽然CLAM有环境配置的yml文件,但是这里我推荐自己手动配置,因为要和后面的特征提取器UNI和CONCH搭配着使用。
创建新的虚拟环境
conda create -n clam python=3.9之后安装对应的包,这里我想使用conch v1.5,所以我按照titan的来配置。
在环境配置好之后,使用CLAM第一步完成组织区域切块,这里需要注意一个问题。
先确定一下你的片子的最大的放大倍率和下采样倍率。
import openslide
import os
def print_slide_scale_factors(slides_directory):
for filename in os.listdir(slides_directory):
if filename.endswith(".svs") or filename.endswith(".tiff") or filename.endswith(".ndpi"): # 根据切片文件的扩展名
slide_path = os.path.join(slides_directory, filename)
slide = openslide.OpenSlide(slide_path)
print(f"Slide: {filename}")
magnification = slide.properties.get(openslide.PROPERTY_NAME_OBJECTIVE_POWER)
print(f"{filename}: Magnification = {magnification}")
for level in range(slide.level_count):
downsample = slide.level_downsamples[level]
print(f" Level {level}: Downsample = {downsample}")
# 替换为你的切片文件所在目录
slides_directory = '/home/perry/nvme0n1/WMK/temp_slide/slide'
print_slide_scale_factors(slides_directory)这是我的运行结果
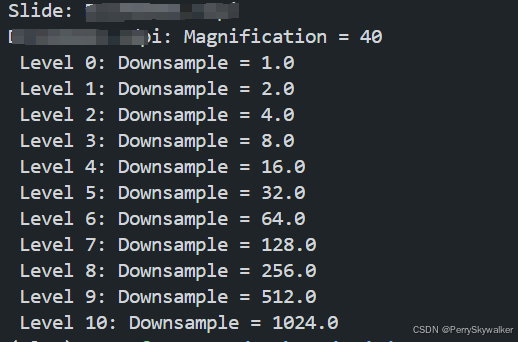
最大放大倍率是40倍,下采样倍率为1,2,4.....
这里我想在跟随这里面的设置,在20x下切512,512的块。
First, to tame the computational complexity caused by long input sequence, we construct the input embedding space by dividing each WSI into non-overlapping patches of 512×512 pixels at 20×magnification, followed by extraction of 768-dimensional features for each patch with the extended version of CONCH, CONCHv1.5.
那么根据我的下采样倍率,40 / 2 = 20,那么我可以downsample level 为 1的时候直接在20x下切512的块,假如我的下采样倍率是1, 4, 16呢?这里可以在40x下切1024*1024的块,然后应该会自动resize的,也相当于在20x下切512的块。
打开vscode里的终端,激活我们刚刚配置好的环境输入
python create_patches_fp.py --source DATA_DIRECTORY --save_dir RESULTS_DIRECTORY --patch_level 1 --patch_size 512 --step_size 512 --seg --patch --stitch其中source是WSIs的文件夹,save_dir是结果保存的文件夹 patch_level 是 downsample level
patch_size是切块大小,step_size为滑动的大小,这里都设置为512,表明无重叠的在downsample level 为 1的情况下切512的块.
之后可以在save_dir里的mask文件夹下看到分割的前景区域,绿线内部为前景区域,假如分割的不好可以在create_patches_fp.py这个python文件的279行把use_otsu改成True

再完成特征提取之后,需要完成特征提取部分。
CUDA_VISIBLE_DEVICES=0 python extract_features_fp.py --data_h5_dir DIR_TO_COORDS --data_slide_dir DATA_DIRECTORY --csv_path CSV_FILE_NAME --feat_dir FEATURES_DIRECTORY --batch_size 32 --slide_ext .svsCUDA_VISIBLE_DEVICES是选择在特征提取时使用哪张显卡,显卡0还是显卡1,这里不推荐使用双卡跑,你可以开两个终端,跑不同的任务。
data_h5_dir 是你在create_patch_fp.py里的save_dir
data_slide_dir 是WSIs存储的路径
csv_patch 是save_dir里面的csv文件的路径
feature_dir 是特征保存的路径
slide_ext 是WSIs的后缀名,一般为svs,tif等
在这里我来举个例子:
假设我的数据存在这个路径下
/home/demo/nvme3n1/TCGA-Brain我想把前景的坐标存在这个路径下
/home/demo/nvme3n1/TCGA-Brain-patch那么我需要使用这个命令来完成前景的提取
python create_patches_fp.py --source /home/demo/nvme3n1/TCGA-Brain --save_dir /home/demo/nvme3n1/TCGA-Brain-patch --patch_size 256 --seg --patch --stitch --process_list process_list_edited.csv之后我的特征想存在这个路径下
/home/demo/nvme3n1/TCGA-Brain-pt那么我特征提取的命令为
CUDA_VISIBLE_DEVICES=0 python extract_features_fp.py --data_h5_dir /home/demo/nvme3n1/TCGA-Brain-patch --data_slide_dir /home/demo/nvme3n1/TCGA-Brain --csv_path /home/demo/nvme3n1/TCGA-Brain-patch/process_list_autogen.csv --feat_dir /home/demo/nvme3n1/TCGA-Brain-pt --batch_size 32 --slide_ext .svs在默认情况下是使用在Imagenet下预训练的Resnet-50来做特征提取的,但是现在使用UNI或者CONCH来做特征提取效果比较好,接下来我会教大家如何使用UNI来完成特征提取
首先去huggingface申请UNI的使用权,这里需要注意使用校园邮箱注册huggingface的账号
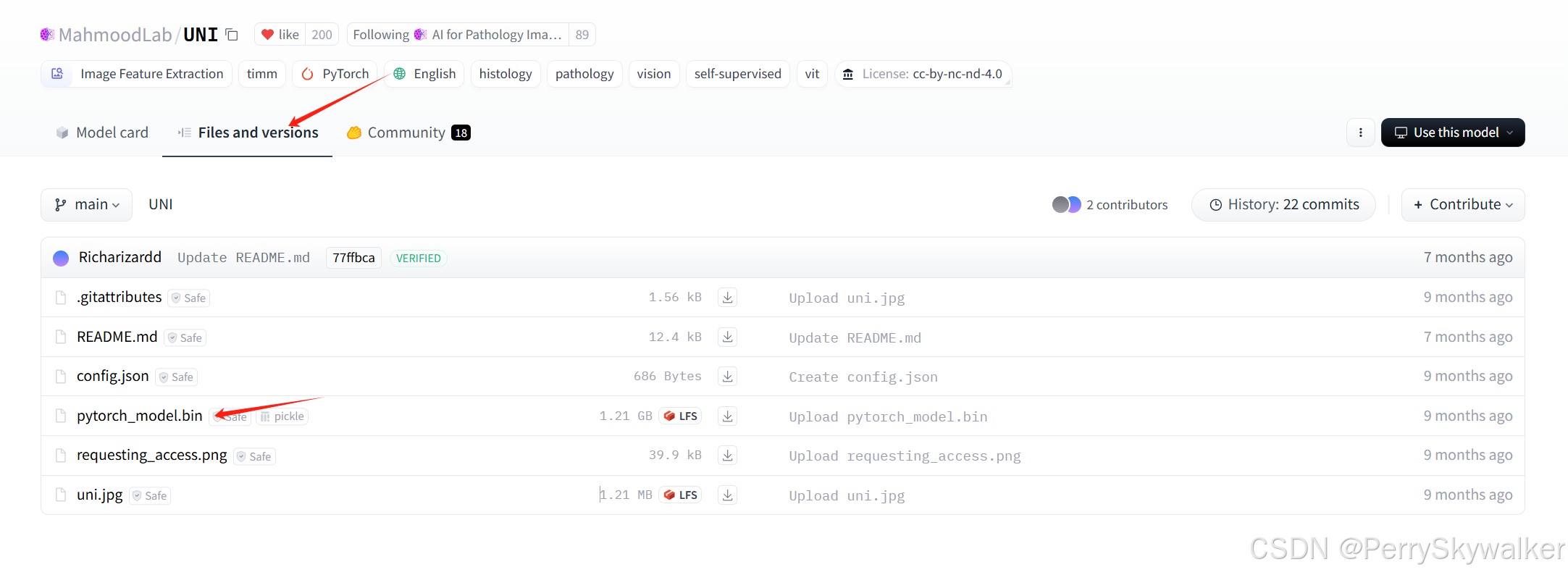
下载这个文件,执行这个命令
export UNI_CKPT_PATH=checkpoints/uni/pytorch_model.binUNI_CKPT_PATH为你刚刚下载的.bin的路径
之后在特征提取的命令后加上 --model_name uni_v1
就像这样
CUDA_VISIBLE_DEVICES=0 python extract_features_fp.py --data_h5_dir /home/demo/nvme3n1/TCGA-Brain-patch --data_slide_dir /home/demo/nvme3n1/TCGA-Brain --csv_path /home/demo/nvme3n1/TCGA-Brain-patch/process_list_autogen.csv --feat_dir /home/demo/nvme3n1/TCGA-Brain-pt --batch_size 32 --slide_ext .svs --model_name uni_v1CONCH同理。至于TITAN这个特征提取器等他们优化把。
有问题评论区会回答的。

















 7926
7926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









