



这是真实的线上案例,暴露出诸多问题,值得记录并分享。
先说系统架构。核心就是 A服务调用B服务,B服务调用数据库C。
起因是有三方监控发现数据库C存在一些问题,建议优化。
数据库C的DBA在10:30左右提议加索引,然后10:55分直接加索引。
首先第一个问题:没有报备,直接线上操作了。线上操作还是白天,也不是晚上。
由于这张表非常大,加所以处理了5分钟。从10:56分开始A服务就一直等待B服务响应,加索引之前B服务响应是几十毫秒,加索引之后陆续增加到7秒,甚至更多,由于B服务自己又没有加超时机制,所以就一直等待。
很快A 服务的线程就满了,然后A服务就无法提供响应。
在11点多,发现A服务不行,研发查半天没也查到原因,直接找运维重启了。
这里第二个问题:没有dump内存那怕是jstack一下线程数据也好,什么也没做暴力重启。这个给事后排障增加困难。
后面是又发现B服务本身有问题,因为B服务也给其他服务提供接口,B服务是重启了tomcat才恢复。
后来复盘,但是不确定AB服务的故障是否是必然有关联,所以是否孤立的两起时间。B服务的研发甚至号称出问题是11点以后,和A服务时间不存在交集。
这里第三个问题:故障出现时间一定要从监控上去看监控趋势,这个从正常到不正常才是故障开始,而不是随便看看接口响应时间,这样存在很大的随机性。
先说A服务,我们要看JVM的监控信息。
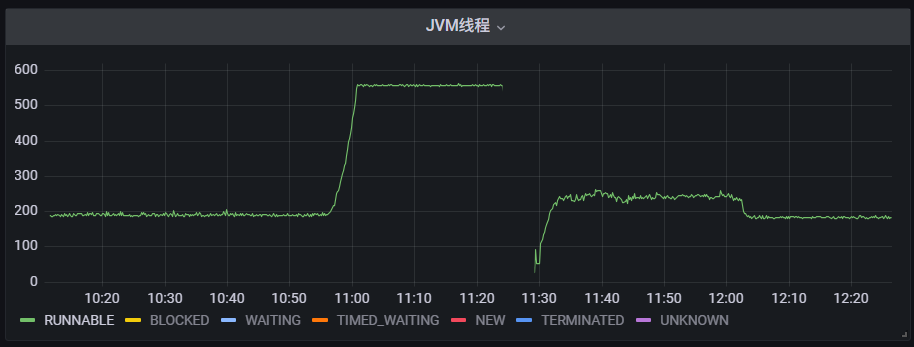
在我问A服务的研发之前,他们自己都说不清什么时候出问题,只是说大概11点多,从JVM线程监控看出问题的时间点是10:56分开始,11:00的时候线程已经打满。
再看JVM的堆内存监控
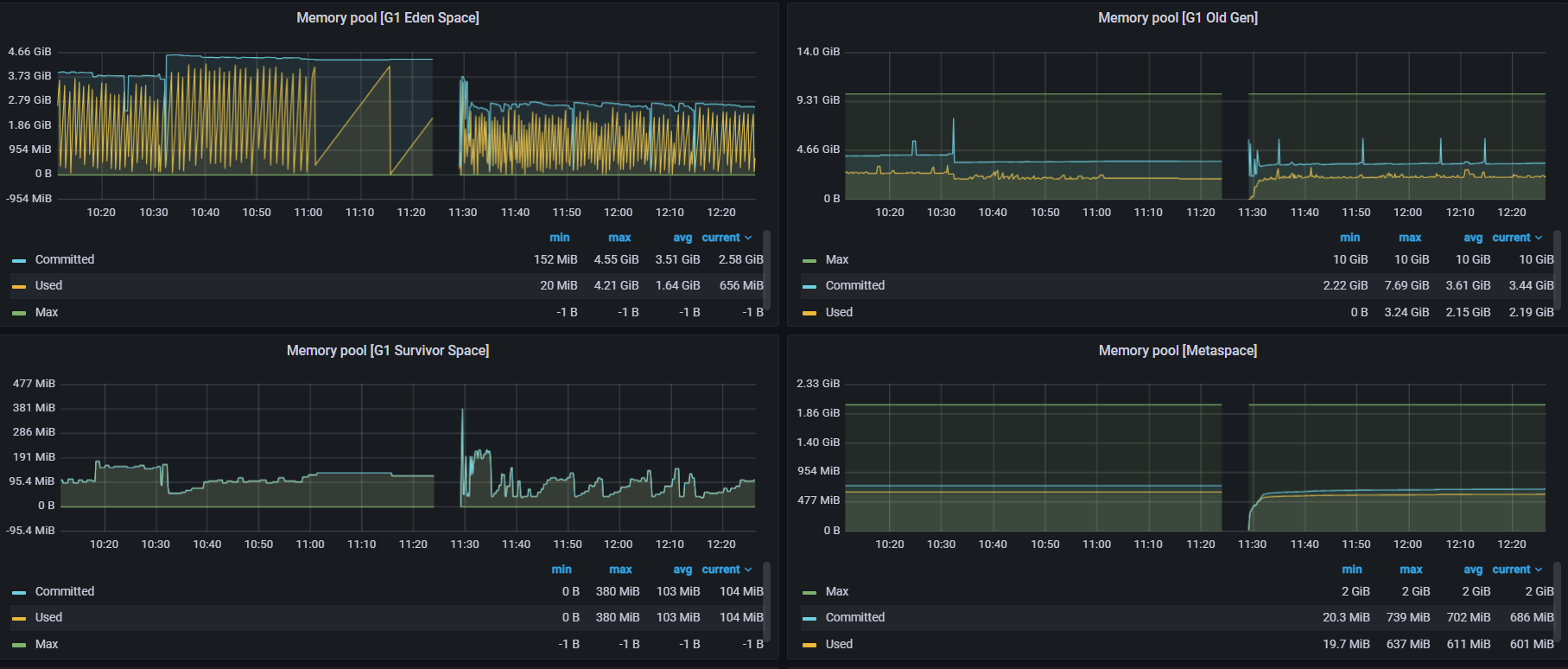
可以看出年老代没有问题,没有发生FGC。
年轻代明显被Hold住,左上角第一幅图是YGC的数据,明显之前YGC很频繁,后来10:56的时候非常缓慢,说明线程被阻塞了。
这个时间只能确定A服务的故障时间,但是和B服务之间关系要从接口上去看。
好在B服务的接口里有 明显的 特征 例如/bapi/这样的拼写。
搜索A服务一上午的接口请求数据
/bapi/在 10:55之前耗时都是100毫秒以内,10:55开始 陆续增加到7秒,到10:58分甚至达到2分钟。而其他接口都很快。
这说明:是bapi导致A服务的故障,而不是其他服务导致的A服务故障。这一点很重要
10:54分 bapi请求数100条以内 最慢100毫秒
10:55分 bapi请求数100条以内 最慢7秒
10:56分 bapi请求数0条
10:58分 bapi请求数2条 2分钟
11:00分 bapi请求数2条 2分钟
这里有个细节就是为什么10:56-11:00之间增加了300个左右线程,但是慢接口只有几个。
正常情况一分钟请求100条以内,持续4分钟左右会积累300-400左右线程,也就是前面第一幅图。
这里需要注意,因为有些请求一直没有返回所以一直在等待,后面是11:20分左右重启这些自然就没有记录到日志,这个日志是返回的时候才记录,所以存在缺陷。
所以有时候不要被日志迷糊了,日志并不一定就是全部的真相。
事后复盘:业务高峰期间不要去操作数据库,而且必须报备,不能随意操作。
说的比较简单,但是实际线上要遵守需要权限管控,流程管理,否则还是形同虚设。

















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









