 数据库内存故障定位与调优方案解析
数据库内存故障定位与调优方案解析




这篇文章重点讲数据库故障的排障思路,如何快速定位问题,恢复故障,并给出解决方案。
系统架构:客户端电脑通过nginx访问网关,网关访问微服务,微服务调用下游,下游有其他微服务,中间件,数据库。
故障现场:早上10点多微服务所有接口整体非常卡顿,延迟都在30毫秒以上,系统不可用。
因为是Oracle数据库,其中有一个指标是可以被监控到的,Oracle节点之间延迟在1秒以上,正常情况下这个延迟是5ms以内。初步怀疑其中一个节点出现了问题。
数据库高可用容灾架构
这边有必要介绍下Oracle的架构是双RAC+ADG。
RAC (Real Application Clusters) : 指主生产中心的Oracle集群。通常由至少2台服务器(节点)组成,共享一套存储(如SAN/NAS/Exadata),共同对外提供一个数据库服务。
ADG是Oracle的企业级功能,用于创建和同步物理备库。
这样就需要最少3节点,如果还有容灾机房可以再部署一个ADG就是4节点。
主机房: - 生产数据库:2节点RAC,共享存储(主) - 本地备库:单实例ADG(也可以是RAC,但用户说1个),有自己的存储(从主存储复制) 容灾机房: - 远程备库:单实例ADG(也可以是RAC,但用户说容灾机房有一个ADG),有自己的存储(从主存储复制) 注意:两个备库都是直接从主库接收重做日志,它们是独立的。
监控预警:比较坑的是这个数据库服务器没有安装Grafana+prometheus,所以只能使用命令行去查看。
第一时间先用top命令去查看2个RAC的瞬间状态。
第一个RAC负载很高:
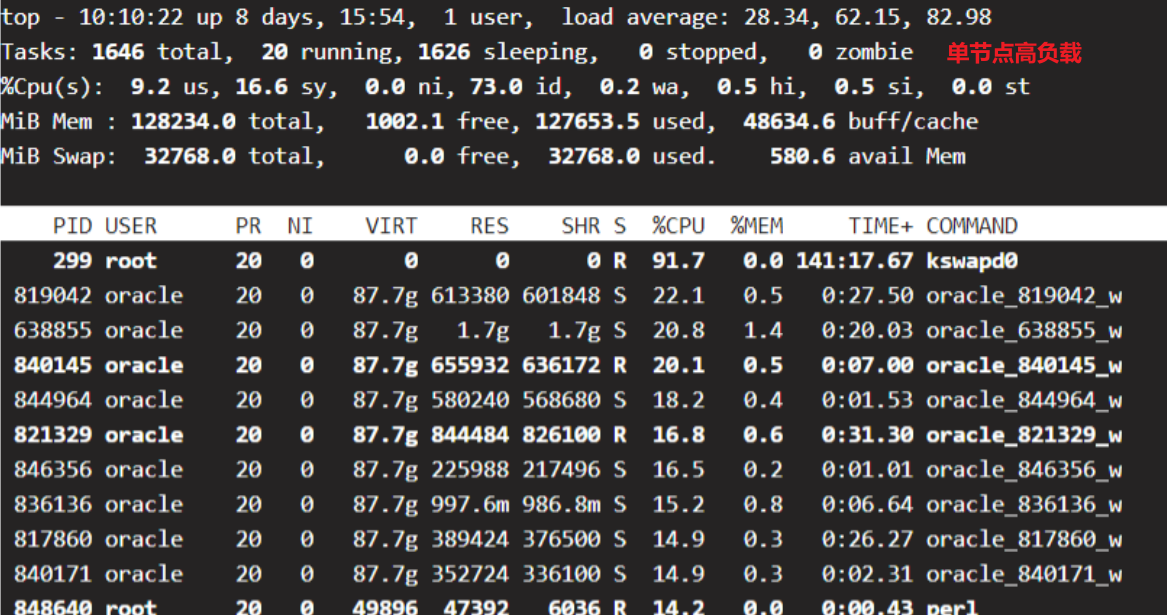
第二个节点完全没有负载
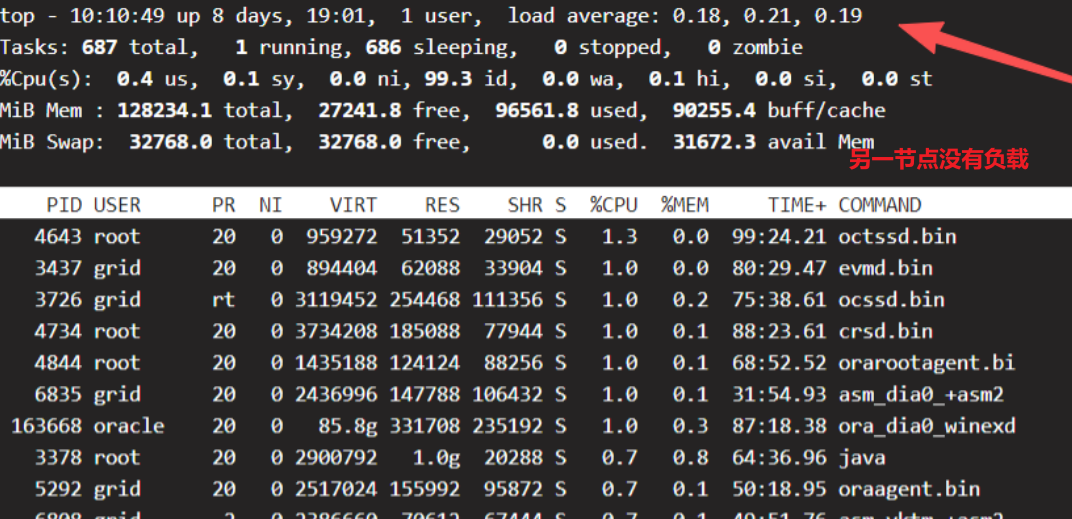
再用Linux的sar命令查看一上午的变化趋势:
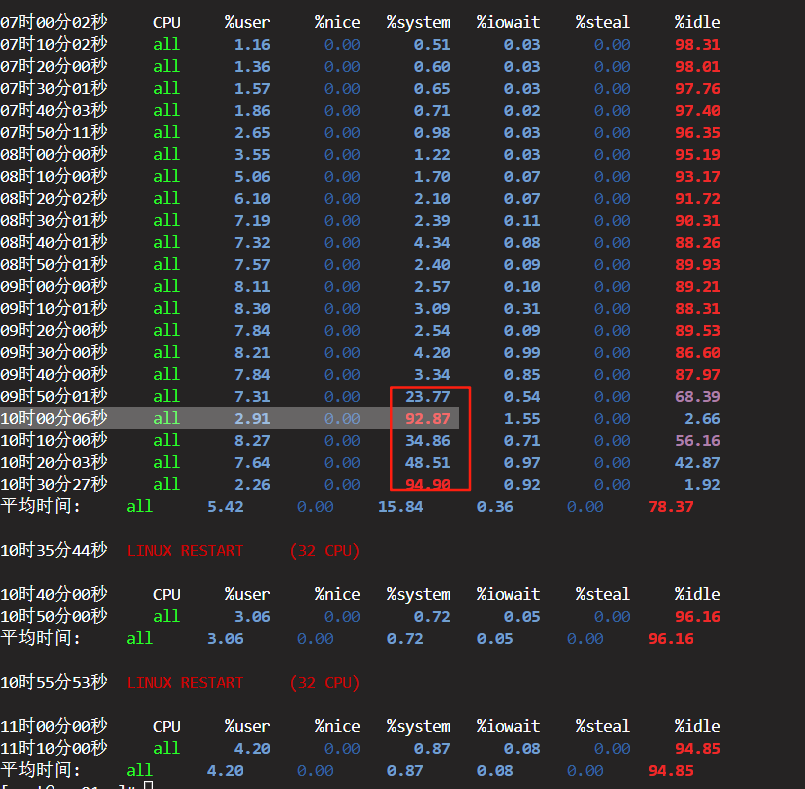
从图中可以明显看出来9点40对分开始数据库负载明显上升(这是事后截图,是经过数据库重启的)
下面对系统负载进行分析:
将服务器的状态分为三个阶段:
阶段一:正常运作期 (07:00 - 09:50)
-
CPU使用率:
%user(用户态CPU)和%system(系统态CPU)都处于较低水平(%user:1-8%,%system: 0.5-4%),%idle(空闲CPU)很高(86%-98%)。 -
I/O压力:
%iowait非常低(0.02%-0.99%),说明磁盘I/O不是瓶颈。 -
评估:在此期间,数据库服务器非常健康,负载很轻,有大量的空闲资源处理业务请求。从09:30开始,
%system和%iowait有轻微上升趋势,可能是负载开始缓慢增加的正常表现,但绝对数值仍在正常范围内。
阶段二:性能灾难期 (09:50 - 10:30)
这是需要重点分析的部分:
-
灾难开端 (09:50:01):
-
%system(系统态CPU使用率)从上一分钟的 3.34% 瞬间飙升至 23.77%。这是一个非常异常的跳跃。%user略有下降,%iowait略有上升。 -
这表明操作系统内核在处理某些系统调用上花费了巨大代价。对于数据库服务器,这通常是大量进程/线程陷入可中断睡眠(等待资源) 的标志。
-
-
全面崩溃 (10:00:06 - 10:30:27):
-
%system飙升至极端水平:92.87% (10:00), 94.90% (10:30)。 -
%idle骤降至:2.66% (10:00), 1.92% (10:30),CPU资源完全耗尽。 -
%user急剧下降至:2.91% (10:00), 2.26% (10:30)。这意味着应用程序(如MySQL)几乎得不到CPU时间来执行实际的计算任务,业务基本停滞。 -
%iowait有所上升(1.55%, 0.92%),但这更像是结果而非原因。因为大量的进程在等待锁,导致I/O请求无法被及时处理,从而推高了%iowait。
-
阶段三:恢复期 (10:35及以后)
-
管理员在 10:35:44 和 10:55:53 进行了两次重启 (
LINUX RESTART)。 -
重启后,所有性能指标(
%user,%system,%iowait,%idle)立即恢复到与第一阶段类似的健康状态,表明故障的根本原因已经被重启操作清除。
查看虚拟化平台监控
这个时候需要马上快速联系了集成人员,因为数据库不是物理机,是虚拟机,虚拟化平台是有监控的。需要拉开24小时的监控图,这非常重要,不要只看当前的几个小时的。
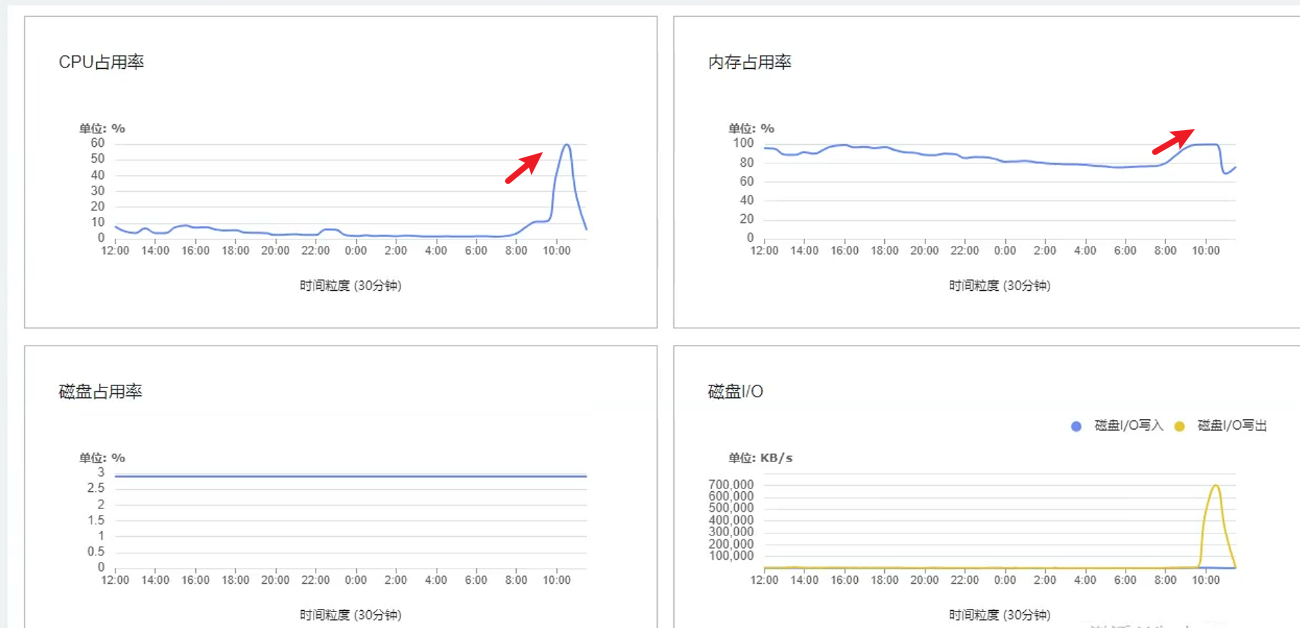
如图所示:内存是持续增长的,并不是一瞬间打满,而CPU是瞬间打满。
故障边界:这个时候需要要知道的是故障的边界:到底是CPU导致还是内存导致。很明显内存是持续增长,到了一定的时候达到99%,出现异常导致CPU也增长,因为内存不足系统明显不可用。所以CPU不是故障的关键,加CPU是效果不大的。问题就出在内存上,当时也有同事怀疑是不是有突发的流量或者死锁,或者慢SQL等等,这些都统统都不是。因为Oracle可以导出AWR分析报告,实际上这个完全不用看,因为不是突发流量,如果陷入AWR报告的是找不到头绪的,因为数据库已经不正常的这个时候。
另外监控预警是不足的,内存90%以上的时候就应该提前预警,不能等到故障点再去修复。
故障恢复:先重启数据库,恢复业务。后续再去调整数据库。
资源升配:CPU和内存是都可以调整,之前是32核心128G,这个客户的QPS本身是够的,实际上是由于集成没有配置合理的数据库内存,各种调优也没有做,临时方案先资源升配解决问题。后面可以慢慢研究问题。
出现这么严重的系统级故障在linux的messages一般都会有记录,我们需要查看一下。
/var/log/messages 是Linux系统中的一个重要日志文件,用于记录系统的各种消息和事件。这个文件包含了系统启动以来的所有日志信息,包括但不限于内核消息、系统服务消息、用户活动消息以及其他应用程序的消息。
Sep 6 09:51:25 rac01 kernel: [747349.847868] oracle_340469_w invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0
Sep 6 09:51:25 rac01 kernel: [747349.847873] CPU: 14 PID: 340469 Comm: oracle_340469_w Kdump: loaded Not tainted 5.10.0-182.0.0.95.oe2203sp3.x86_64 #1
Sep 6 09:51:25 rac01 kernel: [747349.847875] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.15.0-0-g2dd4b9b-20230806_171513-szxrtosci10000 04/01/2014
Sep 6 09:51:25 rac01 kernel: [747349.847876] Call Trace:
Sep 6 09:51:25 rac01 kernel: [747349.847886] dump_stack+0x57/0x6e
Sep 6 09:51:25 rac01 kernel: [747349.847890] dump_header+0x4a/0x200
Sep 6 09:51:25 rac01 kernel: [747349.847891] oom_kill_process.cold+0xb/0x10
Sep 6 09:51:25 rac01 kernel: [747349.847895] out_of_memory+0x10c/0x330
Sep 6 09:51:25 rac01 kernel: [747349.847898] __alloc_pages+0x11e7/0x13a0
Sep 6 09:51:25 rac01 kernel: [747349.847901] __page_cache_alloc+0x78/0xa0
Sep 6 09:51:25 rac01 kernel: [747349.847903] pagecache_get_page+0xa8/0x510
Sep 6 09:51:25 rac01 kernel: [747349.847904] filemap_fault+0x3a2/0x790
Sep 6 09:51:25 rac01 kernel: [747349.847973] __xfs_filemap_fault+0x144/0x240 [xfs]
Sep 6 09:51:25 rac01 kernel: [747349.847978] __do_fault+0x37/0x200
Sep 6 09:51:25 rac01 kernel: [747349.847980] do_read_fault+0x31/0xf0
Sep 6 09:51:26 rac01 kernel: [747349.847981] do_fault+0x75/0x150
Sep 6 09:51:26 rac01 kernel: [747349.847983] __handle_mm_fault+0x3f9/0x6e0
Sep 6 09:51:26 rac01 kernel: [747349.847985] handle_mm_fault+0xbc/0x290
Sep 6 09:51:26 rac01 kernel: [747349.847988] exc_page_fault+0x1b9/0x550
Sep 6 09:51:26 rac01 kernel: [747349.847991] ? asm_exc_page_fault+0x8/0x30
Sep 6 09:51:26 rac01 kernel: [747349.847992] asm_exc_page_fault+0x1e/0x30
Sep 6 09:51:26 rac01 kernel: [747349.847995] RIP: 0033:0xe9b4b7
Sep 6 09:51:26 rac01 kernel: [747349.848000] Code: Unable to access opcode bytes at RIP 0xe9b48d.
Sep 6 09:51:26 rac01 kernel: [747349.848001] RSP: 002b:00007ffee36e8b70 EFLAGS: 00010206
Sep 6 09:51:26 rac01 kernel: [747349.848003] RAX: 0000000000000000 RBX: 0000000000000005 RCX: 00007eff39638400
Sep 6 09:51:26 rac01 kernel: [747349.848003] RDX: 0000000000000000 RSI: 00007ffee36e8940 RDI: 00007ffee36e8960
Sep 6 09:51:26 rac01 kernel: [747349.848004] RBP: 00007ffee36e8d40 R08: 0000000000000000 R09: 00000000e91a3550
Sep 6 09:51:26 rac01 kernel: [747349.848005] R10: 0000000000000000 R11: 0000000000000000 R12: 00000000004e0dc3
Sep 6 09:51:26 rac01 kernel: [747349.848006] R13: 000000ae01830832 R14: 0000000000000000 R15: 00000002f3873378
Sep 6 09:51:26 rac01 kernel: [747349.848007] Mem-Info:
Sep 6 09:51:26 rac01 kernel: [747349.848011] active_anon:9630243 inactive_anon:6003386 isolated_anon:32#012 active_file:2400 inactive_file:14278 isolated_file:1729#012 unevictable:129296 dirty:14 writeback:0#012 slab_reclaimable:112475 slab_unreclaimable:229347#012 mapped:9780972 shmem:11985115 pagetables:16357053 bounce:0#012 free:216443 free_pcp:9923 free_cma:0
Sep 6 09:51:26 rac01 kernel: [747349.848014] Node 0 active_anon:38520972kB inactive_anon:24013544kB active_file:9600kB inactive_file:57112kB unevictable:517184kB isolated(anon):128kB isolated(file):6916kB mapped:39123888kB dirty:56kB writeback:0kB shmem:47940460kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB kernel_stack:40608kB all_unreclaimable? no
Sep 6 09:51:26 rac01 kernel: [747349.848015] Node 0 DMA free:11264kB min:4kB low:16kB high:28kB reserved_highatomic:0KB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:15992kB managed:15360kB mlocked:0kB pagetables:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB
Sep 6 09:51:26 rac01 kernel: [747349.848018] lowmem_reserve[]: 0 2479 128219 128219 128219
Sep 6 09:51:26 rac01 kernel: [747349.848022] Node 0 DMA32 free:505368kB min:3340kB low:5848kB high:8356kB reserved_highatomic:2048KB active_anon:808852kB inactive_anon:398628kB active_file:1076kB inactive_file:1264kB unevictable:148kB writepending:0kB present:3128832kB managed:2539008kB mlocked:148kB pagetables:764088kB bounce:0kB free_pcp:4280kB local_pcp:252kB free_cma:0kB
Sep 6 09:51:26 rac01 kernel: [747349.848025] lowmem_reserve[]: 0 0 125739 125739 125739
Sep 6 09:51:26 rac01 kernel: [747349.848028] Node 0 Normal free:349140kB min:465640kB low:594388kB high:723136kB reserved_highatomic:16384KB active_anon:37712120kB inactive_anon:23614916kB active_file:8204kB inactive_file:56072kB unevictable:517036kB writepending:56kB present:131072000kB managed:128757292kB mlocked:515484kB pagetables:64664124kB bounce:0kB free_pcp:35440kB local_pcp:1496kB free_cma:0kB
Sep 6 09:51:26 rac01 kernel: [747349.848031] lowmem_reserve[]: 0 0 0 0 0
Sep 6 09:51:26 rac01 kernel: [747349.848034] Node 0 DMA: 0*4kB 0*8kB 0*16kB 0*32kB 0*64kB 0*128kB 0*256kB 0*512kB 1*1024kB (U) 1*2048kB (M) 2*4096kB (M) = 11264kB
Sep 6 09:51:26 rac01 kernel: [747349.848043] Node 0 DMA32: 34005*4kB (UM) 17088*8kB (UM) 7116*16kB (UME) 2058*32kB (UM) 813*64kB (UM) 11*128kB (UM) 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 505876kB
Sep 6 09:51:26 rac01 kernel: [747349.848052] Node 0 Normal: 71735*4kB (UM) 5427*8kB (UM) 941*16kB (UM) 203*32kB (UM) 29*64kB (M) 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 353764kB
Sep 6 09:51:26 rac01 kernel: [747349.848062] Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=1048576kB
Sep 6 09:51:26 rac01 kernel: [747349.848063] Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB
Sep 6 09:51:26 rac01 kernel: [747349.848063] 12461302 total pagecache pages
Sep 6 09:51:26 rac01 kernel: [747349.848069] 426070 pages in swap cache
Sep 6 09:51:26 rac01 kernel: [747349.848070] Swap cache stats: add 19265110, delete 18838046, find 22794977/25867567
Sep 6 09:51:26 rac01 kernel: [747349.848071] Free swap = 0kB
Sep 6 09:51:26 rac01 kernel: [747349.848071] Total swap = 33554428kB
Sep 6 09:51:26 rac01 kernel: [747349.848072] 33554206 pages RAM
Sep 6 09:51:26 rac01 kernel: [747349.848073] 0 pages HighMem/MovableOnly
Sep 6 09:51:26 rac01 kernel: [747349.848073] 726291 pages reserved
Sep 6 09:51:26 rac01 kernel: [747349.848074] 0 pages hwpoisoned
Sep 6 09:51:26 rac01 kernel: [747349.848074] Tasks state (memory values in pages):
以下省略部分,接上面日志
Sep 6 09:51:37 rac01 kernel: [747350.393579] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/system.slice/ohasd.service,task=oracle_3276187_,pid=3276187,uid=54322
Sep 6 09:51:37 rac01 kernel: [747350.393601] Out of memory: Killed process 3276187 (oracle_3276187_) total-vm:92006248kB, anon-rss:16304kB, file-rss:0kB, shmem-rss:5531100kB, UID:54322 pgtables:111052kB oom_score_adj:0
日志里很明显记录了Out of memory: Killed process
在 Sep 6 09:51:25,服务器物理内存和交换空间(Swap)完全耗尽。Linux 内核的 OOM-Killer 被触发,选择并杀死了名为 oracle_340469_w 的 Oracle 数据库工作进程(很可能是一个后台进程),以释放内存、拯救系统于完全僵死。内存耗尽是导致之前看到的 CPU %system 使用率飙升和系统无响应的根本原因。
详细日志分析
1. OOM-Killer 被触发
Sep 6 09:51:25 rac01 kernel: [747349.847868] oracle_340469_w invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0
-
oracle_340469_w invoked oom-killer: 这并不意味着是这个 Oracle 进程主动“调用”了 killer。它的意思是,这个进程在尝试分配内存时,触发了内存不足的条件,从而导致内核启动 OOM-Killer 机制。 -
gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE): 表示进程请求分配的是可被移动、用于用户空间的高端内存。 -
oom_score_adj=0: 这个进程的 OOM 调整分数为 0(默认值),意味着内核根据默认算法来决定杀死谁,这个进程并没有被特殊保护。
2. 内存状态快照(最关键的部分)
Sep 6 09:51:26 rac01 kernel: [747349.848007] Mem-Info: ... Sep 6 09:51:26 rac01 kernel: [747349.848014] Node 0 active_anon:38520972kB inactive_anon:24013544kB ... free:216443 free_pcp:9923 free_cma:0 ... Sep 6 09:51:26 rac01 kernel: [747349.848071] Free swap = 0kB Sep 6 09:51:26 rac01 kernel: [747349.848071] Total swap = 33554428kB
-
Free swap = 0kB: 所有 32GB (33554428kB) 的交换空间(Swap)已经被全部用完。这是系统内存压力极大的明确信号。 -
free:216443kB: 可用物理内存仅剩大约 211MB。对于一台服务器来说,这等同于耗尽。 -
active_anon:38520972kB+inactive_anon:24013544kB: 匿名页内存(通常是应用程序堆、栈等数据)占用了约(38.5G + 24G) = 62.5GB。这是巨大的内存使用量。 -
pagetables:16357053kB: 页表占用了惊人的 16GB 内存。这通常意味着系统中存在大量进程或线程,或者进程映射了非常大的内存区域(例如 Oracle 的 SGA 使用了大页但未正确配置?),导致管理这些映射的页表本身变得异常庞大。
3. 各内存区域详情
日志显示了 DMA, DMA32, Normal 三个内存区域的状态。最重要的是 Normal 区域:
Node 0 Normal free:349140kB min:465640kB
-
free:349140kB(~341MB) 是当前剩余内存。 -
min:465640kB(~455MB) 是内核认为该区域需要保留的最低空闲内存阈值。 -
当前空闲内存(341MB)已经低于最低阈值(455MB),这就是直接触发 OOM-Killer 的条件。
4. OOM-Killer 的选择结果
日志最后列出了所有进程的内存使用情况,OOM-Killer 会根据复杂的算法(oom_score)给每个进程打分,选择最“坏”的进程杀死。虽然日志截断了,没有显示被杀的完整列表和分数,但触发者 oracle_340469_w 本身就是一个主要的候选者。
Oracle数据库调优方案:
1. RAC两节点内存各增加至256G
2. 启用大页内存管理
3. 根据内存增加情况相应调整SGA大小
4. 关闭审计功能(如用户无明确要求必须使用)
5.redo日志调整至800MB或1G大小,默认的200m偏小,日志切换频繁
以下对上面的调优方案逐个进行分析
1. RAC两节点内存各增加至256G
-
效果:直接有效
-
分析: 这是最直接、最根本的解决方案。之前的故障本质是物理内存和Swap被完全耗尽。将内存从(推测的)128G或更低提升至256G,直接将可用内存资源翻倍。
-
它为Oracle的SGA/PGA提供了更大的运行空间,避免了激烈的内存竞争。
-
它大幅降低了系统需要使用Swap的可能性,从而从根本上避免了因Swap剧烈颠簸导致的
%systemCPU飙升和系统卡顿。 -
即使出现异常的内存消耗(如某个bug或异常SQL),256G的内存也提供了更大的缓冲池,为DBA介入处理争取了宝贵时间,而不是立即触发OOM。
-
2. 启用大页内存管理 (HugePages)
-
效果:直接有效
-
分析: 这是另一个针对性的关键优化。在之前的OOM日志中,有一个致命指标:
pagetables:16357053kB(约 16GB!)。这是因为默认的4KB内存页,管理如此大的物理内存会产生巨大的页表项,页表本身就会消耗大量内存。-
HugePages使用更大的内存页(如2MB或1GB),显著减少了页表项的数量。
-
效果: 启用后,页表的内存开销从16GB预计会下降到几百MB级别。这直接释放了约15GB以上的可用内存给应用程序(Oracle)使用。
-
此外,HugePages是常驻内存、不可换出的,这减少了内存管理的开销,还能提升内存访问性能。
-
3. 根据内存增加情况相应调整SGA大小
-
效果:非常重要
-
分析: 增加物理内存后,必须相应地调整Oracle的内存参数,否则新内存得不到有效利用。
-
可以将
SGA_TARGET和SGA_MAX_SIZE设置为一个更大的值(例如,为每个实例分配150G-180G),同时也要适当增加PGA_AGGREGATE_TARGET。 -
这样确保了Oracle能够充分利用新硬件资源,减少磁盘I/O(如物理读),提升性能,并进一步降低了因内存不足而使用Swap的风险。这是一个承上启下的关键配置。
-
4. 关闭审计功能
-
效果:优化辅助
-
分析: 审计功能(尤其是开启所有语句的审计)会产生大量的审计日志,对CPU、I/O和存储空间都是额外的开销。
-
虽然它不是导致本次OOM的直接原因,但在系统高负载时,关闭非必要的审计可以减轻系统的整体负担,释放出更多的CPU和I/O资源用于处理正常的业务请求。
-
这是一种“减负”优化,让系统运行得更轻盈,间接提升了系统的稳定性和冗余度。
-
5. Redo日志调整至800MB或1G大小
-
效果:优化辅助
-
分析: 这个调整不直接解决内存问题,但对于解决因日志切换频繁引起的性能问题非常有效。
-
默认200MB确实太小,会导致日志切换非常频繁。频繁的日志切换会引发:a)
checkpoint操作增加,加剧I/O压力;b) 可能因为归档速度跟不上而短暂地挂起数据库写操作。 -
增大Redo Log到800MB或1G后,显著降低了日志切换的频率。这使得系统运行更加平稳,减少了不必要的I/O尖峰和等待事件(如
log file sync,log file parallel write)。 -
一个更平稳的系统,其资源利用率(CPU、内存、I/O)的曲线也会更平稳,避免了因其他原因(如I/O阻塞)导致的连锁反应,从而降低了系统出现异常压力的整体风险。
-
以上就是这次故障的定位和修复的方案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









