




Learning Rich Part Hierarchies With Progressive Attention Networks for Fine-Grained Image Recognition
2020 TIP,论文主要借鉴了MA-CNN。
文章目录
1 引言
细粒度分类两类解决方案:局部定位和高阶特征。
目前的定位类方法主要涉及较粗糙的部分,忽略了更细粒度的部分也提供识别的关键信息。然而,由于平滑或模糊特征图的不精确局部化,检测到这种程度是很难的。深层特征图中的每个元素对应于原始图像中的大感受野,导致区域上下文的混合,小部分受到相邻区域的影响,无法精确定位。
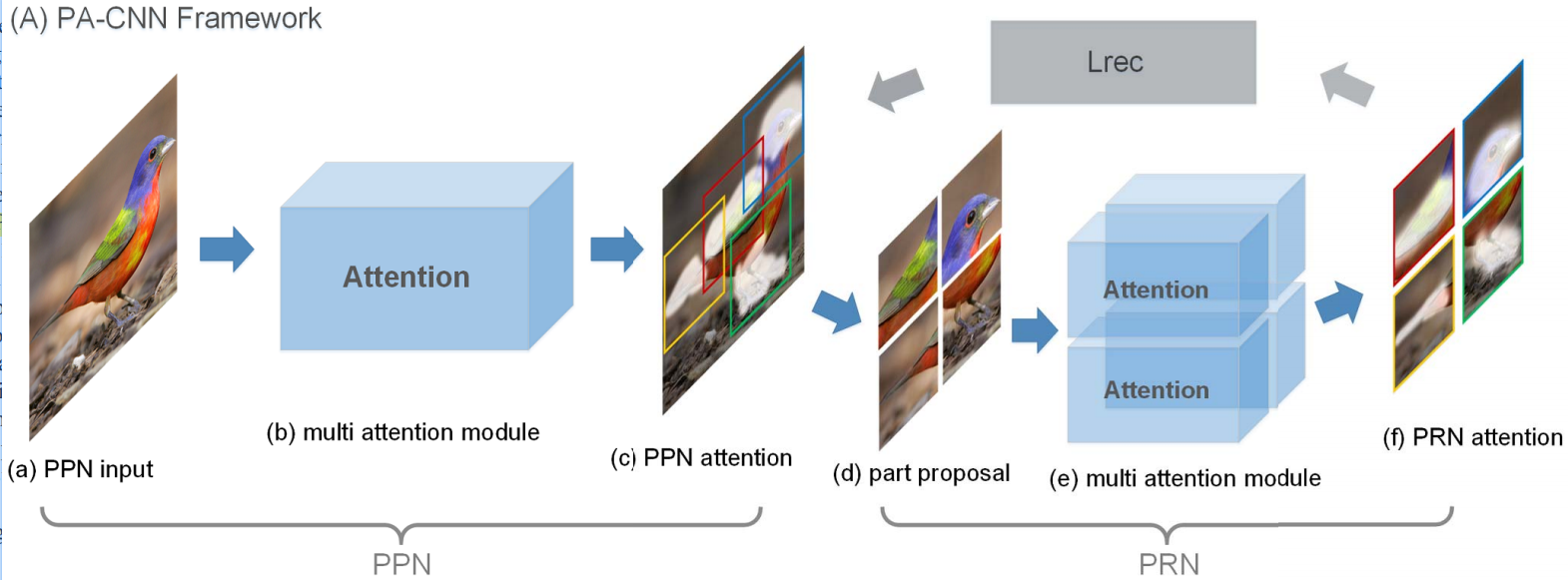
本文提出了渐进注意卷积神经网络(PA-CNN),可获取丰富的部分层次结构。主要思想是引入一种部分校正机制,使细粒度部分能够高精度地定位。其中,部分提议网络PPN生成多个局部注意力图,**部分校正网络(PRN)**学习每个部分的特征,并为PPN提供修正的位置。PPN和PRN相互加强。将较粗的尺度的PRN的输入和卷积参数以较细的尺度传递给PPN,可以逐渐生成更细粒度的部分和特征。
本文贡献:
- 提出渐进注意力卷积神经网络PA-CNN,可以学习部分的层次结构
- 以相互加强的方式优化部分建议子网和部分校正子网
- 实验性能好
3 方法
整体结构就是PPN产生多个注意力,PRN根据PPN的目标部分进行修正,再反馈回去:
注意力模块的构成:
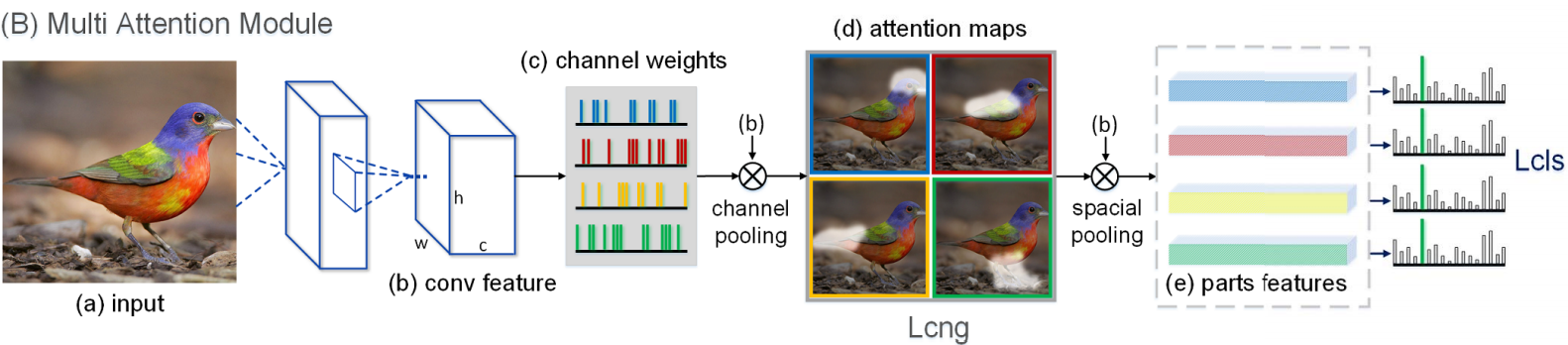
详见MA-CNN。
3.1 多注意力模块及其损失
此部分完全就是MA-CNN中的channel grouping操作。
3.3 渐进式注意力CNN
两个模块的结构
- PPN包括多注意力模块,
- 输入:原始图片
- 输出:从原始图片根据注意力图 M p \mathbf{M_p} Mp裁剪正方形块得到的若干新图片 X p \mathbf{X_p} Xp
- PRN,每个建议部分都有一个全连接层生成注意力
- 输入:建议部分 X p \mathbf{X_p} Xp
- 输出:注意力图 M r \mathbf{M_r} Mr
两个模块之间的交互
用PRN的输出修正PPN的区域,修正损失函数:
L r e c ( M p ) = ∑ j , k = 1 ( h , w ) R e c ( m r ( j , k ) , m p ( j , k ) ) R e c ( m r ( j , k ) , m p ( j , k ) ) = ∣ ∣ m r ( j , k ) − m p ( j , k ) ) ∣ ∣ 2 L_{rec}(\mathbf{M_p})=\sum^{(h,w)}_{j,k=1}Rec(m_r(j,k),m_p(j,k))\\ Rec(m_r(j,k),m_p(j,k))=||m_r(j,k)-m_p(j,k))||^2 L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









