







SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data
AAAI2021
解决cutmix对细粒度任务失败的问题进行改进.
snapmix是针对细粒度的数据增广技术
文章目录
摘要
- 数据混合增强可以有效地训练深度模型,基于图像像素的混合比例来混合标签在细粒度识别中容易产生噪声
- 本文提出了一种称为语义比例混合的方案,利用类激活图来减少在增广细粒度数据时的标签噪声。通过估计混合图像的语义成分来为其生成标签,并允许非对称混合操作并确保合成图像与目标标签之间的语义对应。
- 实验表明,效果很好。通过结合中级特征,达到了最好的性能,证明了其作为细粒度识别的潜力。
- 代码https://github.com/Shaoli-Huang/SnapMix.git
1 引言
- 数据增广解决过拟合问题。基于混合的方法,Mixup、CutMix会随着增加细粒度数据中标签噪声风险的增加性能会下降。因为细粒度就是要根据细小区域进行识别的,不能简单依靠面积比例。
- 语义比例混合策略来解决。利用类别激活图来估计混合图像的标签组成。通过将每个图像的CAM归一化,首先获得其语义百分比图以量化每个像素与标签之间的相关性百分比,求和算出图像区域的语义比。对于由多个图像中的多个区域组成的图像,可以通过与这些区域相对应的语义比率来估计其语义位置。
- 现有技术依赖于对称地融合图像区域,这意味着要混合的所选区域被限制为互补的,限制了增强数据的多样性。 SnapMix可以实现非对称的剪切和粘贴操作,增强数据多样性。
- 浅层网络不能很好地解决标签噪声可以部分解释这一事实,之前的方法效果不好。即使是简单的模型应用本文的数据增强性能也可以非常好
2 相关研究
细粒度分类
SnapMix的不同之处:
- SnapMix是纯数据增广,在测试阶段不需要额外的计算过程。
- 基于数据混合策略。 常规的数据增强策略通常处理单个图像并保留原始标签。
数据增广
最新进展可分成两类:区域擦除和数据混合。
SnapMix属于第二类,由于是利用类激活图来估计合成图像的语义结构,可以在不引入严重标签噪声的情况下扩展到细粒度数据。使用非对称补丁混合图像,与使用对称区域的数据相比,可提供更好的数据随机性和多样性。
3 SnapMix
符号
I
:
图
像
y
:
标
签
λ
∼
B
e
t
a
(
α
,
α
)
I
~
:
合
成
图
像
ρ
:
标
签
权
重
I:图像\\ y:标签\\ \lambda \sim Beta(\alpha, \alpha)\\ \tilde{I}:合成图像 \\ \rho:标签权重
I:图像y:标签λ∼Beta(α,α)I~:合成图像ρ:标签权重
| 方法 | MixUp | CutMix |
|---|---|---|
| 合成图像公式 | I ~ = λ × I a + ( 1 − λ ) × I b \tilde{I}=\lambda\times I_a+(1-\lambda)\times I_b I~=λ×Ia+(1−λ)×Ib | I ~ = ( 1 − M λ ) ⊙ I a + M λ ⊙ I b \tilde{I}=(1-M_\lambda)\odot I_a+M_\lambda\odot I_b I~=(1−Mλ)⊙Ia+Mλ⊙Ib |
| 标签权重公式 | ρ a = λ , ρ b = 1 − λ \rho_a=\lambda,\rho_b=1-\lambda ρa=λ,ρb=1−λ | ρ a = 1 − λ , ρ b = λ \rho_a=1-\lambda,\rho_b=\lambda ρa=1−λ,ρb=λ |
给定输入数据对,提取语义百分比图用于计算图像区域的语义百分比。在非对称位置通过剪切和粘贴来混合图像。计算每个混合成分的语义比例作为融合单标签的指导。
混合图像
**非对称:**在图像A中的一个随机位置上裁剪一个区域,然后将其裁剪并粘贴到图像B中的另一个随机位置,公式表示为:
I
~
=
(
1
−
M
λ
a
)
⊙
I
a
+
T
θ
(
M
λ
b
⊙
I
b
)
\tilde{I}=(1-M_{\lambda^a})\odot I_a + T_{\theta}(M_{\lambda^b}\odot I_b)
I~=(1−Mλa)⊙Ia+Tθ(Mλb⊙Ib)
T
θ
T_\theta
Tθ代表了裁剪粘贴操作。
标签生成
计算CAM图,归一化生成SPM图,计算区域的语义权重。
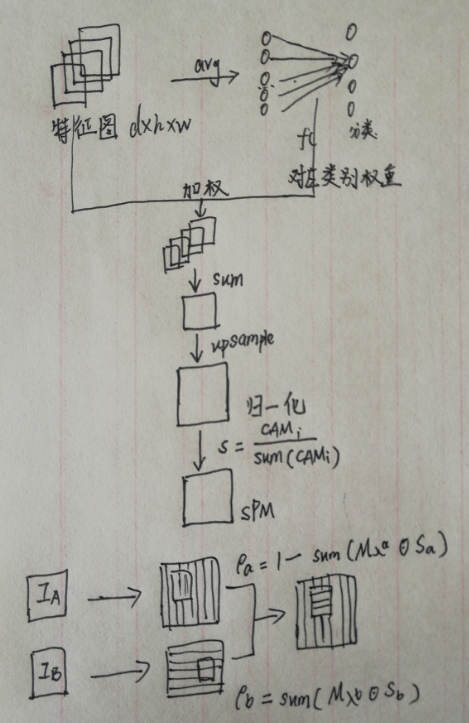
4 实验
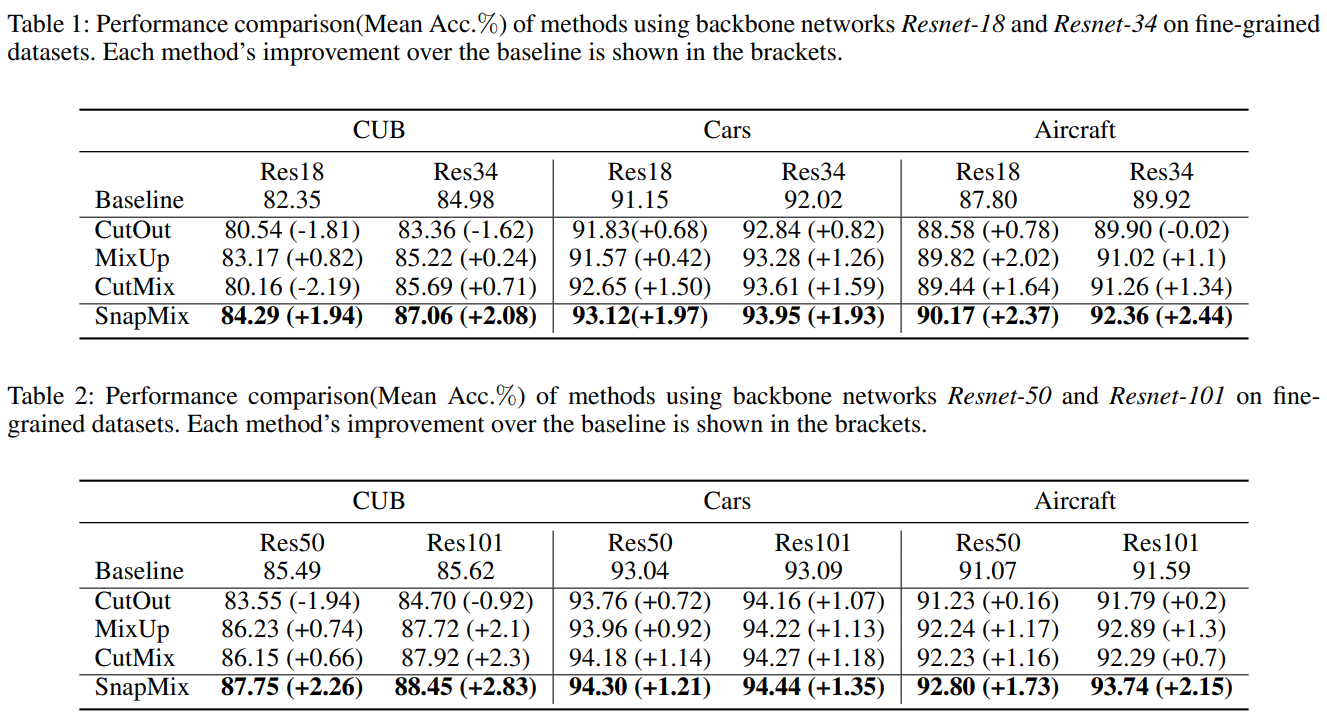
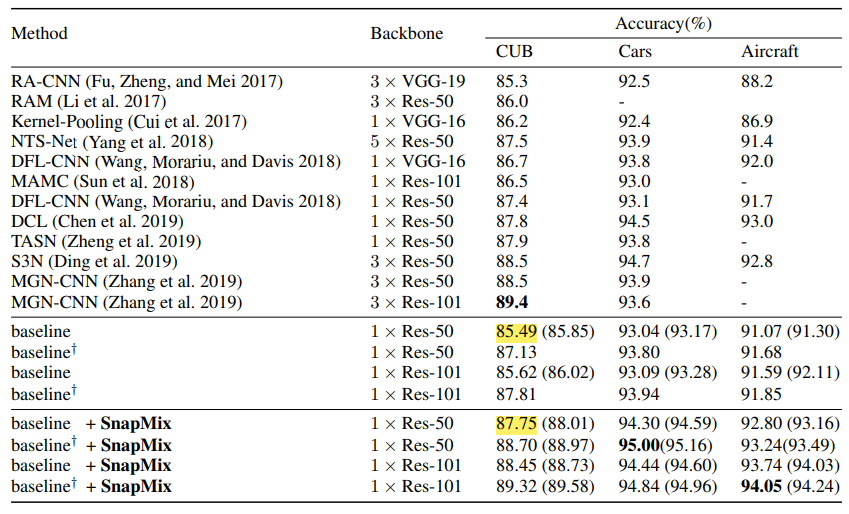
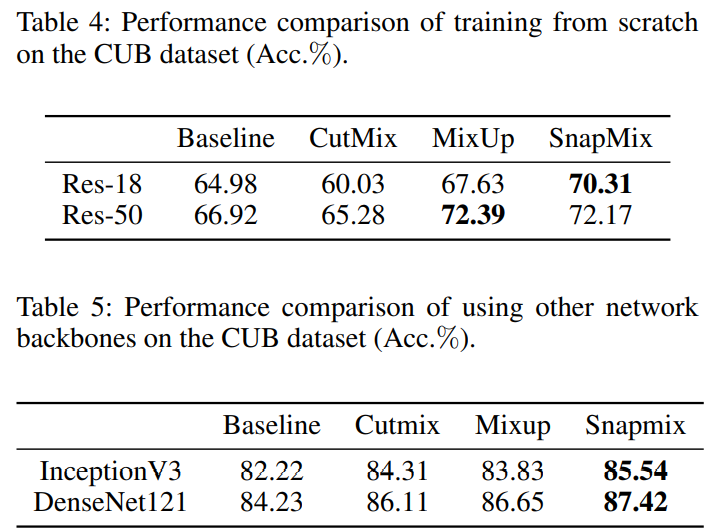

snapMix的超参数α决定一个beta分布,snapMix对α值不是很敏感
5 结论
细粒度数据增广方法SnapMix,通过考虑语义对应关系来生成具有更合理监督信号的训练数据。

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









