







原理部分
KNN算法原理
参考博客:https://blog.youkuaiyun.com/jmydream/article/details/8644004
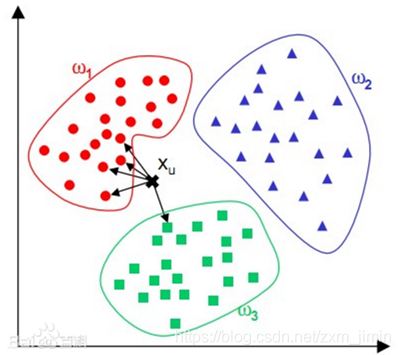
kNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
kNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
计算步骤:
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
2、距离或相似度的衡量
什么是合适的距离衡量?距离越近应该意味着这两个点属于一个分类的可能性越大。
觉的距离衡量包括欧式距离、夹角余弦等。
对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适。
3、类别的判定
投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
优缺点
1、优点
简单,易于理解,易于实现,无需估计参数,无需训练
适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
2、缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
可解释性较差,无法给出决策树那样的规则。
Dense-sift(稠密SIFT)原理
图像检索总是用SIFT(利用了检测子)
大多数情况下我们并没有训练样本。因此,我们需要利用人的经验过滤区分性低的点(除此之外还引入了IDF进一步加权)。因此,大部分检索问题都利用了检测子,而不是密集采样。
图像识别问题大多用Dense-SIFT
Dense-SIFT在非深度学习的模型中,常常是特征提取的第一步
对于图像识别问题来说,由于有充足的训练样本(正负样本均充足)。通过对训练样本的学习,我们会学习一个分类器。
总而言之,当研究目标是对同样的物体或者场景寻找对应关系(correspondence)时, SIFT更好。而研究目标是图像表示或者场景理解时,Dense SIFT更好,因为即使密集采样的区域不能够被准确匹配,这块区域也包含了表达图像内容的信息。
代码实现
KNN算法实现
实现最基本的 KNN算法
class KnnClassifier(object):
def __init__(self,labels,samples):
""" Initialize classifier with training data.使用训练数据初始化分类器 """
self.labels = labels
self.samples = samples
def classify(self,point,k=3):
""" Classify a point against k nearest
in the training data, return label.
在训练数据上采用 k 近邻分类,并返回标记
"""
# compute distance to all training points 计算所有训练数据点的距离
dist = array([L2dist(point,s) for s in self.samples])
# sort them 对它们进行排序
ndx = dist.argsort()
# use dictionary to store the k nearest 用字典存储 k 近邻
votes = {}
for i in range(k):
label = self.labels[ndx[i]]
votes.setdefault(label,0)
votes[label] += 1
return max(votes, key=lambda x: votes.get(x))
定义一个类并用训练数据初始化非常简单 ; 每次想对某些东西进行分类时,用 KNN 方法,我们就没有必要存储并将训练数据作为参数来传递。用一个字典来存储邻近标记,我们便可以用文本字符串或数字来表示标记。在这个例子中,我们用欧式距 离 (L2) 进行度量。
我们首先建立一些简单的二维示例数据集来说明并可视化分类器的工作原理,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4103
4103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









