







文章目录
BOW模型
Bag-of-words models
研表究明,汉字序顺并不定一影阅响读。比如当 你看完这句话后,才发这现里的字全是都乱的。

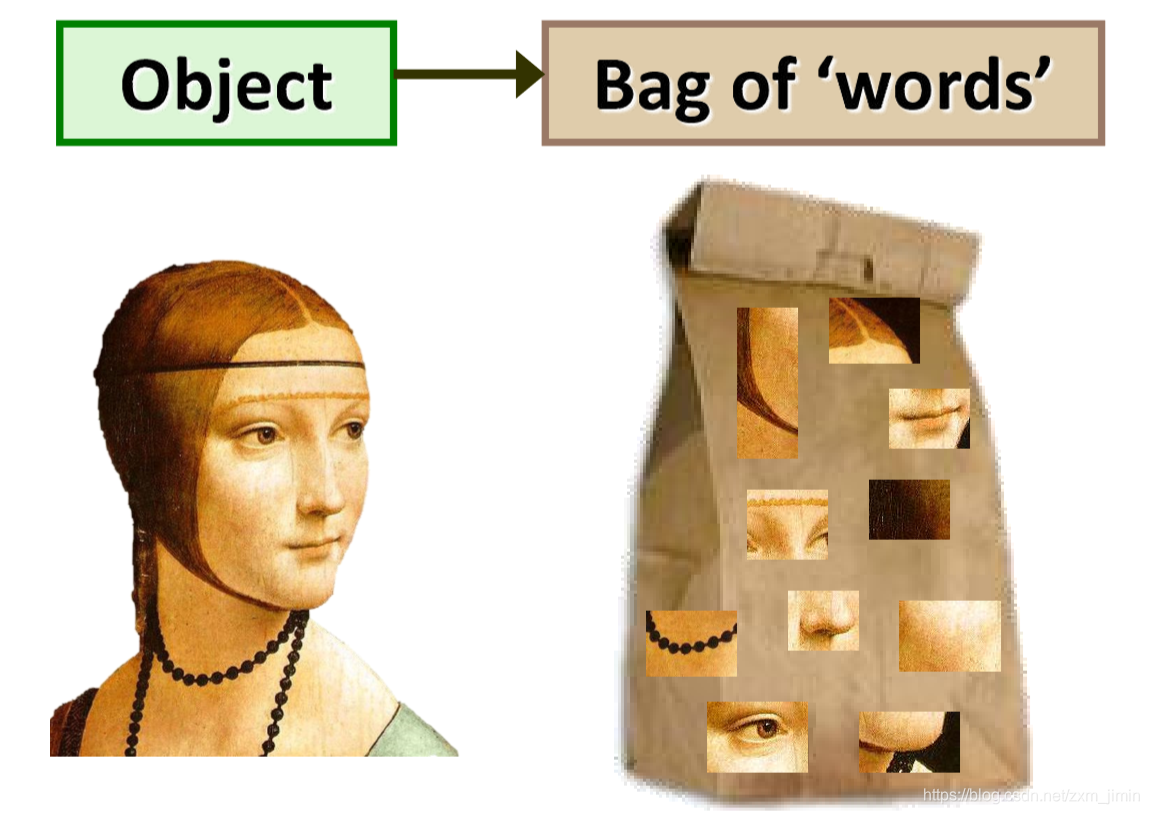
视觉上具相似性的图像。这样返回的图像可以是颜色相似、纹理相似、图像中的物体或场景相似;总之,基本上可以是这些图像自身共有的任何信息。
因此,有了Bag of features模型
Bag of feature:图像检索流程
1. 特征提取、学习 “视觉词典(visual vocabulary)
从我们的图片库中。提取每张图片的特征,作为视觉单词。
这通常可以 采用 SIFT 局部描述子做到。
关于SIFT的更多内容可以移步我另一个博客 https://blog.youkuaiyun.com/zxm_jimin/article/details/88597258
它的思想是将描述子空间量化成一些典型实例,并将图像中的每个描述子指派到其中的某个实例中。这些典型实例可以通过分析训练图像集确定,并被视为视觉单词。
从一个(很大的训练图像)集提取特征描述子,利用一些聚类算法可以构建出视觉单词。
聚类算法中最常用的是采用 K-means。视觉单词是在给定特征描述子空间中的一组向量集。
基本Kmeans算法介绍及其实现
参考博客:https://blog.youkuaiyun.com/qll125596718/article/details/8243404

K-means算法下的聚类中心,即特征点——就是我们所说的视觉词典。
(一旦训练集准备足够充分, 训练出来的码本( codebook)将 具有普适性)
我们用视觉单词直方图来表示图像,则该模型便称为 BOW 模型。
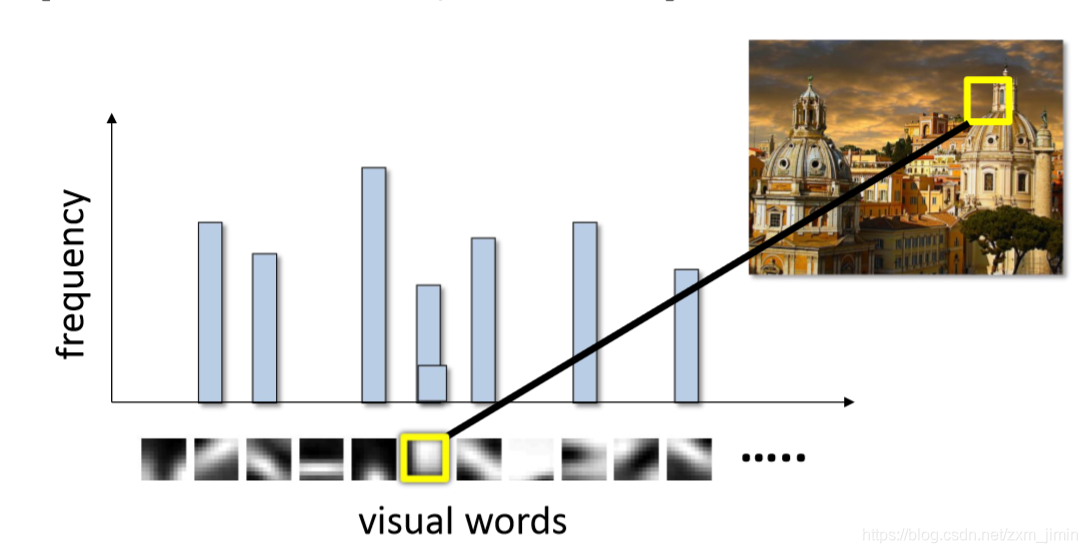
所有视觉单词构成的集合称为视觉词汇,有时也称为视觉词典(visual vocabulary)、视觉码本。对于给定的问题、图像类型,或在通常情况下仅需呈现视觉内容,可以创建特定的词汇。
2. 针对输入特征集,根据视觉词典进行量化
• 对于输入特征,量化的过程是将该特征映射到距离其最接近的 codevector ,并实现计数
• 码本 = 视觉词典
• Codevector = 视觉单词
我们的目标是,类内距离小,类间距离大
对于相似的图片,找到相同的特征点(视觉词汇)
怎样找到合适的特征点(视觉词汇),需要根据输入特征集来判断
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









