




十大机器学习算法–K-means聚类和KNN算法
文章目录
1、K-means聚类(无监督学习)
1.1基本原理
1.1.1聚类分析
(1)聚类分析是数据挖掘中的概念,其核心是根据相似性原则,在数据对象中找出隐藏的有价值的信息。其做法是把具有较高相似度的数据对象划分为同一类簇,差异度大的数据对象分为不同类簇,最终使得同一类簇中的数据比其他类簇中的数据更具有相似性。(物以类聚)
(2)典型聚类算法的三个阶段:特征选择和提取—>相似度计算—>划分类别
(3)聚类算法的类别:层次聚类算法和划分聚类算法
1.1.2 K-means聚类原理
(1)原理:K-means聚类属于划分聚类算法,其基本原理是将数据集(n个数据)划分为K个集群(cluster),使得每个数据属于离他最近的均值(聚类中心)的所属集群。其中,欧氏距离作为衡量不同数据间相似度的指标,欧氏距离越大,相似度越小。
(2)核心思想:首先在数据集中随机选择K个聚类中心Ci,计算其他数据点到这些聚类中心的欧氏距离,不同数据点将被划分到距离最近的聚类中心所属的类簇中。然后计算K个不同类簇的平均值(mean值),作为各类簇新的聚类中心,进行下一次迭代。直到聚类中心不再改变或者迭代到指定的最大迭代次数。
1.2基本步骤
1.2.1K-means算法的步骤
(1)在数据集中随机选择K个样本作为初始聚类中心;
(2)计算其余数据点到K个聚类中心的欧氏距离,并将这些数据点划分到最近类簇中心的集群中;
(3)计算不同类簇中数据点的均值;
(4)将K个新的均值作为新的聚类中心,重复第2、3步,直到聚类中心不改变或者迭代结束。
1.3算法的优缺点
1.3.1优点
(1)可以根据较少的已确定的聚类样本的类别对部分新的数据进行划分类别;
(2)算法的迭代优化功能可以在已完成的聚类上再次进行迭代,修正剪枝确定部分样本的聚类,优化了初始无监督学习样本分类不合理的地方。
1.3.2缺点
(1)K个初始聚类中心是随机选择的,没有选择标准,一旦初始聚类中心选择不好,将严重影响聚类效果,无法得到有效的聚类结果;
(2)初始聚类中心的个数K需要事先给定,但K值往往是难以估计的,不同K值将得到不同聚类结果;
(3)算法适用于数值型数据,且要求数据是球形簇,对非球形簇无法处理。而且面对较大数据样本时,算法的时间开销大。
(4)容易陷入局部最优解。
1.3.3K-means算法的改进
(1)优化选择初始聚类中心:基于萤火虫优化的加权K-Means算法;
(2)优化聚类速度,改进容易陷入局部最优:基于改进森林优化算法的K-Means算法。
2、K近邻算法(监督式学习)
2.1基本原理
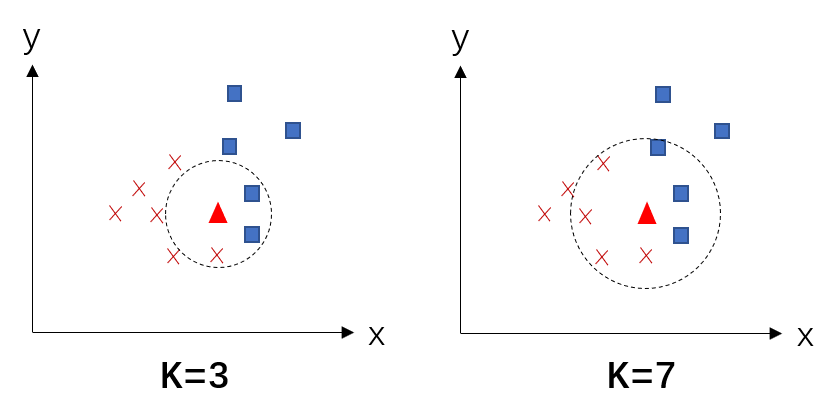
KNN是一种最简单的机器学习算法,是一种非参、惰性学习的模型(即不会对数据作任何假设,且不需要大量训练),构建模型只需要保存训练数据集的数据即可。其基本原理是:对新的测试样本数据进行分类时,选择它距离最近(即相似度最高)的K个训练集样本作为该测试样本的分类依据。K个训练集样本中哪种类别最多,新数据就被划分为哪种类别。原理图如下,当K=3时,新数据三角形被划分为方块,当K=7时,新数据被划分为叉:
2.2关键参数
影响KNN预测性能的参数主要有两个:K的取值和距离的度量方式。
2.2.1 K的取值
(1)K值的影响:K的取值指的是选择距离最近的训练集样本的个数,由原理可知,K值不同,预测结果可能不一样。一般情况下,K值从1逐渐增大时,预测性能变好,但是当K值超过某个数值后,预测性能组件下降。
(2)K值的选择:可以通过交叉验证等方式选择(即将已有数据集划分为训练集和验证集,逐步增加K值,根据所得预测误差选择合适的K值)。通常K取值较小,且最好取奇数,防止最近的K个训练集样本占比相同带来的影响。
2.2.2 距离的度量方式
特征空间中样本间的距离表示不同样本的相似度,在K近邻算法中需要根据实际需求来选择计算测试的新数据与训练集样本数据的距离的度量方式。常用的度量方式有欧氏距离和曼哈顿距离。
(1)欧式距离:x1,x2表示两个不同的样本,x1有n个特征,分别是x11,x12,…. x1n,x2的n个特征分别是x21,x22,…. x2n。两者之间的欧式距离计算公式如下:

由于样本有多个特征,为防止特征的取值范围差异大带来影响,所以应该对样本的不同特征进行标准化处理。
(2)曼哈顿距离:还是上面的两个样本,两者之间的曼哈顿距离计算公式如下:
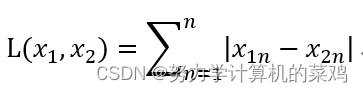
当处理实际问题时,需要根据问题选择距离的度量方式,如果以上两种方式都不符合需求,那么需要寻找新的距离计算方法。
2.3算法优缺点
2.3.1优点
(1)模型简单,由于不需要对数据进行假设(即惰性学习),所以训练时间快;
(2)对异常值不敏感。
2.3.2缺点
(1)由于需要保存所有训练集数据,所以消耗内存大;
(2)因为需要逐一计算出与K个训练集最近样本的距离,所以对新数据的预测较慢。
参考文章
博文《K-近邻算法(KNN)》
软件工程小施同学博文《K-Means聚类算法》

















 10万+
10万+




 到【灌水乐园】发言
到【灌水乐园】发言







