



自编码器通俗易懂的解释(Why-What-When-How)
前言:
前段时间随着Sora的发布,生成式大模型赚够了大众的评论和眼光,可谓是风头无两。简单了解过Sora就知道,它是Diffusion model(扩散模型)和Transformer 两种技术架构的结合。其中Transformer 基于Attention机制(即注意力机制),而大部分Attention模型都是依附于Encoder-Decoder 框架进行实现的。编码器(Encoder)和解码器(Decoder)作为自编码器的基本组成部分,有着相同之处。同时,变分自编码器作为一种比Sora简单的生成式模型,学习变分自编码器可以有助于我们理解Sora的部分工作原理。本文致力于向各位对自编码器感兴趣的朋友通俗易懂的讲解自编码器,当然由于笔者知识有限,行文过程若有错误,也希望各位朋友不吝赐教。
Why-自编码器出现的原因:
自编码器作为一种无监督式学习模型,是由 Rumelbadt、Hinton和 Williams 于1986年首次提出,其最开始的出发点是为了以最小误差重建输入值。进一步的解释就是要让算法自己找出数据的潜在空间的特征表示,并能够从特征还原到原数据的近似。也许有朋友会问,自编码器重建输入值的意义在哪里?其实,重建输入值只是表象,深层含义是为了能够找出输入数据中最能代表数据本身的那些未直接能表现或被感知的隐藏因素、进而加深对输入数据的理解。
What-自编码器的结构、原理及其分类:
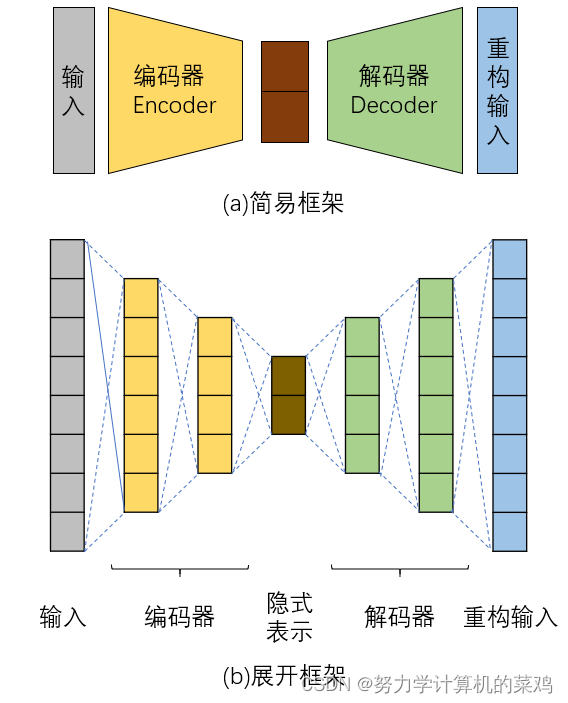
(1)结构:自编码器由编码器、隐式表示(也称压缩表示)和解码器(即 Encoder、Code和 Decoder),其常规的网络架构示意图如图1。其中,编码器指从输入到隐式表示中间的部分,用于将原始输入数据进行编码压缩、提取出重要信息;隐式表示就是原始输入的低维表示,其保存了原始数据中最关键的信息;解码器是隐式表示到输出中间的部分,作用是将隐式表示重建回原始数据。一般来说,编码器和解码器的结构是关于隐式表示对称的。
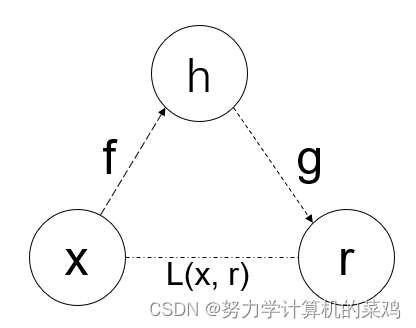
(2)原理:自编码器的原理如图 2所示。概括性的来说,自编码器就是希望通过编码器将原始数据映射到一个合适的低维特征空间中,使得解码器解码出的输出与原始数据有较小的误差。在经典的自编码器框架中,编码器和解码器都是神经网络,原则上它们可以拟合到任何函数。如图2,编码器旨在拟合原始数据×到特征空间h的映射函数f,以找到尽可能保留原始数据信息的特征空间为目的;而解码器则是拟合特征空间到重构输入r的映射函数g,使得可以更精确的重建原始输入。而衡量自编码器性能优劣的指标为原始输入和重构输入之间的误差L(x,r),这个误差表示两者之间的距离度量,可选择不同的度量方式。其中,隐式表示中有多个被选择出来的特征,每个特征为一个具体的数值,可能代表数据中不同的信息。
(3)特点:自动学习、数据有损、数据相关·
a.自动学习:只需要给自编码器一堆数据样本,它会自动从中学习特征,而不需要做其他的工作;
b.数据有损:由于编码器的功能,它只会保留输入数据中最主要的信息,这意味着数据信息是有损失的,当解码器重建输入时,并不能完整重建输入;
c.数据相关:自编码器目的是以最小误差重构原始输入,表明它只能学习和重构与输入相似的一类信息,对于差别明显的其他输入没有太大的作用。因此为解决自编码器这个问题,变分自编码器应运而生。
(4)分类:稀疏自编码器、收缩自编码器、降噪自编码器、堆栈自编码器、变分自编码器。
为了使自编码器能够尽可能重构原始输入,不少研究人员在构建模型时加入了不同的技巧,因此诞生了不同的自编码器类型。·
a.稀疏自编码器:对隐藏层单元增加了稀疏性约束,其目的是为了更好的学习到有用的特征,可以认为它是对带有隐含变量的生成模型的近似最大似然训练。
b.收缩自编码器:在目标函数上添加惩罚项,如式1,该惩罚项是平方 Frobenius范数(元素平方值和),作用于与编码器的函教相关偏导数的Jacoblan知阵(即一阶偏导数),目的是使得隐式表示h映射到原始输入更小的邻域内,即达到收缩的目的,减少输入扰动的影响。
c.降噪自编码器:在原始输入中添加随机噪声,模拟了输入数据受到噪声的情形,并尝试从噪声污染的输入中重构原始数据,提高了模型的鲁棒性和泛化能力。
d.堆栈自编码器:也叫深度自编码器,是多个自编码器级联而成,即增加了隐藏层的深度,采用贪心逐层堆盏训练的方法,以求获得更好的特征提取能力和训练效果。·
e.变分自编码器:与自编码器最大的区别就是将隐式表示由原来的离散点改为了一种分布(均值和方差表示),以概率的方式描述特征空间,继而从分布上随机取数作为解码器的输入。由于这种随机性,使得变分自编码器具有了数据生成的能力,而不仅仅是重构输入。
When-自编码器适用场景
介绍完自编码器出现的原因、结构、特点和分类,那我们会问自编码器应该在什么时候使用呢?因为自编码器的编码器具有特征降维、数据降噪、信息提取的功能,而解码器可以做样本生成,所以基于自编码器的特点,其常被使用在以下几个场景中:
a.图像处理:图像作为高维的数据,一张图片中蕴含的信息是复杂且丰富的。自编码器经过训练,它可以被用于图像的特征提取,图片压缩和降噪,以及图像的修复和增强中;
b.语音识别:自编码器不仅可以从原始的语音数据中提取到对应的高级特征表示,还可以去除语音中多余的噪音,从而提高了语音识别的鲁棒性;·
c.自然语言处理:自编码器在自然语言处理中主要用于文本压缩和文本生成。通过学习,白编码器可以将大段文本压缩为更短的特征变量,达到文本压缩的作用,进而进行诸如文本检索和情感分析等任务。而且自编码器可以学习文本特征如语法和语义特征,之后生成类似的新文本;·
d.数据挖掘:数据挖掘指的是从海量数据中挖掘出那些有用的、隐含的知识,这与自编码器具有数据降维的特点不谋而合。·
除了以上这些使用场景,自编码器还在推荐系统、异常检测等方面。虽然自编码器使用广泛,但是其特征空间的可解释性限制了它的进一步发展,这也将是未来一段时间内,自编码器的一个重点研究方向。
How-如何搭建并训练自编码器
了解了自编码器的基础知识后,我们就开始准备搭建和训练自编码器了。现在很多时候自编码器都会只使用自编码的编码器和隐式表示这部分,而舍弃掉解码器到重构输入这部分,这样就可以提取出样本数据的隐式特征,进而用作诸如分类的其他用途。搭建自编码器分为几个部分:
(1)数据准备:收集所需要的数据,并将数据分为训练集、测试集和验证集。对数据做预处理,比如使用归一化让数据范围一致,避免数据差异带来的问题。
(2)选择自编码器模型架构:根据所研究的问题,选择合适的自编码模型架构。最传统和简单的自编码器只有1层隐藏层,可以用于数据样本为一维矢量的问题,例如异常检测和分类等。为了提高模型准确性和泛化性,可以使用多层自编码器。当数据样本为图片这类高维数据时,则可以选择卷积自编码器,与一般编码器不同的是,它的由卷积编码器和解码器都由卷积层和池化层组成,可以对图片实现降噪和提取特征等功能。简单来说,选择架构就是确定所用自编码器的隐藏层数、隐藏层神经元数目和隐藏层的类型(线性层、非线性层,还是卷积层)。
(3)确定损失函数、激活函数和优化器:损失函数表示重构输入与实际输入之间的距离,常用的损失函数有均方差误差(MSE)和交叉熵误差。其中当自编码器用作回归问题时,即当解码器是线性重构数据时,常用MSE;而当自编码器用作分类问题,当解码器激活函数为Sigmoid时,常用交叉熵。而自编码器常用的激活函数有Sigmoid、ReLu和Tanh函数。其中Sigmoid常用于输出层的二分类问题;ReLU常用于隐藏层的非线性激活函数,能够缓解梯度消失问题;Tanh函数:常用于输出层的多分类问题。而优化器则可以根据实际需要选择随机梯度下降(SGD)、Adam和RMSProp等。
(4)训练、评估并调优:使用训练集数据对模型进行训练,可使用批量梯度下降等优化算法。训练结束后,借助测试集评估模型性能。若有需要,可对模型参数进行调整,以提高性能。
(5)模型应用:将训练得到的模型应用于验证集,查看其泛化能力。也可以寻找与数据集同类型的任务进行验证。
以上就是本人整理的关于自编码器的一些知识,希望能够帮到想要了解自编码器的朋友。当然,行文过程中不免会出现一些错误,希望大家指出。一起学习进步吧。

















 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









