




DeepSeek-MoE:医院里的"智能分诊系统"大揭秘
想象一下,你走进一家超级智能医院,这里有1000位医生,但不是所有医生都懂所有疾病
术语说明图:
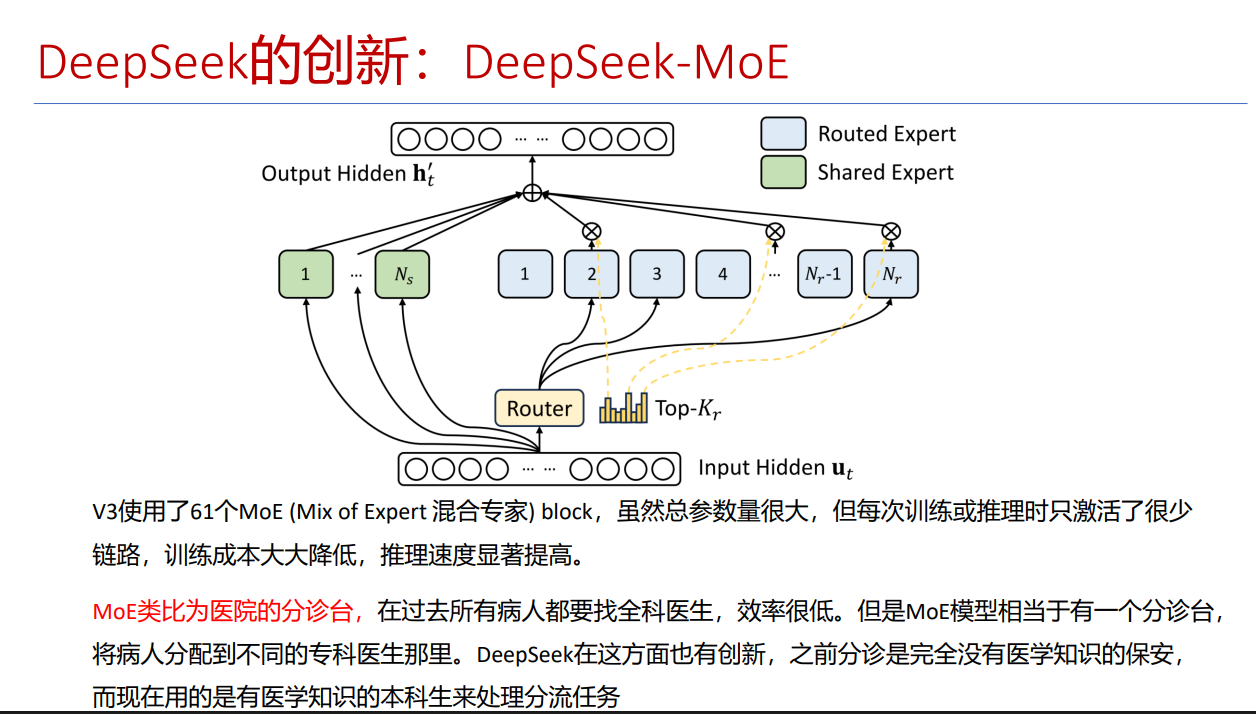
传统医院(Dense模型):
- 你生病了,不管是什么病,都必须找同一位全科医生
- 这位医生必须懂所有疾病,所以要学很多东西,但可能不是特别精通
- 你得等很久,因为医生要处理所有病人,就像一个人要包揽所有工作
DeepSeek-MoE医院(智能分诊系统):
-
智能分诊台(Router):一进门就有AI分诊台
- 你告诉分诊台:“我头疼、发烧、喉咙痛”
- 分诊台立刻判断:这可能是感冒或流感
- 它会把你看诊指引到"呼吸科"或"感染科"
-
专科医生(Expert):
- 呼吸科里有专门的"感冒专家"、“流感专家”
- 感染科里有"病毒专家"、“细菌专家”
- 你被引导到"感冒专家"那里,而不是所有专家
-
基础医生(Shared Expert):
- 医院还有一位"基础医生",他不专精某种疾病
- 但他能处理所有病人的通用问题:量体温、测血压、问基本症状
- 他帮助分诊台判断病情,也帮助医生了解病人基本状况
为什么这个系统这么厉害?
实际例子:
- 你来医院说:“我头疼、发烧、喉咙痛”
- 分诊台判断:可能是感冒
- 你被引导到"感冒专家"那里
- 感冒专家问你:“你有没有流鼻涕?”
- 你回答:“有”
- 感冒专家立刻判断:是普通感冒,不是流感
- 你得到正确的诊断和治疗
比传统医院快多少?
- 传统医院:你等了45分钟,医生问了20个问题,最后说"可能是感冒"
- DeepSeek-MoE医院:你等了15分钟,医生直接问了3个关键问题,立刻确诊
DeepSeek-MoE的三大创新点
-
细粒度专家划分:
- 感冒专家还细分为"普通感冒专家"、“病毒性感冒专家”、“过敏性感冒专家”
- 就像医院里感冒专家还细分了更多小专科
-
共享专家分离:
- 基础医生(处理通用问题)和专科医生(处理特定问题)是分开的
- 不会把基础医生也当成感冒专家,减少知识冗余
-
智能分诊不加负担:
- 分诊台不会让某个专家太忙,会合理分配病人
- 不需要额外训练"分诊员",直接通过现有系统优化
为什么这个系统更高效?
- 计算资源节省:不需要所有医生都参与,只有相关专家被激活
- 比如:你只需要感冒专家和基础医生,不需要流感专家
- 专业度提升:专家专注于特定问题,诊断更准确
- 响应速度更快:分诊台快速引导,不需要等待
生活中的类比:你家的智能音箱
- 你问:“明天天气怎么样?”
- 智能音箱知道这是天气问题,直接调用天气服务
- 你问:“我想听周杰伦的歌”
- 智能音箱知道这是音乐问题,直接调用音乐服务
- 它不会把天气问题交给音乐服务,也不会把音乐问题交给天气服务
DeepSeek-MoE就是AI领域的"智能音箱",让每个问题都能被最合适的专家处理,既高效又精准!

















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









