







文章信息

论文题目为《Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting》,论文提出了一种使用视觉-语言大模型,利用图像和文本信息增强时序预测模型,名为Time-VLM.

摘要

近年来,时间序列预测的进展已经探索了通过文本或视觉模态来增强模型,以提高准确性。虽然文本提供了上下文理解,但它通常缺乏细粒度的时间细节。相反,视觉捕捉了复杂的时间模式,但缺乏语义上下文,不能充分发挥这些模态的互补潜力。为了解决这个问题,我们提出了Time-VLM,一种新的多模态框架,利用预训练的视觉-语言模型(VLMs)来桥接视觉、文本和时间模态,从而增强预测。我们的框架包含三个关键组件:(1)检索增强学习器,用于通过记忆增强提取时间特征;(2)视觉增强学习器,用于编码时间序列作为信息性特征;(3)文本增强学习器,用于生成上下文文本描述。这些组件与冻结的预训练VLM协作,以生成多模态嵌入,用于最终预测。广泛的实验表明,Time-VLM在各种数据集上表现优越,特别是在小样本和零样本场景中,从而为多模态时间序列预测开辟了新方向。

引言

时间序列预测在许多领域中起着关键作用,包括金融、气候、能源和交通。准确的未来趋势预测有助于更好的决策、风险管理和资源配置。传统的统计模型,如ARIMA,一直是时间序列分析的首选方法,但它们往往难以捕捉复杂的非线性依赖关系。
相比之下,深度学习方法,如循环神经网络(RNNs)和基于Transformer的模型,通过学习从原始数据中提取复杂的时间模式,如基于块的重构、自相关机制和频率分解策略,已经彻底改变了这一领域,提供
了在各种预测任务中优越的性能。然而,这些模型在领域泛化和训练数据有限的情境下往往表现不佳,特别是在小样本或零样本设置中。为了克服这些问题,研究人员开始通过增加文本和图像等额外模态来增强时间序列预测,这些模态提供了互补的信息,可以提高预测的准确性。
文本增强模型:文本数据,如任务特定的知识或领域事件,提供了有价值的上下文来进行时间序列预测。例如,在金融预测中,通过添加超越原始数据的洞察,如市场描述或政策变化,可以提高准确性。像Time-LLM和UniTime这样的做法,将时间序列映射为文本表示,利用大语言模型(LLM)捕捉上下文影响并推断预测(图1,右)。然而,这些模型面临两个挑战:(1)连续时间序列与离散文本之间的模态差异;(2)预训练的词向量嵌入很少为时间序列预测优化,从而限制了对细粒度时间模式的捕捉。
视觉增强模型:与此相反,将时间序列数据转化为视觉表示,例如通过格拉门角场(GAF)或复发图,能够使模型识别和利用潜在的视觉模式,从而促进使用图像化特征学习技术(例如,卷积神经网络,CNN)提取复杂的时间关系(图1,左)。最近的研究展示了时间序列和视觉之间的自然对齐,因为它们都是连续的并且共享结构相似性,允许预训练视觉模型有效提取层次化的时间特征。然而,这些模型缺乏语义上下文,限制了它们捕捉领域特定的知识或事件驱动的洞察力,这对实际的预测至关重要。
尽管文本和视觉模型已有进展,但将这两种模态与时间序列结合的研究仍然处于欠开发状态。视觉-语言模型(VLMs)在对齐视觉和文本以进行多模态推理任务方面表现出色。在此基础上,我们引入了Time-VLM,将VLM扩展为包括时间序列作为第三模态。每种模态——文本(用于语义上下文)、视觉(用于空间模式)和时间序列(用于时间动态)——提供了独特的优势。现有方法通常专注于单一模态,限制了其利用三者互补优势的能力。我们的方法利用预训练的VLMs来有效集成时间序列、视觉和文本模态,增强时间序列预测的能力。
通过将时间序列投影到统一的视觉-语言语义空间,Time-VLM使得跨模态的交互成为可能,结合了各模态的优势,同时缓解了各自的局限性。具体而言,Time-VLM引入了三个关键组件:(1)检索增强学习器,通过记忆库交互增强时间特征,捕捉局部和全局特征;(2)视觉增强学习器,适应性地将时间序列转化为图像,利用多尺度卷积、频谱编码和周期编码,保持细粒度的细节和高层结构;(3)文本增强学习器,生成丰富的上下文提示(例如,统计数据描述),以补充视觉表示。这些模块与VLMs协同工作,以重新集成时间序列、视觉和文本模态,从而产生通过微调预测器的增强预测。
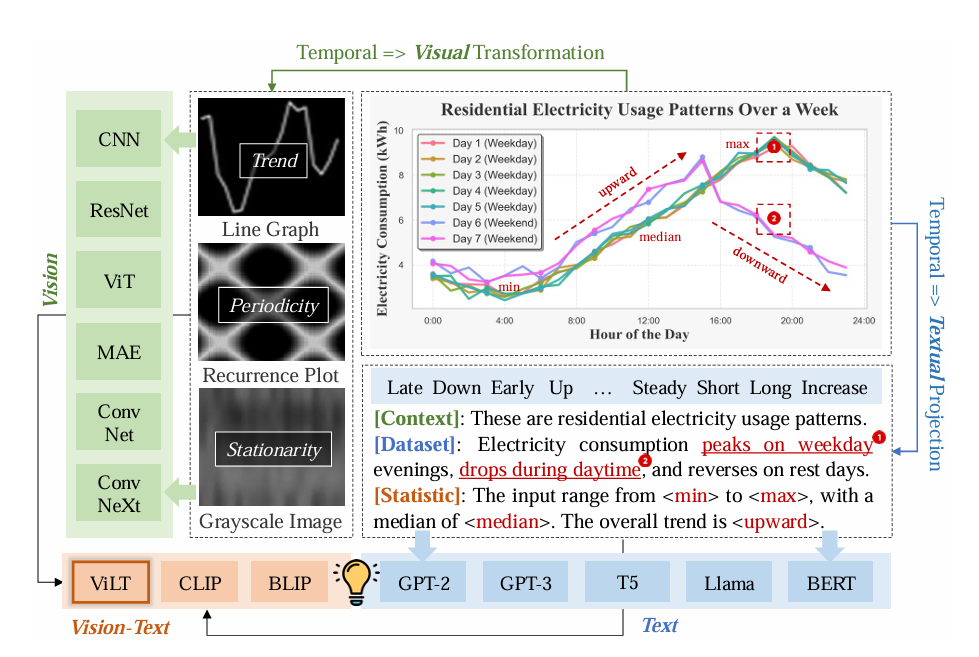
图1 Time-VLM示意图

方法论

1.RAL模块
RAL模块通过基于补丁的处理和记忆增强的注意力提取高层次的时间特征。它动态检索和集成时间序列中的复杂模式,以适应时间序列的结构变化,从而提高预测性能。该过程分为两个阶段:
补丁嵌入:输入时间序列被划分为重叠的patch。每个patch被投影到一个隐藏空间,并添加位置嵌入以保存时间顺序。得到的补丁嵌入用于捕捉局部时间模式。
记忆增强注意力:一组可学习的记忆查询Q通过多头注意力与补丁嵌入进行交互,补丁嵌入被投影为键K和值V计算如下:
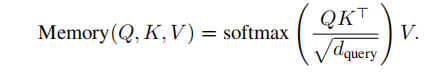
为了更好地捕捉复杂的时间动态,引入了两层层次化的记忆结构:局部记忆:捕捉个体补丁中的细粒度模式,用于短期依赖。全局记忆:聚合来自多个补丁的信息,用于长期依赖和高级模式。这两个记忆通过门控机制融合:
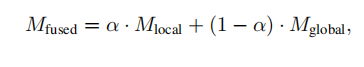
其中,α是一个可学习的门控参数,自动平衡局部和全局记忆的贡献。
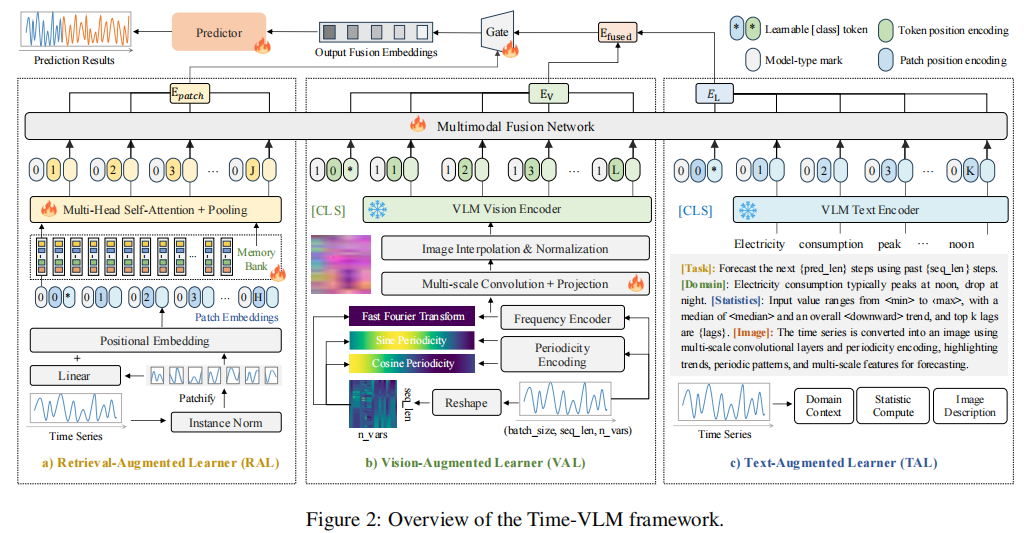
图2 模型框架图
2.VAL模块
VAL模块自适应地将时间序列转化为图像,通过多尺度卷积、频率和周期编码操作提取精细的时空特征。具体操作如下:
频率和周期编码:为了捕捉频谱和时间依赖性,VAL模块对输入时间序列应用两种互补的编码技术:
频率编码:通过快速傅里叶变换(FFT)提取频率成分:
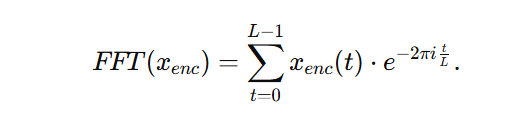
周期编码:通过正弦和余弦函数对每个时间步的周期依赖进行编码:
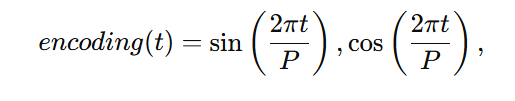
其中 P 是周期超参数。
多尺度卷积:使用多尺度卷积操作提取局部和全局的时序特征,增强捕捉高级和细粒度的时间模式。
3.TAL模块
TAL模块为输入时间序列提供上下文文本表示,包括预定义(例如描述性任务)或动态生成的文本,灵活适应各种场景对于动态生成的提示,TAL提取时间序列的关键统计特征,包括:最小值和最大值、基于一阶差分的上升/下降、预测的历史窗口、领域特定的描述。这些特征被格式化为结构化文本提示。例如,生成的提示可能如下:

多模态嵌入提取:生成的图像和文本嵌入通过冻结的VLM产生,生成多模态嵌入这些嵌入捕捉到时间序列的语义上下文,利用VLM的预训练语言理解能力。
时间特征融合:为了增强分布式时间序列和多模态特征,时间嵌入被投影到一个共享的隐藏空间。时间记忆嵌入通过跨模态多头自注意力机制作为查询,并与VLM生成的多模态嵌入作为键和值进行交互。CM-MHA定义为:
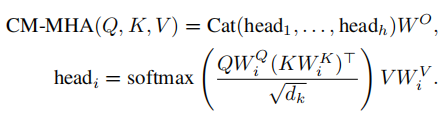

实验

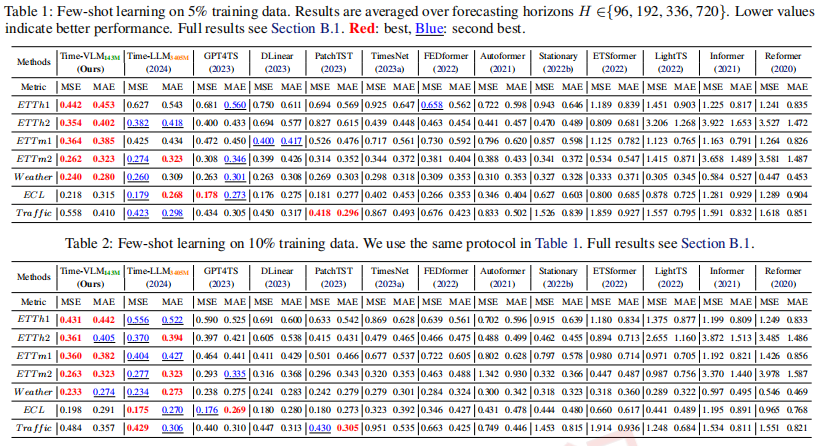
1.少样本预测
通过仅使用5%或10%的训练数据来评估Time-VLM的少样本能力。这评估了其将来自VLM的预训练多模态知识与时间序列特定特征结合,在最少的任务特定数据下实现有效预测的能力。
如表1和表2所示,Time-VLM在各个数据集上持续优于大多数基线模型。例如,在ETTh1数据集上,使用5%训练数据时,Time-VLM相比于第二好的模型TimeLLM减少了29.5%的MSE和16.6%的MAE;在ETTh1使用10%训练数据时,Time-VLM的MSE和MAE分别优于TimeLLM 11.1%和10.5%。在ETTh1使用5%数据时,Time-VLM在MSE上优于TimeLLM 7.7%,在MAE上优于TimeLLM 9.4%。
Time-VLM与传统模型(例如,PatchTST,FEDformer)之间的性能差距在少样本设置中更加明显,展示了多模态在数据稀缺场景下的优势。值得注意的是,Time-VLM只需要143M参数,显著少于TimeLLM的3405M,突出了其效率。
2.零样本预测
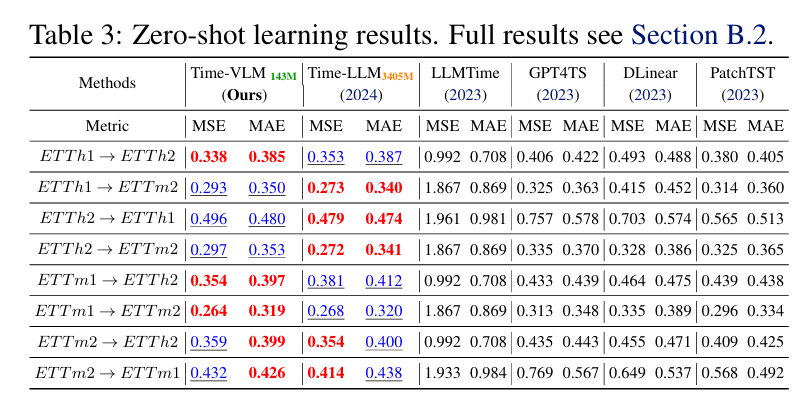
我们评估了Time-VLM在跨领域设置中的零样本能力,其中模型通过有效利用来自不相关领域的知识对未见过的数据集进行预测。为了确保更全面和严格的比较,我们使用了ETT数据集作为Time-LLM的基准,相关数据总结在表3中。
Time-VLM展示了强大的零样本泛化能力,持续优于具有更少参数的最先进模型。例如,在ETTh1 → ETTh2的任务中,Time-VLM在MSE和MAE上分别优于TimeLLM 4.2%和5.0%;在ETTm1 → ETTm2的任务中,它在MSE上优于TimeLLM 7.1%,在MAE上优于TimeLLM 3.6%。在ETTm2 → ETTm2任务中,Time-VLM与TimeLLM的MSE差异仅为1.4%,MAE差异仅为0.3%。

结论

Time-VLM是一种利用预训练VLM来统一时间、视觉和文本模态的时间序列预测框架。通过集成RAL、VAL和TAL,Time-VLM弥合了模态之间的差距,使得跨模态交互成为可能。广泛的实验表明,在多个数据集上,尤其是在少样本和零样本场景下,Time-VLM超越了现有方法,同时保持了高效性。我们的工作为多模态时间序列预测开辟了新的方向,突出了VLM在捕捉时间动态和语义上下文中的潜力。
值得注意的是,Time-VLM仅依赖原始时间序列数据,无需外部信息,确保了公平的比较,并展示了其直接从数据中生成文本和视觉表示的能力。这种设计不仅提高了准确性,还强调了框架的鲁棒性,尤其是在外部数据稀缺或不可用的领域。


















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











