






文章信息
文题目为《Landscape Surrogate: Learning Decision Losses forMathematical Optimization Under Partial Information》,来源于NeurIPS 2023。文章提出了一种统一训练方法,用于解决智能预测 + 优化、代理学习等耦合学习优化问题。并且提出 LANCER 方法,通过构建平滑可学习的景观代理模型M替代f∘g,有效解决训练难题。实验表明,LANCER 在合成数据和实际问题(如组合优化、投资组合选择)中表现出色,尤其在高维问题上优势明显。
摘要
最近,集成学习优化领域的研究成果表明,在优化问题仅部分已知,或通用优化器未经专家调整就表现不佳的情况下,该领域仍具有很大的潜力。通过学习一个优化器g,以f为目标来应对这些具有挑战性的问题,优化过程可以借助以往的经验大幅提速。优化器的训练方式有两种,一种是在已知最优解的监督下进行,另一种则是通过优化复合函数f∘g来间接实现。间接训练的方法无需将最优解作为标记,还能处理问题中的不确定性;但这种方法在训练和应用时速度较慢,因为在训练和测试阶段都需要频繁调用优化器g。此外,g的梯度稀疏问题也增加了训练的难度,尤其是在使用组合求解器时。为了解决这些问题,我们提出使用一种平滑且可学习的 “景观替代模型”M,来代替f∘g。这种替代模型可以通过神经网络进行学习,计算速度比求解器g更快,在训练过程中能提供密集且平滑的梯度,还能应用于从未遇见过的优化问题,并且可以通过交替优化高效地学习。我们在合成问题(如最短路径问题和多维背包问题)以及实际问题(如投资组合优化问题)上对该方法进行了测试。结果显示,与最先进的基准方法相比,我们的方法在减少调用g次数的同时,能够取得相当甚至更优的目标值。值得一提的是,在处理计算成本高昂的高维问题时,我们的方法比现有方法表现更出色。
引言
文章主要有两方面贡献,一是理论方法层面,提出统一训练过程,将不同学习优化问题纳入统一框架,加深对部分信息下学习集成优化的理解;二是实践应用层面,提出的 LANCER 方法优势显著,在多类问题实验中表现出色,尤其在高维问题上效果突出。
(1)提出统一训练过程:推导了一种统一的训练过程,用于解决各种耦合学习和优化设置,包括智能预测 + 优化和代理学习。这一过程涵盖了许多以往依赖于完全或部分观察问题信息的工作,推进了对部分信息下学习集成优化的理解,为相关研究提供了一个通用的优化框架。
(2)提出了一种名为 LANCER 的有效且强大的方法来处理上述训练过程。该方法通过使用平滑且可学习的景观代理模型 M 替代f∘g,避免了通过求解器进行反向传播,能够更高效地学习目标参数映射。
问题定义
目前,数学优化问题在不同场景下被广泛研究,已有众多解决方法。然而,实际应用中的问题常因目标或定义的不确定性变得棘手,计算成本也很高。例如,带有非线性目标的组合问题,即便有处理特殊情况的有效方法(如 k -means 算法),整体解决起来依旧困难。
现有的解决思路:(1)学习线性代理成本:引导线性求解器为复杂的非线性问题找到高质量的解决方案,这种方法能自动生成代理混合整数线性规划(MILP)问题,而针对此类问题要有相对高效的求解器。(2)智能预测 + 优化框架:在该框架中,测试时部分问题参数未知,需借助模型(如神经网络)从观测输入中推断。不过,将其扩展到组合问题面临挑战,当前方法常依赖启发式梯度或特定问题结构。
学习代理成本、智能预测 + 优化等方法虽设置和目的不同,但都需学习目标映射来估计潜在优化问题的参数,从而让问题更易处理。本文建立了不同问题族之间的联系,将它们整合进统一框架。核心是构建包含参数化求解器g和原始目标f的复合函数f∘g,这是首次针对这类问题提出的通用优化公式。
但通过梯度下降最小化复合函数f∘g并非易事,它要求对 argmin 算子求导,现有方法存在局限性,如难以应用于组合优化问题、计算雅可比矩阵导致扩展性问题、无法处理黑箱目标函数等。为解决这些问题,文章提出 LANCER 损失统一模型,用可学习的景观代理模型M近似复合函数f∘g ,并采用交替优化算法训练,提升整体性能。实验也验证了该模型的有效性和扩展性。
方法
5.1 统一训练过程
在这项工作中,作者专注于解决以下优化问题:

其中,f是待优化的函数(线性或非线性),x是决策变量,这些变量必须处于可行域内,可行域通常由(非)线性(不)等式以及可能的整数约束来指定,z是问题描述(或问题特征)。例如,如果f是要在图中寻找最短路径,那么x就是待优化的路径,而z代表公式中的节点间距离(或用于估计这些距离的特征)。
理想情况下,希望有一个优化器,可以做到(1)处理损失函数景观的复杂性(例如,高度非线性的目标f,复杂的和可能组合的域f),(2)利用过去解决类似问题的经验,(3)可以处理部分信息设置,当在测试时间做出决定时,仅可以看到可观察的问题描述y,而不能看到真实的问题描述z。
为了设计这样的优化器,我们考虑以下设置:假设对于训练实例,我们可以访问完整的问题描述{zi},以及可观察的描述{yi},而在测试时,只知道其可观察的描述y_test,但不知道其完整的描述z_test。这样的设置自然地结合了不确定性下的优化,其中需要在没有完整信息的情况下做出决策,而完整信息可以在事后获得(例如,投资组合优化)。给定此设置,我们提出以下对训练集的一般训练过程以学习好的优化器:
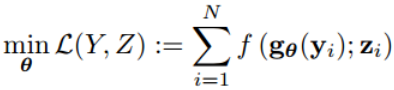
其中gθ是一个可学习的求解器,它直接从可观测问题描述yi返回目标f的高质量解。θ是可学习的求解器的参数。一旦gθ被学习,则可以通过调用x_test = gθ(y_test)来求解具有可观测描述y_test的新问题实例以获得合理的解,或者使用x = x_test作为初始解来继续优化上述原问题。作者旨在使训练过程具有一般性,模型依赖于部分可观测的信息。
5.2 Lancer:学习景观代理损失
在训练过程的每一步,我们都需要调用求解器来计算gθ,这可能是计算开销很大的。此外,gθ是通过上式子的梯度下降来学习的,这涉及到通过求解器的反向传播。该过程的一个问题是梯度仅在某些位置处为非零(即,当系数的变化导致最优解的变化时),这使得基于梯度的优化变得困难。
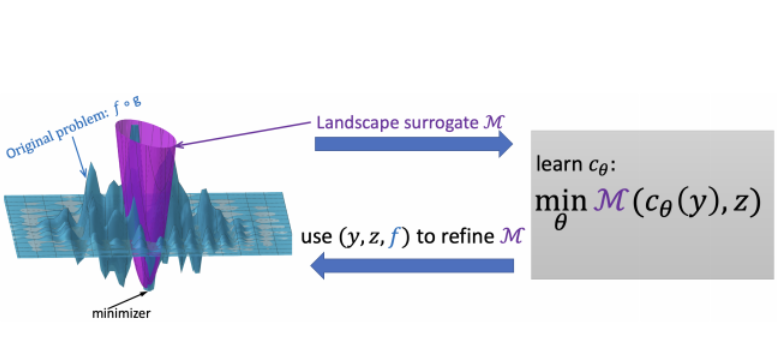
那么可以联合建模复合函数f o gθ吗?虽然gθ可能很难计算,但fogθ可以平滑建模,因为f可以在gθ提供的解周围平滑。如果我们通过景观代理模型M对f o gθ进行局部建模,并直接在M的局部景观上进行优化,那么目标映射cθ可以在无需运行昂贵的求解器的情况下进行训练:
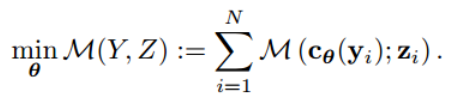
M直接依赖于cθ(而不是gθ)。显然,M不能是任意函数。相反,它应该满足某些条件:1)捕获特定于任务的损失fogθ; 2)可微且平滑。可微性允许我们以端到端的方式训练目标模型cθ(假设c本身是可微的)。其优点在于我们可以避免通过求解器甚至通过f的反向传播此外,M通常是高维的(例如,神经网络),并且可能使cθ的学习问题变得容易得多。问题是如何获得这样的模型M?方法是将其参数化并制定学习问题:
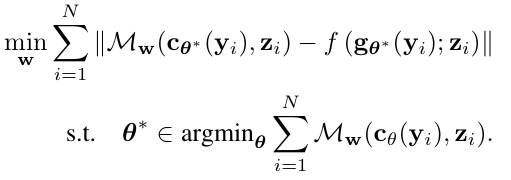
其中模型M:模拟fog这个过程,即是模拟预测+优化这个过程。M的输入是c(y)和z。其中y是特征向量,c(y)是预测模型的结果即预测值,z是真实值。整个模型的输出是优化模型的目标函数值。第一个公式为外层优化:训练模型M的损失函数。使M的输出更加接近于真实的目标函数值。以达到拟合fog的效果。第二个为内层优化:优化的是目标模型即预测模型,让预测值和真实值更接近。其算法如下:
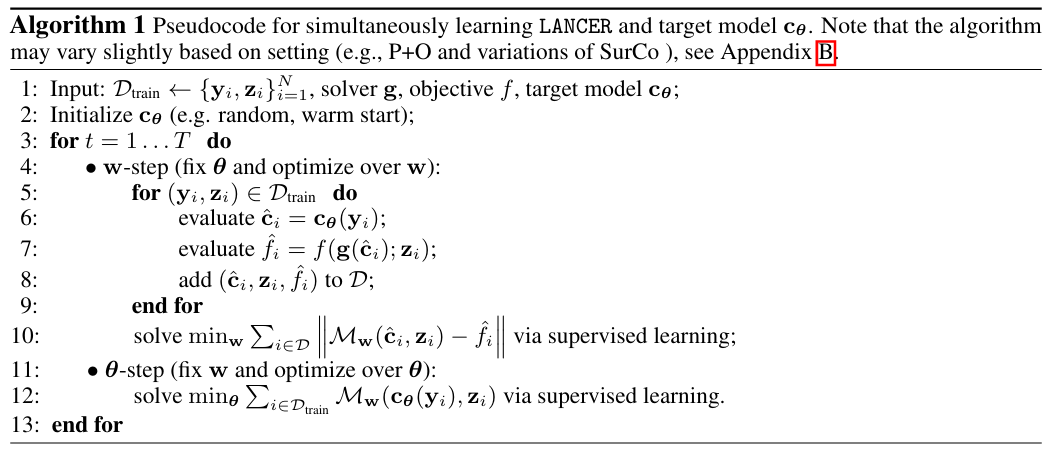
该算法避免了通过求解器甚至通过f的反向传播。唯一的要求是在g的解处评估目标函数f,这可以通过黑盒求解器访问来实现。因此,这种方法消除了与计算组合求解器的导数相关的复杂性和计算费用,使其成为更有效和实用的解决方案。在代码中可以把cθ看作是一个参与者,负责做出某些决定,比如预测未知系数;另一方面,Mw扮演着一个批评者的角色,通过估计目标值f来评估参与者的决定,并向参与者提供反馈。该训练过程完毕后,通常丢弃Mw,因为它是算法的中间结果,只保留cθ(和求解器g)。
实验
作者主要以最短路径和背包问题为背景做了一系列实验,以验证该方法的普适性及其贡献。因篇幅受限,在此不作赘述,感兴趣的读者可阅读原文。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!


















 2400
2400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











