







 超级会员免费看
超级会员免费看
1、pytorch中的卷积
CNN是深度学习的重中之重,而conv1D,conv2D,和conv3D又是CNN的核心,所以理解conv的工作原理就变得尤为重要,卷积中几个核心概念如下。
卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加。
卷积核:又称为滤波器,过滤器,可认为是某种特征。
卷积过程类似于用一个模版去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取。
卷积维度:一般情况下 ,卷积核在几个维度上滑动就是几维卷积。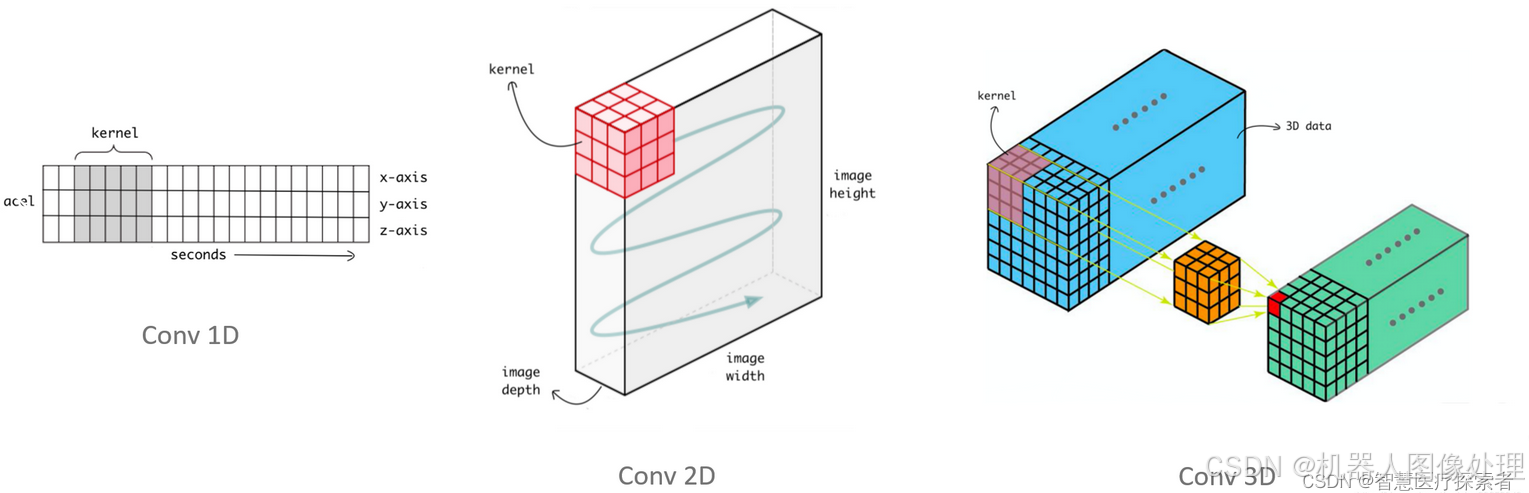
2、nn.Conv1d
一维卷积nn.Conv1d主要用于文本数据,只对宽度进行卷积,对高度不卷积。通常,输入大小为word_embedding_dim * max_length,其中,word_embedding_dim为词向量的维度,max_length为句子的最大长度。卷积核窗口在句子长度的方向上滑动,进行卷积操作。
2.1 函数原型
torch.nn.Conv1d
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









