




1. 古典概型
样本空间有限个基本事件,基本事件等可能发生
P(A)=A包含基本事件数S所有基本事件数P(A)=\frac{A包含基本事件数}{S所有基本事件数}P(A)=S所有基本事件数A包含基本事件数
2. 条件概率
A发生条件下B发生的概率
P(B∣A)=P(AB)P(A)P(B \mid A)=\frac{P(AB)}{P(A)}P(B∣A)=P(A)P(AB)
3. 乘法定理
P(AB)=P(B∣A)P(A)P(ABC)=P(C∣AB)P(B∣A)P(A)P(AB)=P(B\mid A)P(A)\\P(ABC)=P(C\mid AB)P(B\mid A)P(A)P(AB)=P(B∣A)P(A)P(ABC)=P(C∣AB)P(B∣A)P(A)
4. 全概率公式
B1,B2,⋯ ,BnB_1,B_2,\cdots,B_nB1,B2,⋯,Bn是S的一个划分
P(A)=P(A∣B1)P(B1)+P(A∣B2)P(B2)+⋯+P(A∣Bn)P(Bn)P(A)=P(A\mid B_1)P(B_1)+P(A\mid B_2)P(B_2)+\cdots+P(A\mid B_n)P(B_n)P(A)=P(A∣B1)P(B1)+P(A∣B2)P(B2)+⋯+P(A∣Bn)P(Bn)
5. 贝叶斯公式
B1,B2,⋯ ,BnB_1,B_2,\cdots,B_nB1,B2,⋯,Bn是S的一个划分
P(Bi∣A)=P(ABi)P(A)=P(A∣Bi)P(Bi)∑j=1nP(A∣Bj)P(Bj), i=1,2,⋯ ,nP(B_i\mid A)=\frac{P(AB_i)}{P(A)}=\frac{P(A\mid B_i)P(B_i)}{\displaystyle\sum_{j=1}^{n}P(A\mid B_j)P(B_j)},\ i=1,2,\cdots ,nP(Bi∣A)=P(A)P(ABi)=j=1∑nP(A∣Bj)P(Bj)P(A∣Bi)P(Bi), i=1,2,⋯,n
6. 独立性和相关性
P(AB)=P(A)P(B) 则A,B独立Cov(A,B)>0 则A,B相关P(AB)=P(A)P(B)\ 则A,B独立\\ Cov(A,B)>0\ 则A,B相关P(AB)=P(A)P(B) 则A,B独立Cov(A,B)>0 则A,B相关
7. 离散型随机变量
| 随机变量 | 公式描述 | 期望 |
|---|---|---|
| 伯努利分布 | 只有两个取值P(0)=1−p, P(1)=p只有两个取值\\P(0)=1-p,\ P(1)=p只有两个取值P(0)=1−p, P(1)=p | ppp |
| 二项分布 | n次伯努利实验中事件A以概率p发生了k次P(X=k)=Cnkpk(1−p)n−k, k=0,1,⋯ ,nn次伯努利实验中事件A以概率p发生了k次\\P(X=k)=C_n^kp^k(1-p)^{n-k},\ k=0,1,\cdots,nn次伯努利实验中事件A以概率p发生了k次P(X=k)=Cnkpk(1−p)n−k, k=0,1,⋯,n | npnpnp |
| 几何分布 | 每次实验成功概率p,直到首次成功的实验次数为XP(X=k)=(1−p)k−1p, k=1,2,⋯每次实验成功概率p,直到首次成功的实验次数为X\\P(X=k)=(1-p)^{k-1}p,\ k=1,2,\cdots每次实验成功概率p,直到首次成功的实验次数为XP(X=k)=(1−p)k−1p, k=1,2,⋯ | 1/p1 / p1/p |
| 超几何分布 | N个样本中m个不及格,从中抽出n个,其中k个不及格概率P(X=k)=CmkCN−mn−kCNn, k=0,1,⋯ ,mN个样本中m个不及格,从中抽出n个,其中k个不及格概率\\P(X=k)=\displaystyle\frac{C_m^k C_{N-m}^{n-k}}{C_N^n},\ k=0,1,\cdots,mN个样本中m个不及格,从中抽出n个,其中k个不及格概率P(X=k)=CNnCmkCN−mn−k, k=0,1,⋯,m | nm/Nnm / Nnm/N |
| 泊松分布 | X表示独立事件发生次数,取值为0,1,2,⋯ ,λ为发生次数期望,P(X=k)=λke−λk!, k=0,1,2,⋯X表示独立事件发生次数,取值为0,1,2,\cdots,\lambda为发生次数期望,\\P(X=k)=\displaystyle\frac{\lambda^k e^{-\lambda}}{k!},\ k=0,1,2,\cdotsX表示独立事件发生次数,取值为0,1,2,⋯,λ为发生次数期望,P(X=k)=k!λke−λ, k=0,1,2,⋯ | λ\lambdaλ |
8. 连续随机变量
| 随机变量 | 公式描述 | 期望 |
|---|---|---|
| 均匀分布 | f(x)={1b−a,a<x<b0,其他f(x)=\left\{\begin{array}{ll}\displaystyle\frac{1}{b-a},&a<x<b\\0,&其他\end{array}\right.f(x)={b−a1,0,a<x<b其他 | (a+b)/2(a+b)/2(a+b)/2 |
| 指数分布 | f(x)={λe−λx,x≥00,其他f(x)=\left\{\begin{array}{ll}\displaystyle\lambda e^{-\lambda x},&x\geq0\\0,&其他\end{array}\right.f(x)={λe−λx,0,x≥0其他 | 1/λ1/\lambda1/λ |
| 正态分布 | f(x)=12πσe−(x−μ)22σ2, −∞<x<∞f(x)=\displaystyle\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}},\ -\infty<x<\inftyf(x)=2πσ1e−2σ2(x−μ)2, −∞<x<∞ | μ\muμ |
9. 数学期望
离散:E(X)=∑xx p(x)E(X)=\displaystyle\sum_x x\ p(x)E(X)=x∑x p(x)
连续:E(X)=∫−∞∞x f(x)dxE(X)=\displaystyle\int_{-\infty}^\infty x\ f(x)dxE(X)=∫−∞∞x f(x)dx
- 具有线性性质
- 独立随机变量X,Y有E(XY)=E(X)E(Y)E(XY)=E(X)E(Y)E(XY)=E(X)E(Y)
- 切比雪夫不等式:任意随机变量XXX具有数学期望μ\muμ和方差σ2\sigma^2σ2,则对于任意正数ϵ\epsilonϵ有P(∣X−μ∣≥ϵ)≤σ2ϵ2\displaystyle P(|X-\mu|\ge\epsilon)\le \frac{\sigma^2}{\epsilon^2}P(∣X−μ∣≥ϵ)≤ϵ2σ2
10. 条件期望
离散:E(X∣Y=y)=∑xx P(X=x∣Y=y)E(X\mid Y=y)=\displaystyle\sum_x x\ P(X=x\mid Y=y)E(X∣Y=y)=x∑x P(X=x∣Y=y)
连续:E(X∣Y=y)=∫−∞∞x fX∣Y(x∣y)dxE(X\mid Y=y)=\displaystyle\int_{-\infty}^\infty x\ f_{X\mid Y}(x\mid y)dxE(X∣Y=y)=∫−∞∞x fX∣Y(x∣y)dx
11. 方差
D(X)=E([X−E(X)]2)=E(X2)−[E(X)]2D(X)=E([X-E(X)]^2)=E(X^2)-[E(X)]^2D(X)=E([X−E(X)]2)=E(X2)−[E(X)]2
D(CX)=C2D(X), D(X+C)=D(X)D(CX)=C^2D(X),\ D(X+C)=D(X)D(CX)=C2D(X), D(X+C)=D(X)
D(X+Y)=D(X)+D(Y)+2Cov(X,Y)⟶X,Y独立D(X)+D(Y)D(X+Y)=D(X)+D(Y)+2Cov(X,Y)\stackrel{X,Y独立}{\longrightarrow }D(X)+D(Y)D(X+Y)=D(X)+D(Y)+2Cov(X,Y)⟶X,Y独立D(X)+D(Y)
12. 协方差
Cov(X,Y)=E([X−E(X)][Y−E(Y)])=E(XY)−E(X)E(Y)Cov(X,Y)=E([X-E(X)][Y-E(Y)])=E(XY)-E(X)E(Y)Cov(X,Y)=E([X−E(X)][Y−E(Y)])=E(XY)−E(X)E(Y)
Cov(aX,bY)=abCov(X,Y)Cov(aX,bY)=abCov(X,Y)Cov(aX,bY)=abCov(X,Y)
Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)Cov(X_1+X_2,Y)=Cov(X_1,Y)+Cov(X_2,Y)Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
13. 相关系数
ρXY=Cov(X,Y)D(X)D(Y)\displaystyle\rho_{XY}=\frac{Cov(X,Y)}{\sqrt{D(X)\sqrt{D(Y)}}}ρXY=D(X)D(Y)Cov(X,Y)
用来表征线性关系紧密程度,X,Y独立⟸̸⟹X,Y不相关X,Y独立\stackrel{\Longrightarrow}{\not\Longleftarrow}X,Y不相关X,Y独立⟸⟹X,Y不相关
14. 大数定理
- 弱大数定理
X1,X2,⋯X_1, X_2, \cdotsX1,X2,⋯为相互独立服从同分布的随机变量序列,其数学期望为μ\muμ,作前nnn个变量的算术平均X‾=1n∑k=1nXk\overline{X}=\displaystyle\frac{1}{n}\sum_{k=1}^{n}X_kX=n1k=1∑nXk,则X‾\overline{X}X依概率收敛到μ\muμ,即对于任意正数ϵ\epsilonϵ,有
limn→∞P(∣1n∑k=1nXk−μ∣<ϵ)=1\lim_{n \to\infty}P\left(\left|\frac{1}{n}\sum_{k=1}^{n}X_k-\mu\right|<\epsilon\right)=1n→∞limP(∣∣∣∣∣n1k=1∑nXk−μ∣∣∣∣∣<ϵ)=1 - 伯努利大数定理
fAf_AfA是nnn次独立重复事件AAA发生的次数,ppp是事件AAA在每次事件中发生的概率,则对于任意正数ϵ\epsilonϵ,有
limn→∞P(∣fAn−p∣<ϵ)=1\lim_{n \to\infty}P\left(\left|\frac{f_A}{n}-p\right|<\epsilon\right)=1n→∞limP(∣∣∣∣nfA−p∣∣∣∣<ϵ)=1
15. 中心极限定理
- 独立同分布中心极限定理
X1,X2,⋯ ,XnX_1, X_2, \cdots, X_nX1,X2,⋯,Xn为相互独立服从同分布的nnn个随机变量,其数学期望为μ\muμ,方差为σ2\sigma^2σ2,求这nnn个变量的和S=∑k=1nXkS=\displaystyle\sum_{k=1}^{n}X_kS=k=1∑nXk,则SSS的标准化变量近似服从正态分布,即
S−nμnσ∼近似N(0,1) \frac{S-n\mu}{\sqrt{n}\sigma}\stackrel{近似}{\sim}N(0,1) nσS−nμ∼近似N(0,1)
或者求这nnn个变量的算术平均X‾=1n∑k=1nXk\overline{X}=\displaystyle\frac{1}{n}\sum_{k=1}^{n}X_kX=n1k=1∑nXk,则
X‾−μσn∼近似N(0,1)或X‾∼近似N(μ,σ2n) \frac{\overline{X}-\mu}{\displaystyle\frac{\sigma}{\sqrt{n}}}\stackrel{近似}{\sim}N(0,1)\quad 或 \quad \overline{X}\stackrel{近似}{\sim}N(\mu,\frac{\sigma^2}{n}) nσX−μ∼近似N(0,1)或X∼近似N(μ,nσ2) - 独立不同分布中心极限定理(李雅普诺夫定理)
X1,X2,⋯ ,XnX_1, X_2, \cdots, X_nX1,X2,⋯,Xn为相互独立但是服从不同分布的nnn个随机变量,其数学期望依次为μ1,μ2,⋯ ,μn\mu_1,\mu_2, \cdots, \mu_nμ1,μ2,⋯,μn,方差依次为σ12,σ22,⋯ ,σn2\sigma_1^2, \sigma_2^2, \cdots, \sigma_n^2σ12,σ22,⋯,σn2,求这nnn个变量的和S=∑k=1nXkS=\displaystyle\sum_{k=1}^{n}X_kS=k=1∑nXk,则SSS的标准化变量仍然近似服从正态分布,即
S−∑k=1nμk∑k=1nσk2∼近似N(0,1) \frac{S-\displaystyle\sum_{k=1}^{n}\mu_k}{\displaystyle\sqrt{\sum_{k=1}^{n}\sigma_k^2}}\stackrel{近似}{\sim}N(0,1) k=1∑nσk2S−k=1∑nμk∼近似N(0,1) - 二项分布中心极限定理(棣莫弗-拉普拉斯定理)
η\etaη服从b(n,p)b(n,p)b(n,p)的二项分布,将其分解为独立同分布的0-1分布之和,则
η−npnp(1−p)∼近似N(0,1) \frac{\eta-np}{\sqrt{np(1-p)}}\stackrel{近似}{\sim}N(0,1) np(1−p)η−np∼近似N(0,1)
16. 抽样分布
-
χ2\chi^2χ2分布
X1,X2,⋯ ,XnX_1, X_2, \cdots, X_nX1,X2,⋯,Xn是来自总体N(0,1)N(0,1)N(0,1)的样本,则变量χ2=X12+X22+⋯+Xn2\chi^2=X_1^2+X_2^2+\cdots+X_n^2χ2=X12+X22+⋯+Xn2服从自由度为nnn的χ2\chi^2χ2分布。期望为nnn,方差为2n2n2n。
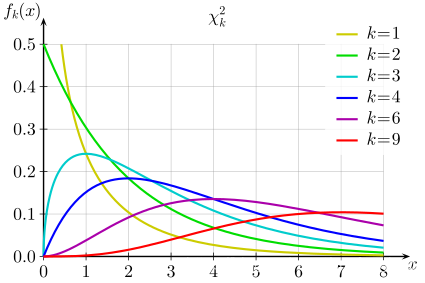
-
ttt分布
独立变量X∼N(0,1)X\sim N(0,1)X∼N(0,1),Y∼χ2(n)Y\sim \chi^2(n)Y∼χ2(n),则变量t=XYnt=\displaystyle\frac{X}{\sqrt{\frac{Y}{n}}}t=nYX服从自由度为nnn的ttt分布。
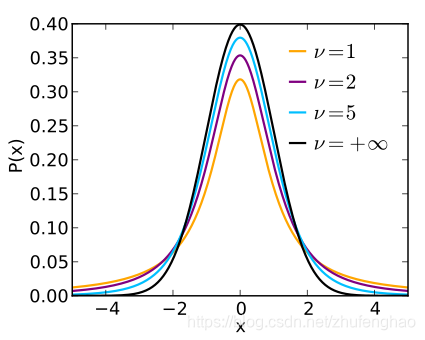
-
FFF分布
独立变量U∼χ2(n1)U\sim \chi^2(n_1)U∼χ2(n1),V∼χ2(n2)V\sim \chi^2(n_2)V∼χ2(n2),则变量F=Un1Vn2F=\frac{\frac{U}{n_1}}{\frac{V}{n_2}}F=n2Vn1U服从自由度为(n1,n2)(n_1,n_2)(n1,n2)的FFF分布。
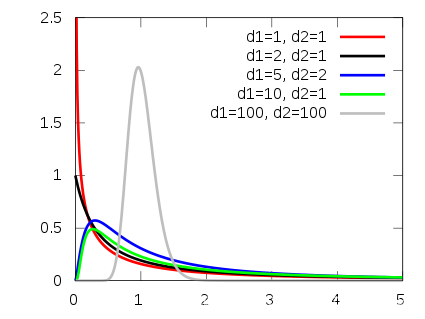
-
正态总体的样本均值、方差分布
已知正态总体的期望μ\muμ和方差σ2\sigma^2σ2,X1,X2,⋯ ,XnX_1, X_2, \cdots, X_nX1,X2,⋯,Xn是来自总体的样本,X‾\overline{X}X是样本均值,则
X‾∼N(μ,σ2n)\overline{X}\sim N(\mu,\frac{\sigma^2}{n})X∼N(μ,nσ2)
已知正态总体的方差σ2\sigma^2σ2,X1,X2,⋯ ,XnX_1, X_2, \cdots, X_nX1,X2,⋯,Xn是来自总体的样本,S2S^2S2是样本方差,则
(n−1)S2σ2∼χ2(n−1)\frac{(n-1)S^2}{\sigma^2}\sim \chi^2(n-1)σ2(n−1)S2∼χ2(n−1)
已知正态总体的期望μ\muμ但未知方差,X1,X2,⋯ ,XnX_1, X_2, \cdots, X_nX1,X2,⋯,Xn是来自总体的样本,X‾\overline{X}X是样本均值,S2S^2S2是样本方差,则
X‾−μSn∼t(n−1)\frac{\overline{X}-\mu}{\displaystyle\frac{S}{\sqrt{n}}}\sim t(n-1)nSX−μ∼t(n−1)
已知两个正态总体的方差分别为σ12\sigma_1^2σ12和σ22\sigma_2^2σ22,X1,X2,⋯ ,XnX_1, X_2, \cdots, X_nX1,X2,⋯,Xn是来自总体1的样本,Y1,Y2,⋯ ,YnY_1, Y_2, \cdots, Y_nY1,Y2,⋯,Yn是来自总体2的样本,S12,S22S_1^2,S_2^2S12,S22分别是样本方差,则
S12S22σ1σ2∼F(n1−1,n2−1)\frac{\displaystyle\frac{S_1^2}{S_2^2}}{\displaystyle\frac{\sigma_1}{\sigma_2}}\sim F(n_1-1,n_2-1)σ2σ1S22S12∼F(n1−1,n2−1)

















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









