






谷歌2019年在CVPR上发布的一篇针对移动平台的模型。有两个创新点
1、多目标神经结构搜索方法
目的:在移动设备上优化准确率和真实世界延迟。
实现:
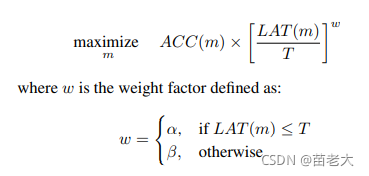 (2)
(2)
α和β是待定常数,那么如何确定它们的值呢?这里用到了经济学中的帕累托最优方法,以确保在不同精度-延迟权衡下,帕累托最优解具有相似的回报。例如:根据经验,延迟增加一倍通常会带来5%相对精度的提升。
给出两个模型:(1)M1,延迟为,精度为
。 (2)M2 延迟为
,精度为
.。这两个模型应该具有相似的回报,
解方程得到 因此 实验中使用
(在没有明确说明的情况下 )
2、可分解分层搜索空间
可分解分层搜索空间方案中,首先定义一个骨架结构,分为若干个 block。然后每个 block 单独搜索,每个 block 内包含的层是相同的,具体的层结构包含:
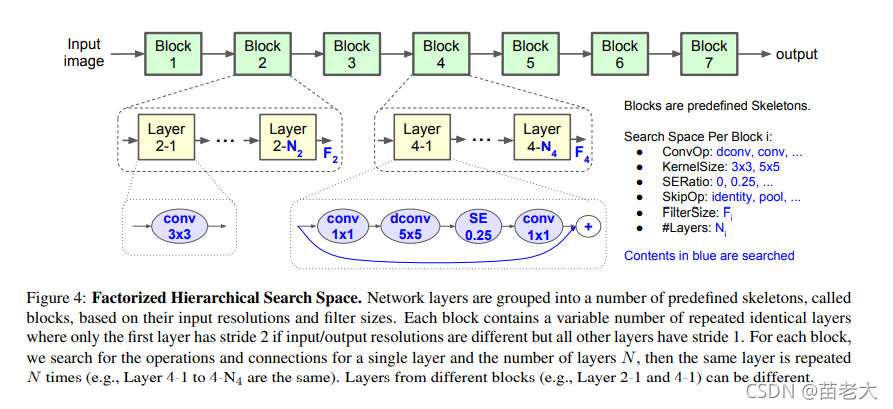
在以前的网络中例如使用深度可分离卷积,对于四元组(K, K, M, N) 将输入(H,W,M),输出(H,W,N)。这里(H,W)是输入分辨率,M,N分别是输入、输出滤波器的大小,其计算量是:
例如,在计算受限的情况下需要平衡 卷积核的尺寸K 和 滤波器大小N。可分解分层搜索空间是自动去搜索这个参数,而不用人工去考虑。
将网络划分为B个block, 每个block包含平均N个层的子搜索空间为S,例如: ,
,每个层展开后的搜索空间大小为
这个搜索量是巨大的。
受强化学习的启发,使用强化学习为多目标搜索问题来寻找帕累托最优解,具体如下
将搜索空间中的每个CNN模型映射到一个token list中,这些token由基于参数θ的强化学习agent产生的 一系列动作决定,最大化预期回报:
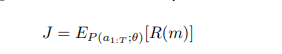 (5)
(5)
m是由动作产生的简单模型。R(m) 是由公式(2)确定的目标函数值。
搜索框架
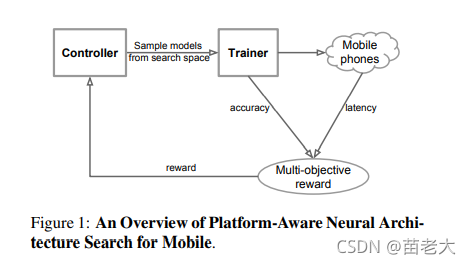
搜索框架由三部分组成:
Controller——循环神经网络(RNN)
Trainer——模型精度
Mobile Phones——测量移动端模型真实的推理延迟
遵循众所周知的sample-eval-update循环来训练Controller。在每个步骤中,Controller首先使用其当前参数对一批模型进行采样,通过从RNN中预测基于softmax logits的tokens序列。对于每个采样的模型m,我们将其训练在目标任务上以获得其精度ACC(m),并在实际手机上运行以获得其推理延迟LAT(m)。然后用公式2计算奖励值R(m)。在每一步结束时,利用近似策略优化,通过使方程5所定义的期望报酬最大化来更新控制器的参数。重复执行sample-evalupdate循环,直到达到最大的步骤数或参数收敛为止。

















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









