







tensorrt利用GPU进行加速,天然的GPU是适合并行计算,因此加大batchsize是优化tensorrt常见的方式之一
tensorrt默认是batchsize=1,接下来做几个实验进行观察
模型是直接下载的这个网站的onnx文件
拿到onnx文件后,我们需要转换成tensorrt的引擎文件
/opt/TensorRT-7.1.3.4/bin/trtexec --onnx=ctdet_coco_dlav0_512.onnx --saveEngine=ctdet_coco_dlav0_512_256.trt --best --batch=256 --workspace=4096运行成功直接会获得trt文件
![]()
接下来进行测试性能
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=256
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=128
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=64
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=32
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=16
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=8
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=4
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=2
/opt/TensorRT-7.1.3.4/bin/trtexec --loadEngine=ctdet_coco_dlav0_512_256.trt --batch=1本文只考察吞吐量和运行时间,将结果汇总如下
batchsize total compute time(s) throughput(qps)
1 2.94049 364.344
2 2.93884 725.753
4 2.77403 1365.88
8 1.65327 1619.66
16 0.922257 1818.5
32 0.479588 1848.01
64 0.238533 1859.18
128 0.12173 1842.8
256 0.0641229 1817.42
可视化一下计算时间(total compute time)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv("data.txt",sep="\t")
x =df['batchsize'].values
y1 =df['total compute time(s)'].values
y2 =df['throughput(qps)'].values
plt.plot(x, y1, 'ro--')
#plt.plot(x, y1, 'b--')
plt.xlabel('batchsize')
plt.ylabel('total compute time(s)')
for a, b in zip(x, y1):
plt.text(a+15,b-0.15,'(%d,%.4f)'%(a,b),ha='center', va='bottom',fontdict={'size': 10, 'color': 'g'})
plt.show()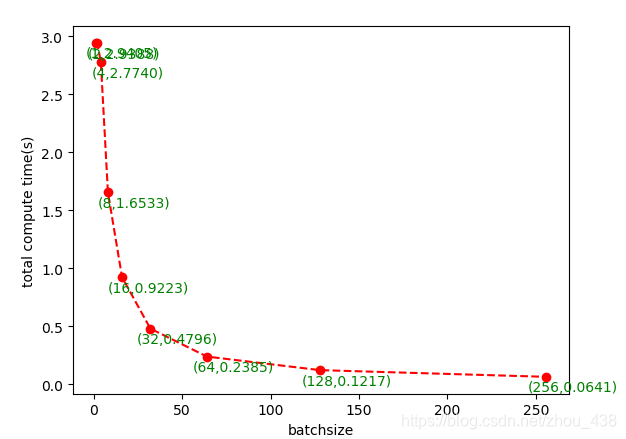
同理可视化一下吞吐量
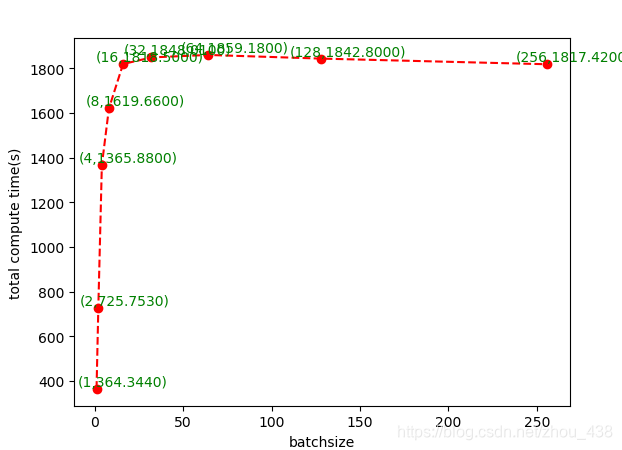
从上面两幅图我们可以看到提高batchsize的大小,对计算时间影响非常大;而提高batchsize的大小,对吞吐量的大小很容易达到饱和。
细心的同学可以发现,从onnx转trt文件的时候,是使用了--best
这个参数是
--best Enable all precisions to achieve the best performance (default = disabled)
属于混合精度,既不是单纯的fp32,也不是fp16,int8
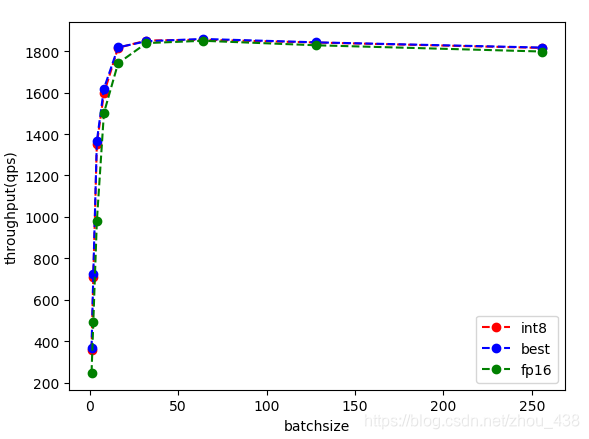
接下来对比一下不同量化对计算时间和吞吐量的影响
分别做了3个实验,best、fp16和int8
结果汇总成三个文件里面
best.txt
fp16.txt
int8.txt
可视化如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.tight_layout()
df_int8=pd.read_csv("int8.txt",sep="\t")
df_best=pd.read_csv("best.txt",sep="\t")
df_fp16=pd.read_csv("fp16.txt",sep="\t")
x =df_int8['batchsize'].values
y1_int8 =df_int8['total compute time(s)'].values
y1_best =df_best['total compute time(s)'].values
y1_fp16 =df_fp16['total compute time(s)'].values
plt.plot(x, y1_int8, 'ro--',label='int8')
plt.plot(x, y1_best, 'bo--',label='best')
plt.plot(x, y1_fp16, 'go--',label='fp16')
plt.xlabel('batchsize')
plt.ylabel('total compute time(s)')
plt.legend()
plt.show()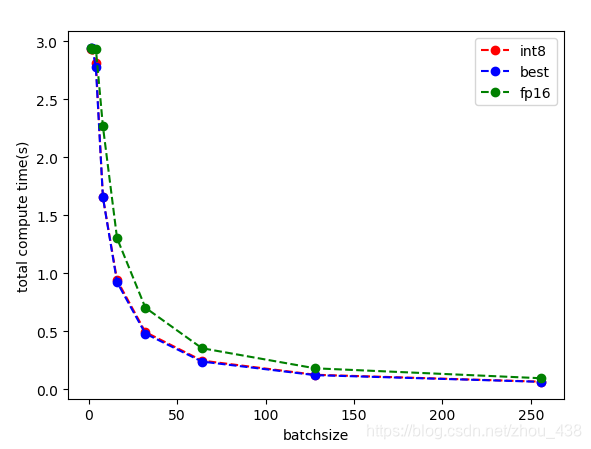

















 3598
3598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









