



总体来说还是tensorRT效率高很多,除开第一次占的时间长些,其余完胜!,测试结果如图所示:
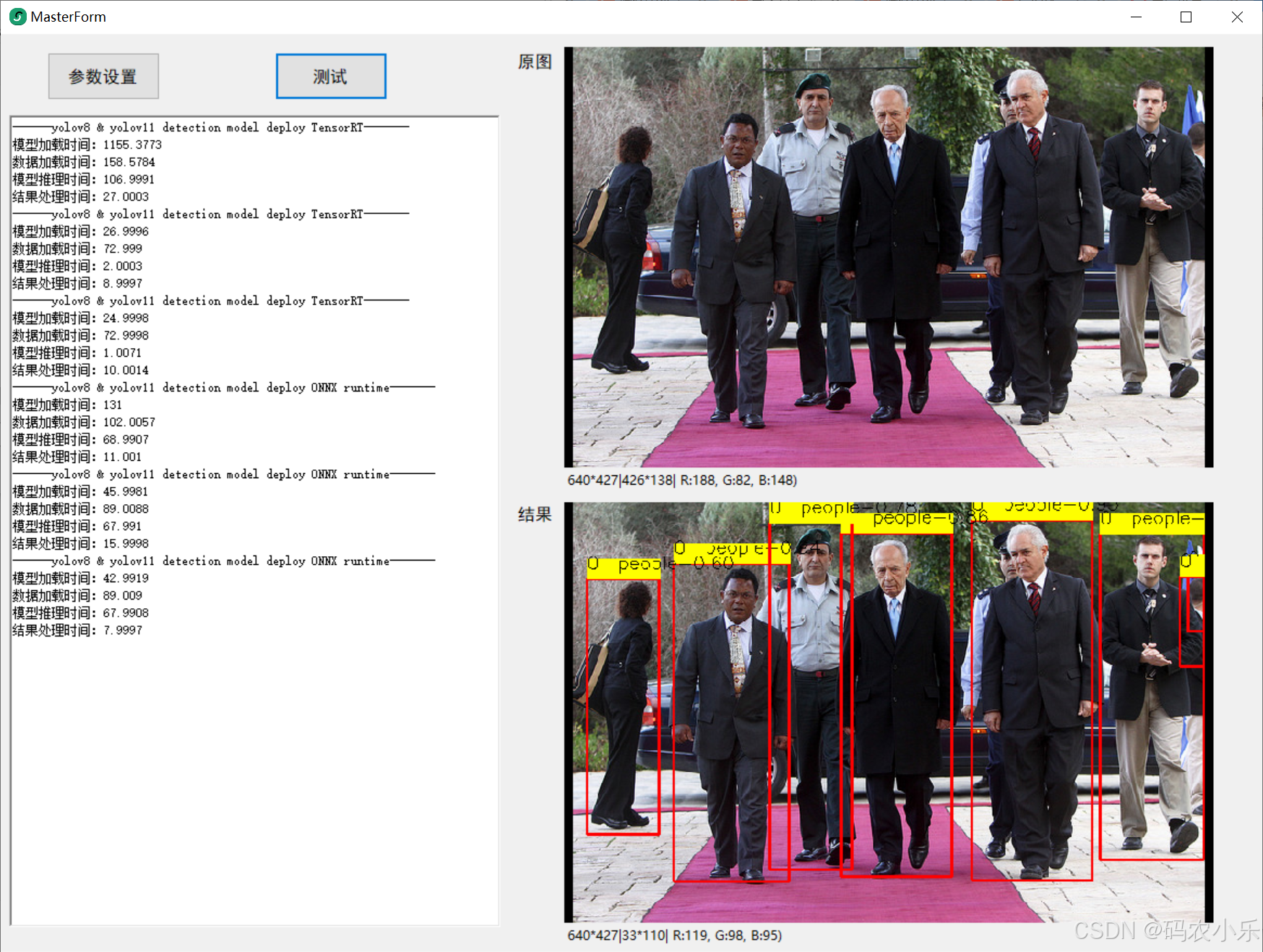
总体来说还是tensorRT效率高很多,除开第一次占的时间长些,其余完胜!,测试结果如图所示:
您可能感兴趣的与本文相关的镜像

TensorRT-v8.6
TensorRT 是NVIDIA 推出的用于深度学习推理加速的高性能推理引擎。它可以将深度学习模型优化并部署到NVIDIA GPU 上,实现低延迟、高吞吐量的推理过程。
 2万+
2606
1218
7844
2万+
2606
1218
7844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























