







 本文深入解析逻辑回归算法,解释sigmoid函数如何实现分类,并详细阐述逻辑回归的迭代过程及权重调整方法,最后通过源码展示实际操作。
本文深入解析逻辑回归算法,解释sigmoid函数如何实现分类,并详细阐述逻辑回归的迭代过程及权重调整方法,最后通过源码展示实际操作。
逻辑回归是一个分类算法,不是一个纯回归问题,光看书本疑惑还是会很多,比如:
(1)sigmoid函数怎么就能够分类?是怎么进行分类的?
(2)逻辑回归是什么时候迭代终止,什么时候才算分类成功呢?
在机器学习领域经常会用到激活函数这个概念,这函数的作用无非就是进行空间变换,sigmoid函数作为经典的激活函数,会将为(-无穷,+无穷)的数变换为(0,1)范围的数,而且他会有一个很特殊的功能,就是如X大于0,经过变换就会变成大于二分之一的数,反之如果小于零就会变换成小于二分之一的数,这样我们其实可以进行二分类的,正样本和负样本一目了然,经过变换以后由二分之一作为分水岭,就可以划分出大于或者小于的了。
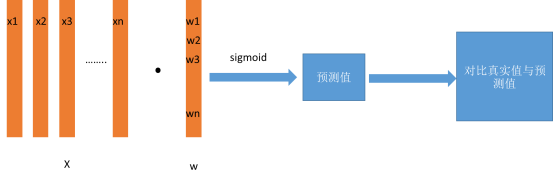
好像这样还欠缺点啥,众所周知数据集是有很多属性和样本量,也就是有很多列和行数,当然不能简单的挨着一个一个的算,算出来的单独的一个好像也没什么价值呢?我们可以试着进行加权,怎么说呢?我们知道我们每一行对应若干个x和一个y(因为我们简单说起,不考虑多目标预测),我们是不是可以具体的某一行的若干个x进行加权然后加起来,然后该值我们再用sigmoid进行空间变换,我们就可以得到行数个的大于1/2和小于1/2的了,我们就断定正负样本。
逻辑回归当然不是这么简单就了事的,这里面的权重我们是怎么进行取值的,权重首先初始化的是是在这个范围([-1/sqrt(N), 1/sqrt(N)])随机选取N个权重,然后通过学习率进行调整权重。为什么我们需要使用学习率进行调整呢?因为初始化的时候我们是随机的,也就是加权后的值可能就具有一定的随机性,这样分出的大于1/2和小于1/2的结果显然是不科学的,因此我们需要对其进行调整,那怎么进行调整呢?答案是梯度。我们其中最终需要对比的是通过sigmoid变换后的值和真实值进行pk,其实思路很easy,假如我们某一行预测值和真实值相等,那么这一行的权重我们是不需要进行变化的,如果预测值大于真实值,我们是不是应该将其减小一点这样乘起来就会更加接近真实值,反之若小于就应该增加权重,然后在预先设定好的迭代次数下进行尽可能的和真实值一样,这样我们分类的训练过程就结束了,说白了整个过程就是调整权重的过程,调整最好的那组权重,我们拿到后面进行预测,其实也就是说预测用的只是最优的那组权重而已,这样我们就可以进行预测啦。最终,我们找到了最好的那组权重,整个过程其实就完成了。
这里说了这个么若觉得还是不够形象,我们可以看看图:
附上人家写的源码(我是看源码进行理解的):
import numpy as np
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
# Import helper functions
from utils import make_diagonal, normalize, train_test_split, accuracy_score
from utils import Plot
def sigmoid(x):
return 1 / (1 + np.exp(-x))
class LogisticRegression():
"""
Parameters:
-----------
n_iterations: int
梯度下降的轮数
learning_rate: float
梯度下降学习率
"""
def __init__(self, learning_rate=.1, n_iterations=4000):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
def initialize_weights(self, n_features):
# 初始化参数
# 参数范围[-1/sqrt(N), 1/sqrt(N)]
limit = np.sqrt(1 / n_features)
w = np.random.uniform(-limit, limit, (n_features, 1))
b = 0
self.w = np.insert(w, 0, b, axis=0)
def fit(self, X, y):
m_samples, n_features = X.shape
self.initialize_weights(n_features)
# 为X增加一列特征x1,x1 = 0
X = np.insert(X, 0, 1, axis=1)
y = np.reshape(y, (m_samples, 1))
# 梯度训练n_iterations轮
for i in range(self.n_iterations):
h_x = X.dot(self.w)
y_pred = sigmoid(h_x)
w_grad = X.T.dot(y_pred - y)
self.w = self.w - self.learning_rate * w_grad
def predict(self, X):
X = np.insert(X, 0, 1, axis=1)
h_x = X.dot(self.w)
y_pred = np.round(sigmoid(h_x))
return y_pred.astype(int)
def main():
# Load dataset
data = datasets.load_iris()
X = normalize(data.data[data.target != 0])
y = data.target[data.target != 0]
y[y == 1] = 0
y[y == 2] = 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, seed=1)
clf = LogisticRegression()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
y_pred = np.reshape(y_pred, y_test.shape)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# Reduce dimension to two using PCA and plot the results
Plot().plot_in_2d(X_test, y_pred, title="Logistic Regression", accuracy=accuracy)
if __name__ == "__main__":
main()

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









