



前言
本文先科普 AI 编程需要掌握的基础知识,对具体的技术细节不作太多展开,点到为止,最后演示一个真实的使用案例,供大家参考。
一、AI 编程产品
1.1 初代:增强补全体验
- Github Copilot、Codeium
特征:主要解决了代码补全、减少样板代码编写、降低编程学习曲线以及减少文档查询等问题,可理解为增强版代码补全工具。
1.2 第二代:重塑编程体验
-
命令行工具:Aider
-
VS Code 插件:Cline、Roo Code
-
IDE:Cursor、Windsurf(Codeium 家产品)、Trae(字节)
-
SaaS 服务:Vercel v0、Bolt
特征:项目级理解、自然语言交互、多文件编辑、代码解释与重构以及主动规划建议等,可理解为内置了一个或多个 Coding Agent。
1.3 未来展望
- Devin、OpenHands(原 OpenDevin)
特征:具备完全自主性、多工具协作能力、终端交互能力以及自主调试能力,可当成一名能接收需求并交付最终结果的 AI 程序员(Agent)。现阶段这些工具受限于准确率不高、高昂的成本等因素,无法广泛应用于实际生产环境。
二、AI 编程基础(必知必会)
2.1 大模型使用基础
大模型请求演示
以 OpenAI API 为例:
请求
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
o1 以及更新的模型使用 developer role 替换了原先的 system role
响应
{
"id": "chatcmpl-B9MBs8CjcvOU2jLn4n570S5qMJKcT",
"object": "chat.completion",
"created": 1741569952,
"model": "gpt-4o-2024-08-06",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 19,
"completion_tokens": 10,
"total_tokens": 29,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default"
}
流式响应(SSE,Server-sent events)
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}
....
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
进阶:多模态大模型请求
所谓多模态即大模型支持多种输入类型,如文本、图片、音频等,以 gpt-4o 支持图片为例:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
}
]
}
],
"max_tokens": 300
}'
该请求将图片和文本作为输入,模型将返回文本。
文生图使用的是 OpenAI 其他模型:Dall-e,此处不演示。
Tips:Cursor 中识别图片的能力就是通过多模态模型能力实现的。
案例:对话机器人的实现
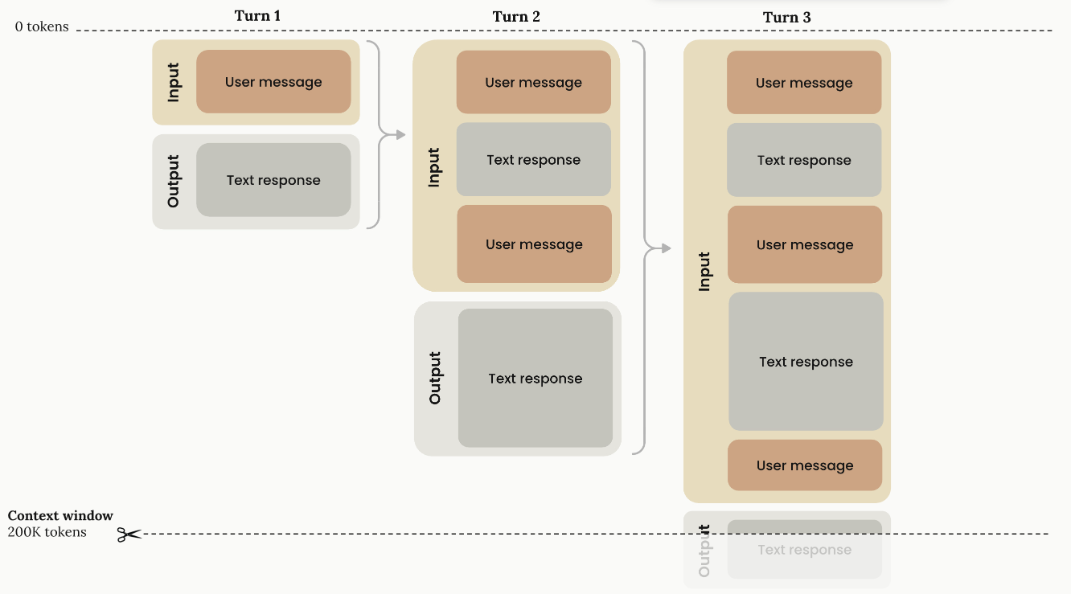
1)messages 数组维护的是完整的是上下文
2)每一轮大模型请求都得带上之前完整的上下文,因此请求轮次越多,Token 消耗次数越快
Tips:我们在 Cursor 中的对话轮次太多,大模型可能会忘记早期的信息,就是因为上下文限制只能对早期的信息进行丢弃。可以用大模型对前文总结的手段减缓信息丢失的情况,但无法根本解决。因此,保持一个任务的上下文在合理的范围内是有必要的。
2.2 模型限制
上下文限制与成本
- 不同模型有上下文的限制,限制主要体现为对 Token 的限制
- Token 是大模型理解和生成文本的最小单位,类似于人类语言中的“字词”,但划分逻辑由模型的分词算法决定。例如:
a) . 英文句子 “Hello, world!” 可能被拆分为 [“Hello”, “,”, “world”, “!”] 四个 Token;
b). 中文句子 “人工智能真神奇” 可能拆分为 [“人”, “工”, “智”, “能”, “真”, “神奇”] 六个 Token - Token 和字符数不是 1:1 的关系,但不同模型能算出一个参考比例,比如 750 个中文字符消耗 1000 个 Token。
- OpenAI 的模型如果有计算 Token 的需求可以参考 https://github.com/openai/tiktoken
- 如前面对话机器人的案例所说,对话轮次越多,Token 消耗越快,同时成本越高。(现在有些模型支持上下文缓存 Context Cache)

Tips:可以看到,不同模型对上下文的限制不一样,比如 gpt-4o 只支持 128k、而 gemini 2.0 flash 可以支持高达 1m。gemini 2.0 塞进一本哈利波特单部小说(数十万字)是没问题的,而 gpt-4o 不一定能支持。因此不同的场景需要选择不同的模型。
知识实时性不足
模型知识受限于训练时间点,比如 Claude 3.5 Sonnet 的数据训练时间截止至 2024 年 4 月。
参考:
https://support.anthropic.com/en/articles/8114494-how-up-to-date-is-claude-s-training-data
所以我们一般通过rag技术或者实时联网等技术来获取实时的信息。
Tips:知识受限于训练时间,以 Claude 3.5 Sonnet 为例,Next.js 15 是在 2024 年 10 月发布的,你用 Cursor + Claude 3.5 Sonnet 只能写出 Next.js 14 的代码。Cursor 也许用了工程手段规避部分问题,但总的来说这个问题是存在的。因此如果你关注 Cursor 写的代码,可以把最新的文档丢给他,解决知识实时性的问题。
幻觉
模型生成的内容是通俗理解是通过 Token 序列预测下一个 Token,这个环节是通过概率预测的,因此有时候会输出看似合理但实际错误(例如虚构事实和数据),且无法自我验证准确性,这时候需要依赖外部知识库或人肉判断。
例如:输入“窗前明月光”,大模型预测下一个词大概率是“疑”,直至输出“疑是地上霜”。
我们可以通过rag技术,构建自己的知识库,通过召回手段保证知识的正确性。
Tips:也就是说大模型生成是有随机性的,有时候会输出错误的结果,不要盲目相信大模型给的结果。
2.3 大模型与外部工具集成
请求
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "What is the weather like in Boston today?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
],
"tool_choice": "auto"
}'
相应
{
"id": "chatcmpl-abc123",
"object": "chat.completion",
"created": 1699896916,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\n\"location\": \"Boston, MA\"\n}"
}
}
]
},
"logprobs": null,
"finish_reason": "tool_calls"
}
],
"usage": {
"prompt_tokens": 82,
"completion_tokens": 17,
"total_tokens": 99,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
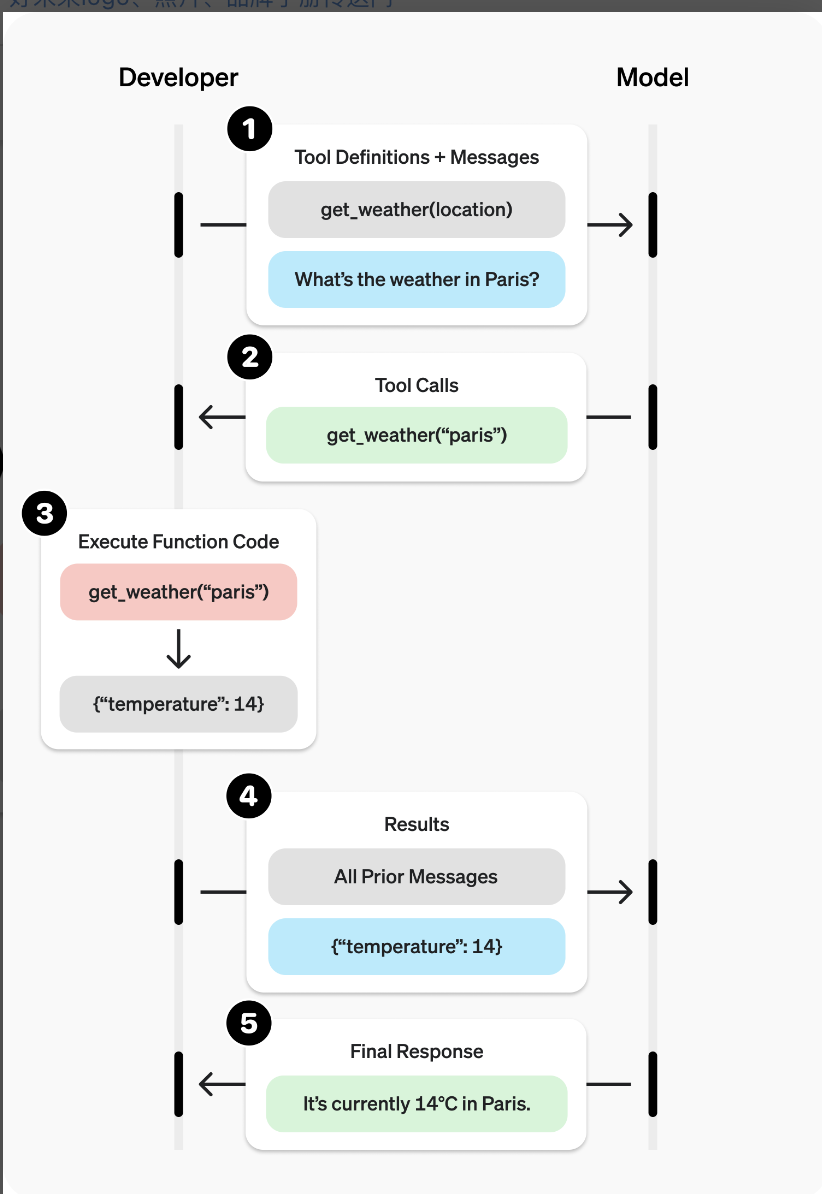
- get_current_weather 这个函数需要本地实现
- 此处请求中只在参数描述了一个函数,实际上可以描述多个,由大模型根据你的意图选择最合适的那个函数,并组装相关函数名及参数,本地只需要完成执行动作即可。
以上,就建立了大模型与外部工具的连接。
2.4 模型上下文协议MCP
MCP 全称 Model Context Protocol。
Server 包含:
- Resources
- Prompts
- Tools
- Sampling(允许 server 执行大模型请求,值得期待)
官方出品教你用大模型写 MCP Server(即,完全可以用 Cursor、Cline 等工具实现):
https://modelcontextprotocol.io/tutorials/building-mcp-with-llms
MCP server 当前主要都是本地部署,官方的 roadmap 可以看到 25 年上半年官方在关注 Remote MCP 的支持,重点需要解决鉴权、服务发现、无状态等方面的问题,值得关注。
2.5 Coding Agent
Agent 的核心特征是自主性与环境交互能力。
自主计算实体:能够感知环境(如用户输入、传感器数据等),通过推理规划目标,并调用工具(如API、数据库)执行任务。
动态决策系统:不同于预设流程的 Workflow,Agent 依赖大模型的动态推理能力,自主调整执行路径。
所谓 Coding Agent 即专门用于编程的 Agent,前面提到的第二代 AI 编程产品如 Cursor、Cline 等都内置了 Coding Agent。
三、提示词工程
使用提示词时,通常会通过 API 或直接与大语言模型进行交互。可以通过配置一些参数以获得不同的提示结果。调整这些设置对于提高响应的可靠性非常重要,往往需要进行一些实验才能找出适合您的用例的正确设置。以下是使用不同LLM提供程序时会遇到的常见设置:
Model:指定相应的模型ID,如gpt-4o或o3等。
Temperature:简单来说,temperature 的参数值越小,模型就会返回越确定的一个结果。如果调高该参数值,大语言模型可能会返回更随机的结果,也就是说这可能会带来更多样化或更具创造性的产出。(调小temperature)实质上,你是在增加其他可能的 token 的权重。在实际应用方面,对于质量保障(QA)等任务,我们可以设置更低的 temperature 值,以促使模型基于事实返回更真实和简洁的结果。 对于诗歌生成或其他创造性任务,适度地调高 temperature 参数值可能会更好。
Top_p:同样,使用 top_p(与 temperature 一起称为核采样(nucleus sampling)的技术),可以用来控制模型返回结果的确定性。如果你需要准确和事实的答案,就把参数值调低。如果你在寻找更多样化的响应,可以将其值调高点。
Max Length:您可以通过调整 max length 来控制大模型生成的 token 数。指定 Max Length 有助于防止大模型生成冗长或不相关的响应并控制成本。
Frequency Penalty:-2.0到2.0之间到数字,根据新标记在文本中的现有的频率惩罚它们,从而降低模型逐字重复同一行的可能性。
Presence Penalty:presence penalty 也是对重复的 token 施加惩罚,但与 frequency penalty 不同的是,惩罚对于所有重复 token 都是相同的。出现两次的 token 和出现 10 次的 token 会受到相同的惩罚。 此设置可防止模型在响应中过于频繁地生成重复的词。 如果您希望模型生成多样化或创造性的文本,您可以设置更高的 presence penalty,如果您希望模型生成更专注的内容,您可以设置更低的 presence penalty。
与 temperature 和 top_p 一样,一般建议是改变 frequency penalty 和 presence penalty 其中一个参数就行,不要同时调整两个。
具体可参考:https://www.promptingguide.ai/zh

















 2409
2409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









