




 前馈神经网络(FNN)是一种无循环连接的神经网络,信息单向传递。最简单的形式是单层感知器,其学习算法包括delta规则。单层感知器仅能学习线性可分模式,而多层感知器能够解决更复杂问题,如异或。反向传播是多层网络常用的学习技术,通过调整权重减少误差。尽管存在梯度消失问题,多层感知器展示了强大的泛化能力,能够逼近任何连续函数。
前馈神经网络(FNN)是一种无循环连接的神经网络,信息单向传递。最简单的形式是单层感知器,其学习算法包括delta规则。单层感知器仅能学习线性可分模式,而多层感知器能够解决更复杂问题,如异或。反向传播是多层网络常用的学习技术,通过调整权重减少误差。尽管存在梯度消失问题,多层感知器展示了强大的泛化能力,能够逼近任何连续函数。
前馈神经网络(FNN)是一种人工神经网络,其中节点之间的连接不形成循环。因此,它不同于它的后代:递归神经网络。
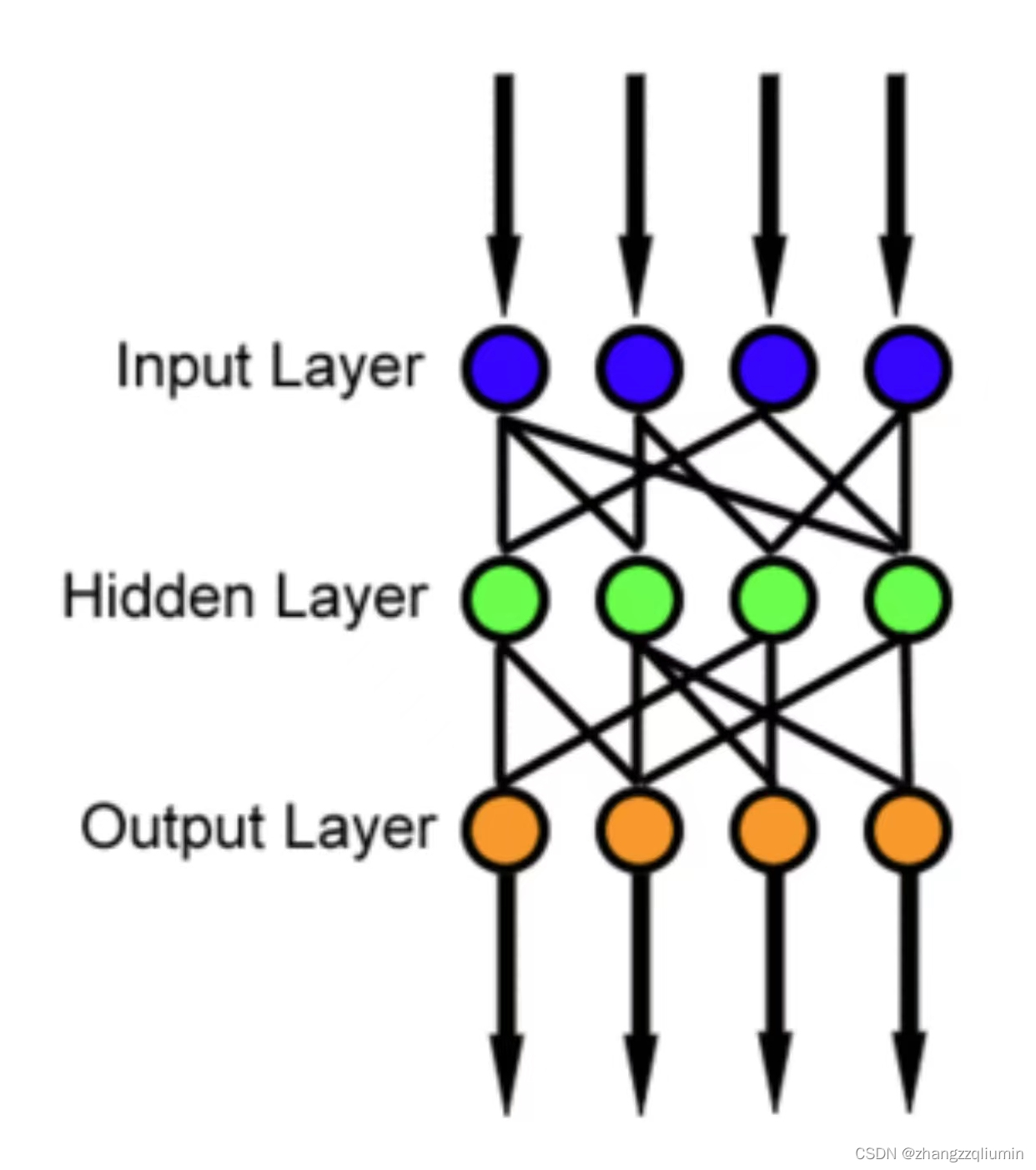

在前馈网络中,信息总是向一个方向移动;它从不倒退。
前馈神经网络是设计的第一种也是最简单的人工神经网络。在该网络中,信息仅在一个方向上从输入节点向前移动,通过隐藏节点(如果有)并到达输出节点。网络中没有循环或环路。
单层感知器
最简单的神经网络是单层感知器网络,由单层输出节点组成;输入通过一系列权重直接馈给输出。在每个节点中计算权重和输入的乘积之和,如果该值高于某个阈值(通常为0),则神经元触发并取激活值(通常为1);否则,它将取停用的值(通常为-1)。具有这种激活功能的神经元也称为人工神经元或线性阈值单元。在文献中,术语感知机通常指仅由这些单元之一组成的网络。沃伦·麦卡洛赫和沃尔特·皮茨在20世纪40年代描述了类似的神经元。
可以使用激活和停用状态的任何值来创建感知器,只要阈值介于两者之间。
感知器可以通过一种简单的学习算法来训练,该算法通常称为delta规则。它计算计算出的输出和样本输出数据之间的误差,并使用该误差对权重进行调整,从而实现一种梯度下降形式。
单层感知器只能学习线性可分离模式;1969年,Marvin Minsky和Seymour Papert在一篇名为《感知器》的著名专著中指出,单层感知器网络不可能学习异或函数(尽管如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









