




图像匹配方面文献阅读
- 2021
- 2023
- 2024
-
- OmniGlue: Generalizable Feature Matching with Foundation Model Guidance(谷歌的,基于superglue)
- A unified feature-motion consistency framework for robust image matching
- Semi-Supervised Coupled Thin-Plate Spline Model for Rotation Correction and Beyond
- Leveraging Semantic Cues from Foundation Vision Models for Enhanced Local Feature Correspondence
- Leveraging Semantic Cues from Foundation Vision Models for Enhanced Local Feature Correspondence
- 2025
2021
SuperGlue: Learning Feature Matching with Graph Neural Networks
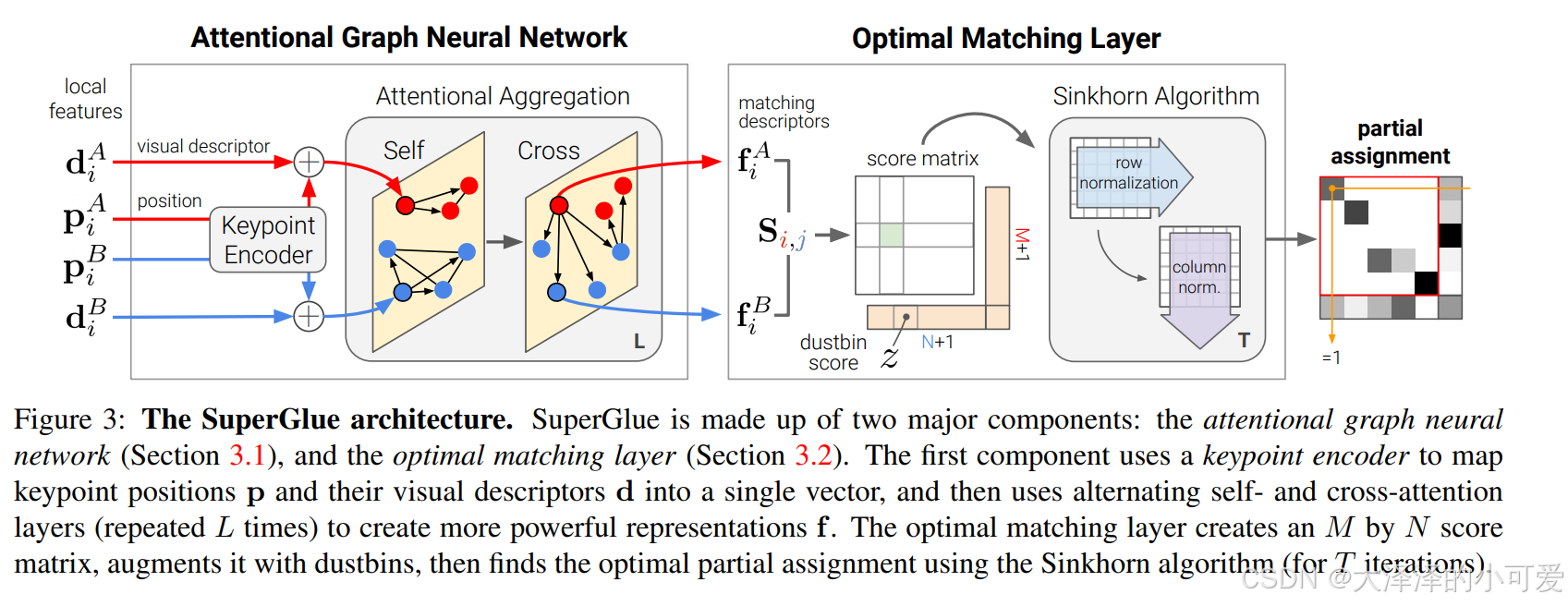
通过输入superpoint检测出的特征点和特征向量,构建一个图,其中节点为特征点,有两种边:图内边,图间边。这种机制通过边来“指导”注意力计算,避免了对不相关特征点的干扰。
(在计算注意力时,只考虑图像 A 中的特征点与图像 B 中通过交叉边连接的特征点之间的关系,从而更新匹配的特征点表示。)
== 输入的特征向量经过自注意力和交叉注意力,不断更新特征向量,最终得到强化版的特征向量fa和fb,然后构建相似矩阵,利用sinkhorn 算法来得到最终的匹配结果。 ==
2023
LightGlue: Local Feature Matching at Light Speed
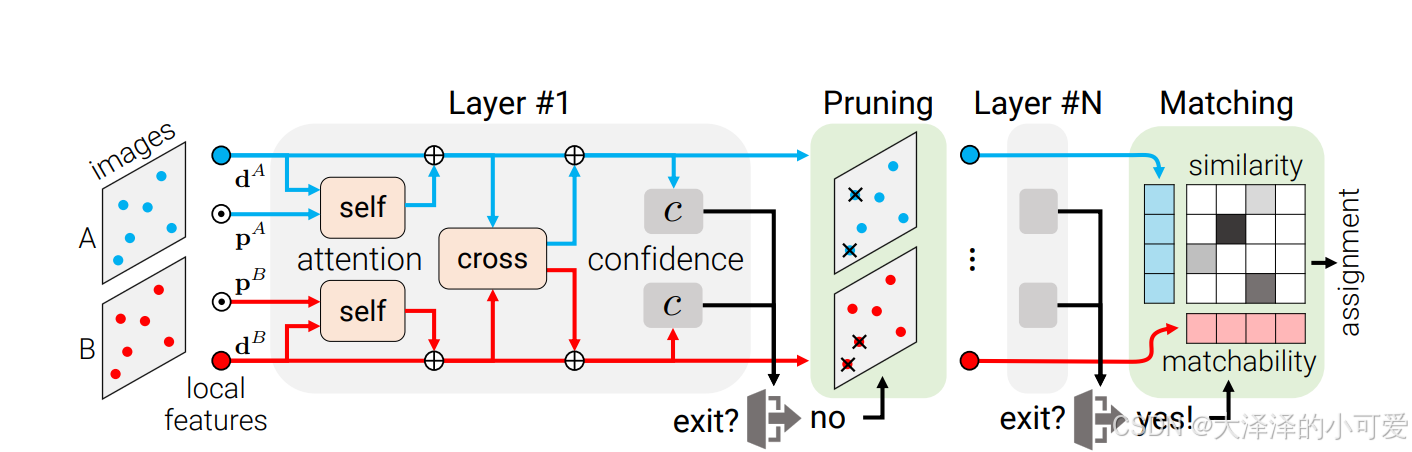
同一个课题组的文章,目的是减小模型量,提升运算速度,以及训练效率。算法在更新特征点的特征向量的时候,进行判断,置信度足够高的时候,停止更新,直接得最终的强化版特征向量,然后形成相似矩阵。
SFD2: Semantic-guided Feature Detection and Description
摘要:视觉定位是许多应用中的基础任务,包括自动驾驶和机器人技术。
之前的方法主要集中在提取大量通常冗余的局部可靠特征,这导致在大规模环境中,尤其是在具有挑战性的条件下,效率和精度受到限制。与此不同,我们提出通过将高层语义隐式嵌入到检测和描述过程中来提取全局可靠的特征。具体来说,我们的语义感知检测器能够从可靠区域(例如建筑物、交通车道)检测关键点,并隐式地抑制不可靠区域(例如天空、汽车),而不是依赖显式的语义标签。这通过减少对外观变化敏感的特征数量,避免了在测试时需要额外的分割网络,从而提高了关键点匹配的精度。此外,我们的描述符通过加入语义信息,具有更强的判别能力,在测试时提供了更多的内点(inliers)。
特别地,在长期大规模的视觉定位数据集 Aachen DayNight 和 RobotCar-Seasons 上的实验表明,我们的模型优于先前的局部特征,并且与先进的匹配器相比,尽管精度相当,但在使用 2k 和 4k 关键点时,速度分别提高了约 2 倍和 3 倍。
代码可在 https://github.com/feixue94/sfd2 获取。
related work
高级匹配器:由于最近邻匹配(NN matching)无法结合关键点的空间关系进行匹配,因此提出了高级匹配器,通过利用一组关键点的空间上下文 [8, 55, 65] 或图像块 [9, 18, 33, 52, 67, 84] 来提高准确性。SuperGlue (SPG) [55] 利用带有注意力机制的图神经网络,在关键点之间传播信息,获得了令人印象深刻的准确性,但其时间复杂度与关键点数量的平方成正比。通过使用种子匹配 [8] 和聚类匹配 [65] 可以部分缓解这个问题,但速度仍然比最近邻匹配慢上千倍。稠密匹配器 [9, 33, 52, 67] 通过相关体积计算像素级的对应关系,因此它们也面临稀疏匹配器 [8, 55, 65] 相同的高时间和内存成本。 此外,高级匹配器在图像对上操作,而不是关键点,因此考虑到图像对的数量,使用高级匹配器的系统在实际应用中可能会更慢,正如 [8] 中所分析的那样。在本文中,我们将高层次的语义信息隐式嵌入到局部特征中,以增强特征检测和描述,从而使我们的模型在简单的NN匹配下,能够与高级匹配器获得相当的结果。我们的工作在时间和准确性之间提供了一个良好的折衷,尤其适用于计算资源有限的设备。
3.2. 语义引导的特征描述
我们通过直接将语义信息嵌入到特征描述过程中,增强描述符的区分能力。与以往仅依赖局部图像块信息来区分关键点的描述符不同,我们的描述符在同一类别的特征之间强制相似性,同时保留类内匹配的差异性。
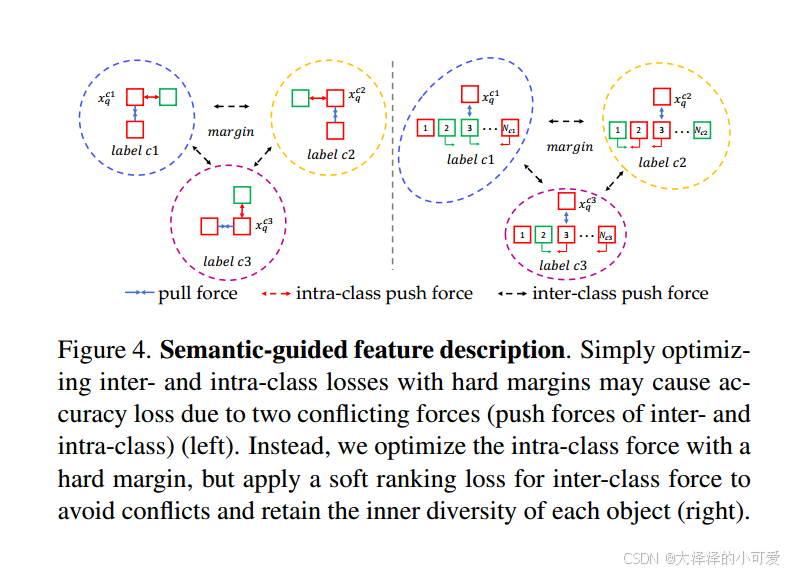
然而,在训练过程中,这两个目标存在冲突。类别级别的区分能力要求将同一类别的描述符空间压缩,而类内区分能力则要求扩展该空间,以保留类别内关键点的多样性。
一种可能的解决方案是为所有类别设置硬边界(如图4左所示)。然而,这种方法会导致同一类别对象内部多样性的丧失。例如,虽然所有的交通信号灯相似,但不同的建筑物在外观上差异巨大,而这种类内多样性对于准确匹配至关重要。
为了解决这一冲突,我们设计了基于不同度量的两种损失,分别用于类间和类内匹配(如图4右所示)。这些损失使得模型能够平衡类别级别和类内区分的目标,从而增强描述符区分类别的能力,同时保留同一类别内关键点的多样性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+



 到【灌水乐园】发言
到【灌水乐园】发言










