



1、准备
1)默认已经安装了Anaconda + pytorch + pycharm
2)从git上克隆yolov5的源码:https://github.com/ultralytics/yolov5 并下载原始的比重文件
2、运行原始示例
在pycharm上打开,运行detect.py ,运行结果存入runs/detect/exp文件夹,需要检测的图像存在了data/images文件夹内,放入从网上找的一张图,重新运行detect.py,运行结果存入runs/detect/exp1文件夹。至此官方给的例子完全跑通,但是内部的很多东西还是需要学习。
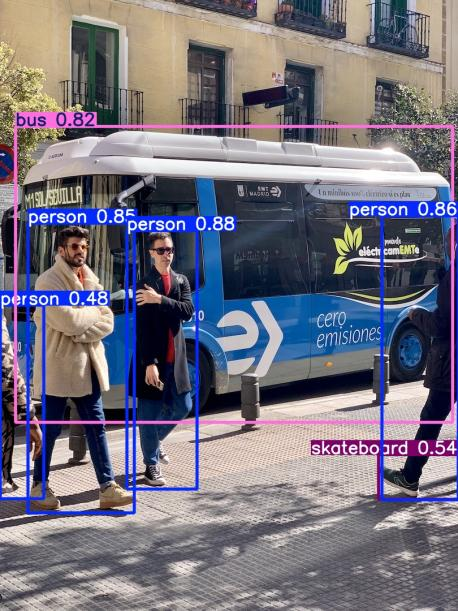


3、示例数据集
yolo示例的数据集从哪来,又能识别出哪些东西呢?
查看这个目录文件学习,可以了解到yolo用的是coco数据集,一共能识别出80种常见物体。
YOLOv5源码学习(1)——项目目录结构解析_yolov5项目-优快云博客
80类分别为
[‘person’, ‘bicycle’, ‘car’, ‘motorcycle’, ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’, ‘fire hydrant’, ‘stop sign’, ‘parking meter’, ‘bench’, ‘bird’, ‘cat’, ‘dog’, ‘horse’, ‘sheep’, ‘cow’, ‘elephant’, ‘bear’, ‘zebra’, ‘giraffe’, ‘backpack’, ‘umbrella’, ‘handbag’, ‘tie’, ‘suitcase’, ‘frisbee’, ‘skis’, ‘snowboard’, ‘sports ball’, ‘kite’, ‘baseball bat’, ‘baseball glove’, ‘skateboard’, ‘surfboard’, ‘tennis racket’, ‘bottle’, ‘wine glass’, ‘cup’, ‘fork’, ‘knife’, ‘spoon’, ‘bowl’, ‘banana’, ‘apple’, ‘sandwich’, ‘orange’, ‘broccoli’, ‘carrot’, ‘hot dog’, ‘pizza’, ‘donut’, ‘cake’, ‘chair’, ‘couch’, ‘potted plant’, ‘bed’, ‘dining table’, ‘toilet’, ‘tv’, ‘laptop’, ‘mouse’, ‘remote’, ‘keyboard’, ‘cell phone’, ‘microwave’, ‘oven’, ‘toaster’, ‘sink’, ‘refrigerator’, ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’, ‘hair drier’, ‘toothbrush’]
怪不得能识别出我随便找的图片中的小汽车呢。
4、标注自己的数据集
着手进行自己标注训练
- 从网上下载了一个螺丝螺母的数据集.
- 在Yolo中建立文件夹,在根目录新建数据集文件夹screw :F:\Yolo\yolov5\screw;下面新建images和labels文件夹,目录结构如下:
dataset/
├── images/
│ ├── train/ # 训练图片
│ └── val/ # 验证图片
└── labels/
├── train/ # 训练标签
└── val/ # 验证标签
在train和val里分别放入图片,图片比例为8:2,图像多的话可能得是9:1

在yolov5目录行输入cmd,启动命令行,或者win+R启动命令行后cd进入yolov5文件夹,输入activate yolov5 进入yolov5虚拟环境,这个环境是以前在conda里建好的。然后在这输入pip install labelimg安装labelimg标注软件,这个没有截图,我一开始用的conda install labelimg 失败了,又输入的pip安装成功了。
成功后直接输入labelimg就可以启动标注软件。
参考(傻瓜式)从零开始Yolov5环境配置+训练_怎么把yolov5系统接入电脑环境-优快云博客
![]()
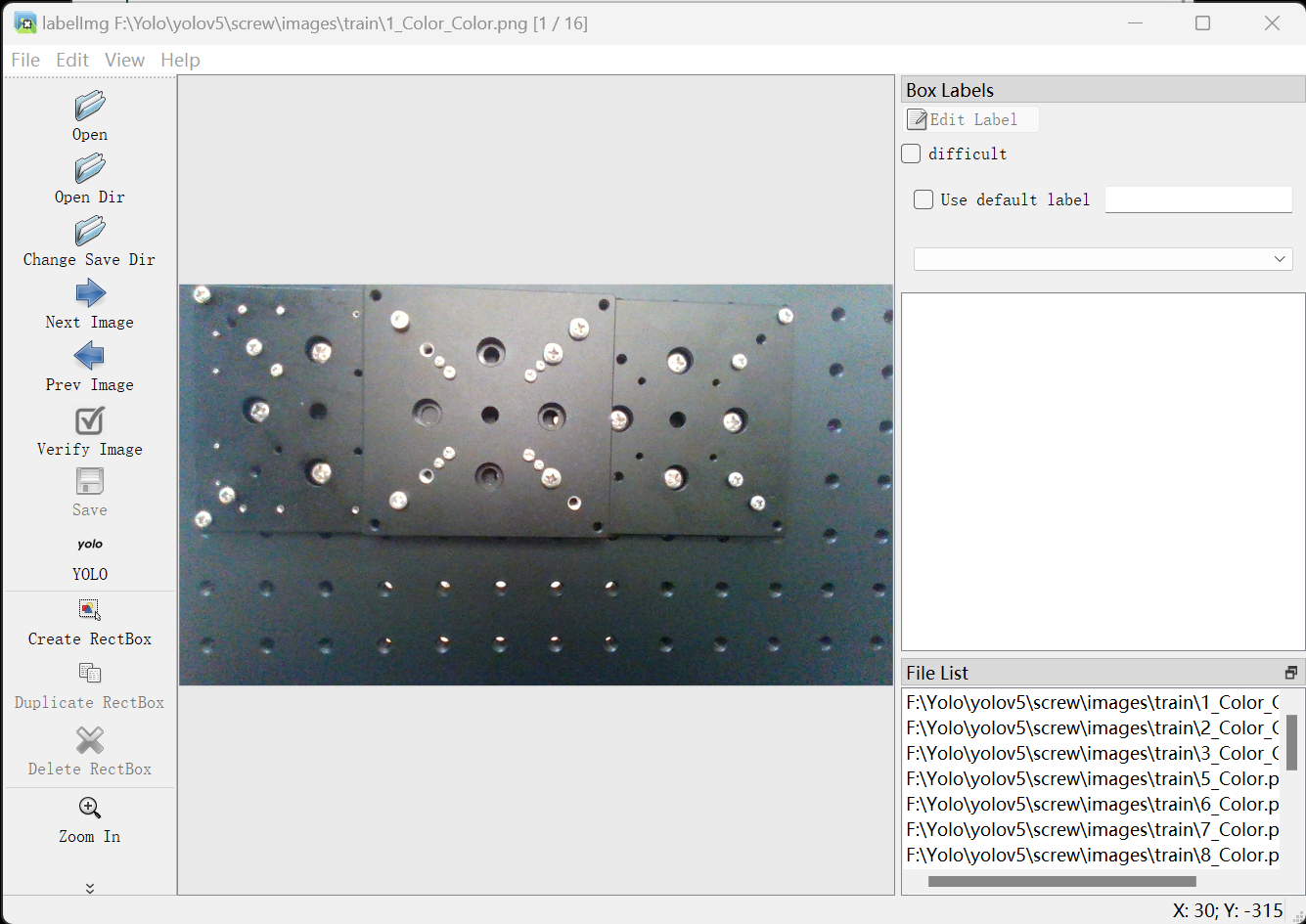
-
标注都成功后,目录结构如下图。
-
.cache为缓存文件,这个是运行train.py生成的。网上说是为了下一次更快速的运行。
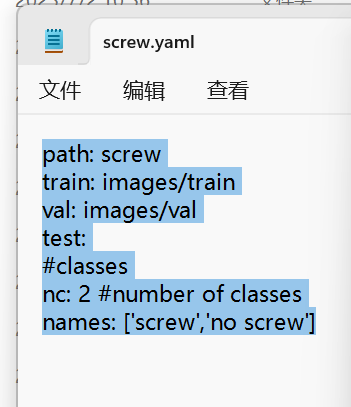
标注完成后,写数据集文件,在yolov5/data文件夹下新建screw.yaml文件,第一行是数据集的路径,后面是相对于这个路径的训练路径。
注意:我一开始输入的path: F:\Yolo\yolov5\screw 运行后报错找不到数据库,原来是:没有转义,所以我改成用相对路径了。如果用绝对路径应该注意:的转义,或者””引起来。
5、 训练
至此标注完成,回到pycharm里,在编辑配置里对train.py 进行配置,后续detect.py同样方法。
--batch-size 16 --epochs 500 --data screw.yaml --cfg models/yolov5s.yaml --weights yolov5s.pt
在train.py 输入参数配置里输入上面一行,点击确定。开始训练,结果存入runs\train\exp中。
batch-size 16 每次训练的数据个数
--epochs 500 迭代次数
--data screw.yaml 数据集
--cfg models 用的yolov5的模型
在这需要记录的是,必须得会看训练结果,参考了这篇文章,发现我的结果都是错的,呵呵
如何解读和分析 YOLO 训练结果:实用指南_yolov8训练怎麼看train結果-优快云博客
这里有几点感触:
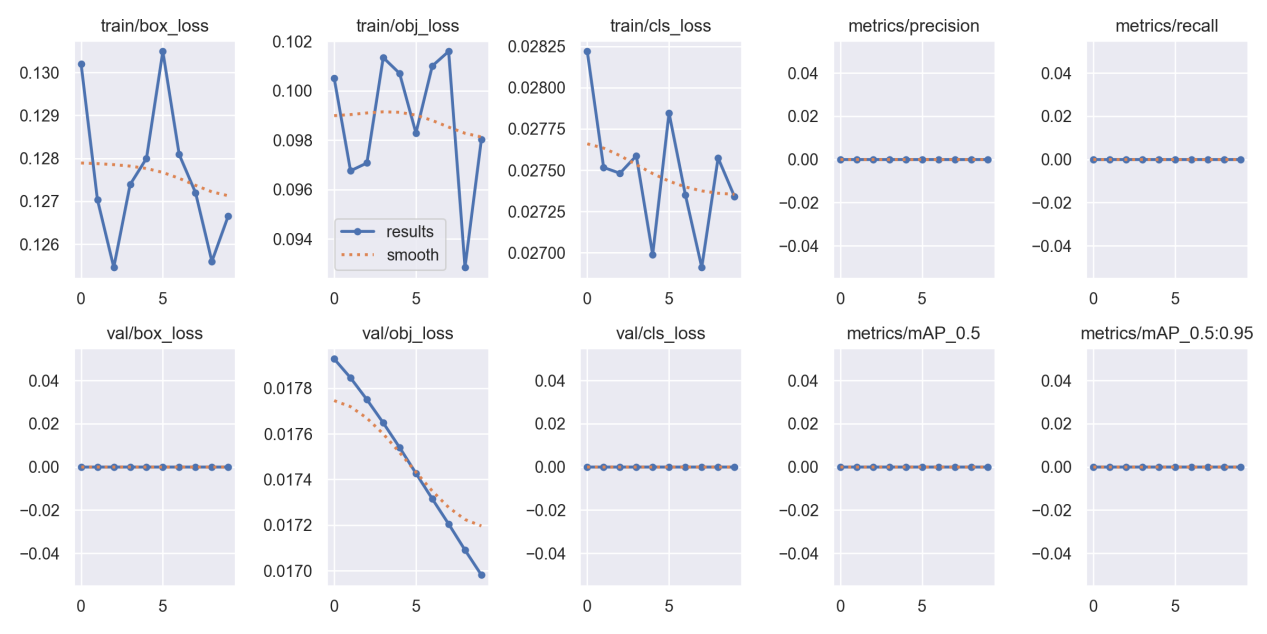
- 我的图像是1280*720,默认是640,我把imgsz的参数输入后,train.py运行慢了很多,效果感觉没变化。因为我一开始epochs=10,调节图像大小输入后,检测结果依然是 no detect;
- 开始epochs=10,训练结果中map为0
- 结果中的文件如下图:
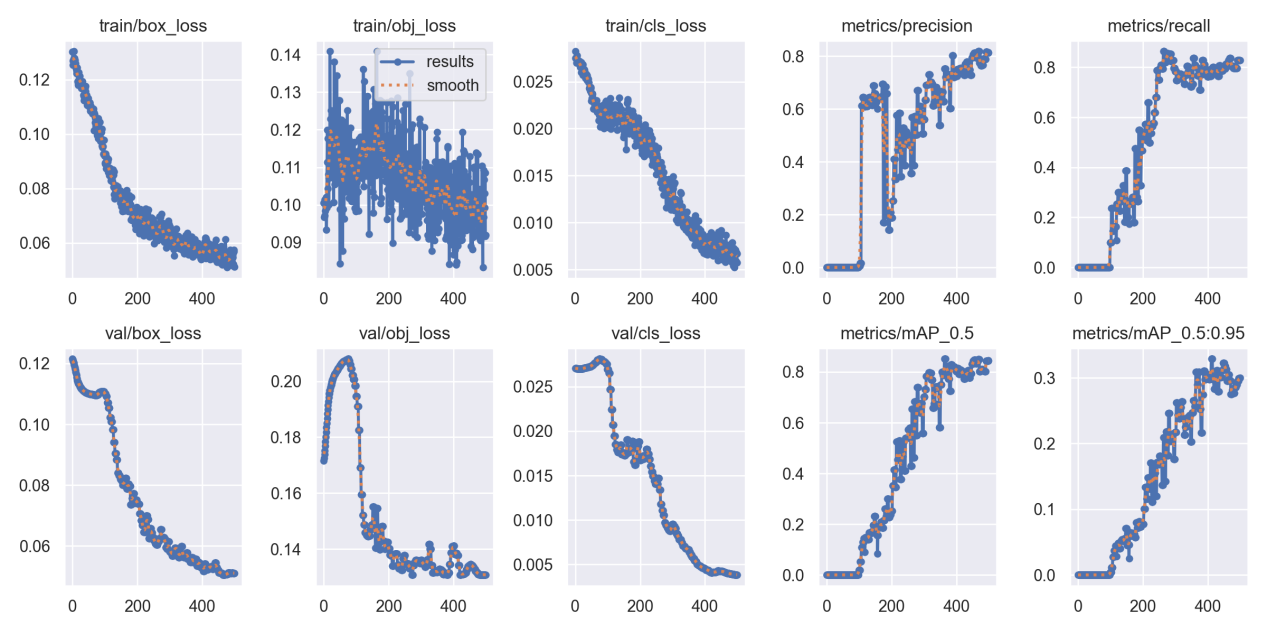
其中最重要的就是result.csv中的结果和confusion_matrix(混淆矩阵),result中的map应该大于0.3.我的是0,肯定不对。后面我用这个权重文件去检测,果然啥也检测不出来。

6、预测目标
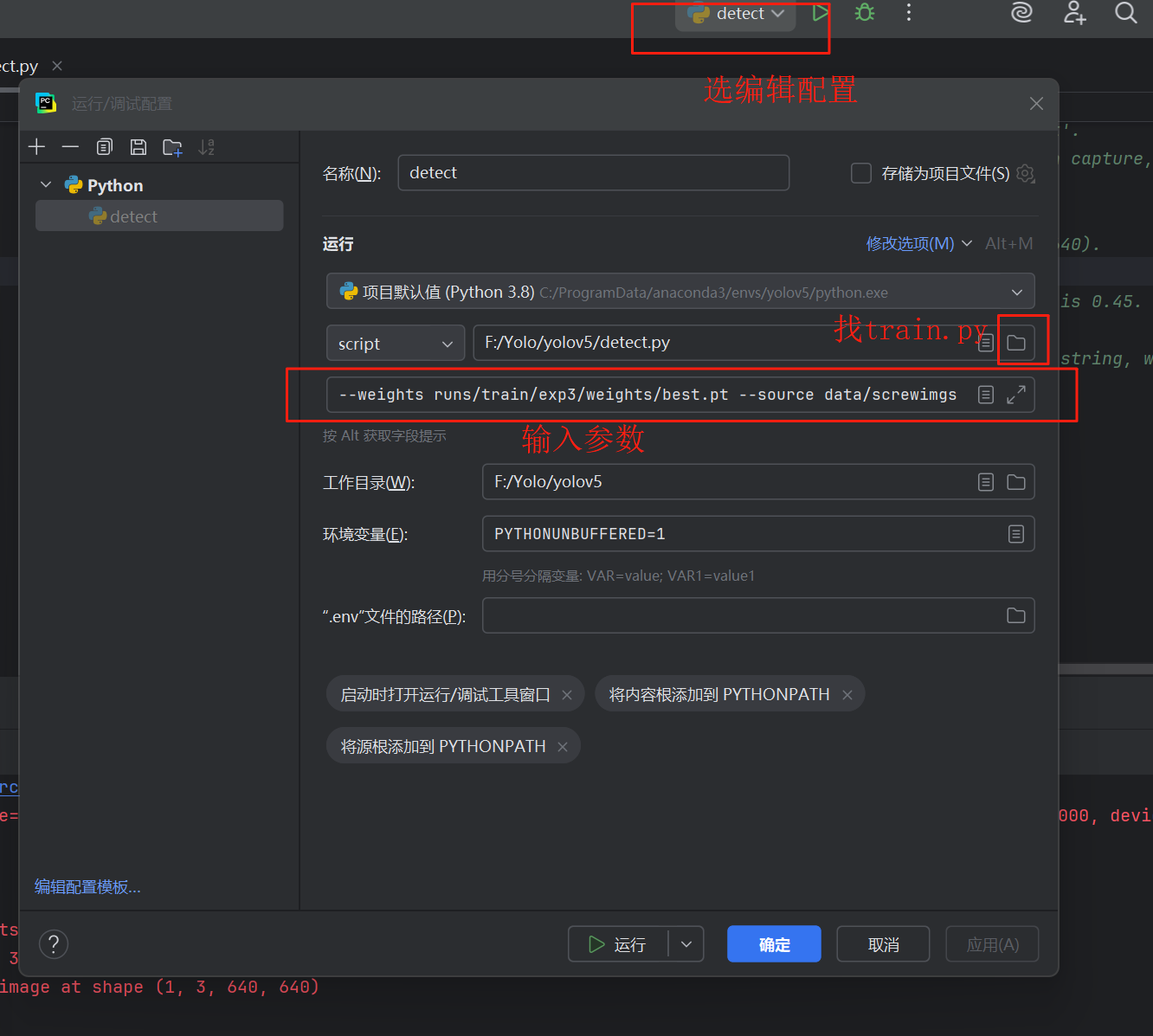
检测目标,在pycharm里配置detect.py,输入下面参数,点击确定,注意best.pt是自己训练好的权重文件。
--weights runs/train/exp/weights/best.pt --source data/screwimgs --data=data/screw.yaml
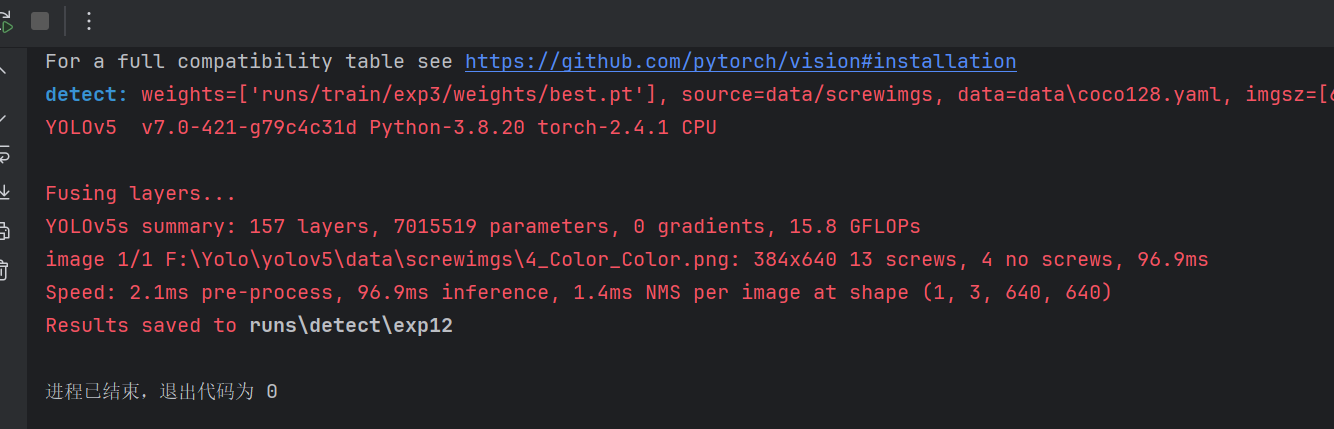
结果如下图。

7 GPU版本
cmd命令输入nvidia-smi,查看自己电脑的CUDA版本

我的版本为12.9
下一步下载cudaToolKit,本着比实际要低不能差太多的原则,我选择下载cudaToolKit12.8,cudnn,pytorch,可是在下载pytorch的时候提示:
报错:12.8还没被支持
(yolov5gpu) PS F:\Yolo\yolov5> pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128 Looking in indexes: https://download.pytorch.org/whl/cu128
ERROR: Could not find a version that satisfies the requirement torch==2.7.0 (from versions: none) ERROR: No matching distribution found for torch==2.7.0
需要降版本,torch官网给的下载地址,但是torch==2.7.0和2.6.0其实都没有发布,所以我重新下载了cudaToolKit12.4

下载地址
CUDA下载官网:CUDA Toolkit Archive | NVIDIA Developer![]() https://developer.nvidia.com/cuda-toolkit-archive
https://developer.nvidia.com/cuda-toolkit-archive
下载安装后输入nvcc -V检查是否安装成功

cudnn官网下载地址:"cuDNN Archive | NVIDIA Developer![]() https://developer.nvidia.com/rdp/cudnn-archive#a-collapse742-10"
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse742-10"
解压cuDNN压缩包,然后将cuDNN文件夹里面的几个文件复制到CUDA的安装目录下直接覆盖
在yolov5新建一个虚拟环境yolov5gpu124,激活虚拟环境,运行下面的torch安装命令,安装gpu torch。
torch官网
Previous PyTorch Versions | PyTorch![]() https://pytorch.org/get-started/previous-versions/
https://pytorch.org/get-started/previous-versions/
torch安装命令:
conda install pytorch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 pytorch-cuda=12.4 -c pytorch -c nvidia
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
安装后验证:

在yolov5gpu124环境下,安装yolo其他依赖
pip install -r requirements.txt
然后运行detect.py

同一张图比较:
96.9ms变成了6ms


















 2303
2303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









