




一、word-level Model(基于词级模型)
使用基于单词的模型时需要处理规模庞大的词汇表,例如Word2Vec和 glove,是利用word embedding的方法来得到每一个word的vec,这种方法需要去处理规模庞大的词汇表。
这种方式虽然效果不错,但是对于单词而言,只要稍微做些改变就是另一个单词了。
存在的一些问题:
1.容易出现单词不存在于词汇库中的情况,也就是 OOV(out-of-vocabulary)
2.非正式拼写
3.拼写错误
4.对名字和地名的音译
二、Character-Level Model(字符级语言模型)
以Character 作为基本单位的,这种方式虽然能够很好的对字库中每一个 Char 进行向量表示。
单词嵌入可以由字符嵌入表示:
1.能为不知道的单词生成嵌入
2.相似的拼写有相似的嵌入
3.解决了oov问题
连接的语言可以被分解为字符
有些令人惊讶的是,传统上,音素/字母不是一个语义单元,但在DL模型中却是。
**缺点:**相比于 word-level , Character-level 的输入句子变长,使得数据变得稀疏,而且对于远距离的依赖难以学到,训练速度降低。
解决办法:
2017年,Jason Lee等人开发出一种(无显式分割的全字符级神经机器翻译)Fully Character-Level Neural Machine Translation without Explicit Segmentation,下图是该模型的Encoder,Decoder是一个char-level的GRU,利用了多层的convolution, pooling与highway layer来解决这一问题。
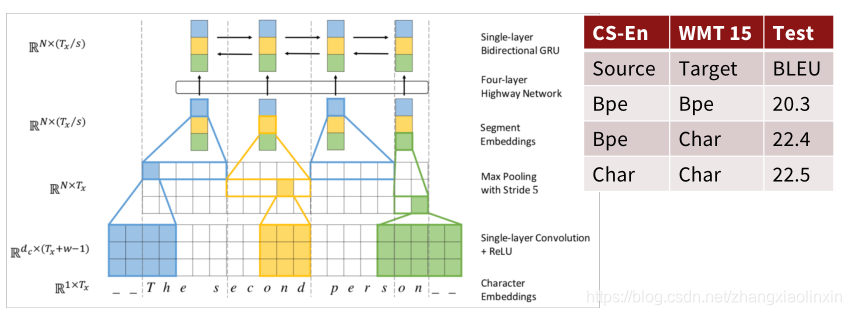
该论文思路如下:
1.输入的字符首先需要经过 Character embedding 层,并被转化为 character embeddings 表示;
2.采用 不同窗口大小的卷积核对输入字符的 character embeddings 表示进行卷积操作,论文中采用的窗口的大小分别为 3、4、5 ,也就是说学习 Character-level 的 3-gram、4-gram、5-gram;
3.对不同卷积层的卷积结果进行 max-pooling 操作,即捕获其最显著特征生成 segment embedding;
4.segment embedding 经过 Highway Network (有些类似于Residual netw
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









