




1. 问题:
如何同时获取list中元素的下标和值?
2. 解决方法:
使用enumerate函数进行遍历操作
示例:
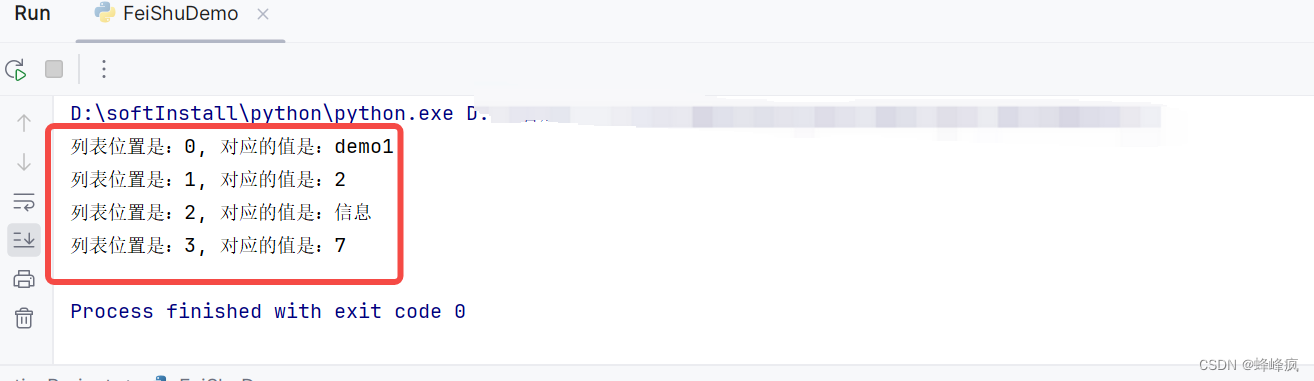
test_list = ["demo1", 2, "信息", 7]
def get_list_index_and_value(input_list: list):
for index, item in enumerate(input_list):
print(f"列表位置是:{index}, 对应的值是:{item}")
示例输出:
1. 问题:
如何同时获取list中元素的下标和值?
2. 解决方法:
使用enumerate函数进行遍历操作
示例:
test_list = ["demo1", 2, "信息", 7]
def get_list_index_and_value(input_list: list):
for index, item in enumerate(input_list):
print(f"列表位置是:{index}, 对应的值是:{item}")
示例输出:
 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























