



一、需求背景
在不同的数据库表或文件中,存在相同表或字段的数据,需要对比相同表中的数据是否一致,根据某些关键字段识别每条记录。
二、实现方案
1. 首先,通过关键字段(一个或者多个),将两个表源数据进行左连接合并,筛选出只有左边数据源记录,即是左边数据源独有的记录;
2. 其次,筛选出两者共有的记录,拆分成两个独立的数据源,不设置关键字段,再次进行左连接合并;
3. 再者,在合并结果中,筛选出左边数据源的记录,即是两个数据源每行存在不相同数据的记录;
三、代码实现
import pandas as pd
import gc
data = {
'Name': ['John', 'Anna', 'Peter', 'Linda','huahua'],
'Age': [28, 34, 29, 32,90],
'City': ['New York', 'Paris', 'Berlin', 'London','nanjing']
}
data_copy = {
'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 34, 20, 32],
'City': ['New York', 'Par', 'Berlin', 'London']
}
df = pd.DataFrame(data)
df_copy = pd.DataFrame(data_copy)
merge = pd.merge(df,df_copy, on='Name', how='left', indicator=True)
both_df = merge[merge['_merge']=='both']
# 获取独有数据
lost_df = merge[merge['_merge']=='left_only']
del merge
gc.collect()
left_col = both_df.filter(like='_x')
right_col = both_df.filter(like='_y')
left_df = left_col.rename(columns=lambda x: x[:-2]).copy()
right_df = right_col.rename(columns=lambda x: x[:-2]).copy()
common_col = both_df['Name']
left_df = pd.concat([common_col,left_df], axis=1)
right_df = pd.concat([common_col,right_df], axis=1)
# 获取两个数据源都存在,但某些字段数据不同的记录
diff_merge = pd.merge(left_df,right_df,how='left',indicator=True)
diff_df = diff_merge[diff_merge['_merge']=='left_only']
print("丢失的记录")
print(lost_df)
print("差异的数据")
print(diff_df)
diff_df.to_csv('output.txt', sep='\t',index=False)
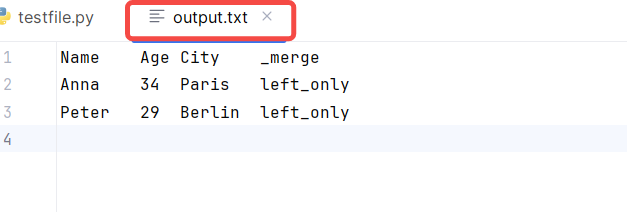
四、结果输出


















 2193
2193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









