 C++部署Yolov8withTensorRT:从ONNX到高效推理
C++部署Yolov8withTensorRT:从ONNX到高效推理




 本文详细介绍了如何使用TensorRT7.1.3.4进行Yolov8模型的C++部署,包括导出ONNX模型、CMake配置、编译与运行,以及测试和模型替换的注意事项。
本文详细介绍了如何使用TensorRT7.1.3.4进行Yolov8模型的C++部署,包括导出ONNX模型、CMake配置、编译与运行,以及测试和模型替换的注意事项。
Yolov8 tensorRT 的 C++ 部署
前几篇写了 yolov8 相关的 瑞芯微rknn、地平线Horizon 的仿真和C++相关的部署,以及tensorRT的python版本部署,本篇说说tensorRT 的 C++ 部署,所使用的模型是基于之前导出的onnx模型。
TensorRT版本:TensorRT-7.1.3.4
1 导出 onnx 模型
导出适配本实例的onnx模型参考【yolov8 导出onnx-2023年11月15日版本】。
2 编译
编译前修改 CMakeLists.txt 对应的TensorRT版本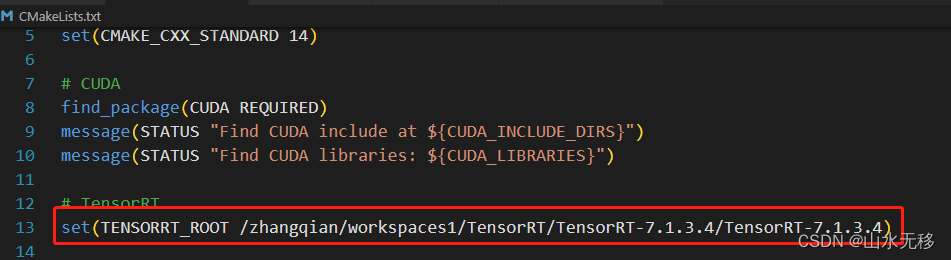
cd yolov8_tensorRT_Cplusplus
mkdir build
cd build
cmake ..
make
3 运行
运行时如果.trt模型存在则直接加载,若不存会自动先将onnx转换成 trt 模型,并保存在给定的路径,然后运行推理
# 运行时如果.trt模型存在则直接加载,若不存会自动先将onnx转换成 trt 模型,并保存在给定的路径,然后运行推理。
cd build
./yolo_trt
4 测试效果
onnx 测试效果

tensorRT 测试效果

tensorRT 时耗
5 替换模型说明
1)按照本实例给的导出onnx方式导出对应的onnx;导出的onnx模型建议simplify后再转trt模型。
2)注意修改后处理相关 postprocess.hpp 中相关的参数(类别、输入分辨率等)。
修改相关的路径
std::string OnnxFile = "/zhangqian/workspaces1/TensorRT/yolov8_trt_Cplusplus/models/yolov8n_ZQ.onnx";
std::string SaveTrtFilePath = "/zhangqian/workspaces1/TensorRT/yolov8_trt_Cplusplus/models/yolov8n_ZQ.trt";
cv::Mat SrcImage = cv::imread("/zhangqian/workspaces1/TensorRT/yolov8_trt_Cplusplus/images/test.jpg");
int img_width = SrcImage.cols;
int img_height = SrcImage.rows;
CNN YOLO(OnnxFile, SaveTrtFilePath, 1, 3, 640, 640, 7); // 1, 3, 640, 640, 7 前四个为模型输入的NCWH, 7为模型输出叶子节点的个数+1,(本示例中的onnx模型输出有6个叶子节点,再+1=7)
YOLO.ModelInit();
YOLO.Inference(SrcImage);
for (int i = 0; i < YOLO.DetectiontRects_.size(); i += 6)
{
int classId = int(YOLO.DetectiontRects_[i + 0]);
float conf = YOLO.DetectiontRects_[i + 1];
int xmin = int(YOLO.DetectiontRects_[i + 2] * float(img_width) + 0.5);
int ymin = int(YOLO.DetectiontRects_[i + 3] * float(img_height) + 0.5);
int xmax = int(YOLO.DetectiontRects_[i + 4] * float(img_width) + 0.5);
int ymax = int(YOLO.DetectiontRects_[i + 5] * float(img_height) + 0.5);
char text1[256];
sprintf(text1, "%d:%.2f", classId, conf);
rectangle(SrcImage, cv::Point(xmin, ymin), cv::Point(xmax, ymax), cv::Scalar(255, 0, 0), 2);
putText(SrcImage, text1, cv::Point(xmin, ymin + 15), cv::FONT_HERSHEY_SIMPLEX, 0.7, cv::Scalar(0, 0, 255), 2);
}
imwrite("/zhangqian/workspaces1/TensorRT/yolov8_trt_Cplusplus/images/result.jpg", SrcImage);
printf("== obj: %d \n", int(float(YOLO.DetectiontRects_.size()) / 6.0));
【特别说明】:本示例只是用来测试流程,模型效果并不保证,且代码整理的布局合理性没有过多的考虑。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









