



yolov13部署。
特别说明:如有侵权告知删除,谢谢。
完整代码:包括onnx转rknn和测试代码、rknn板端部署C++代码
【onnx转rknn和测试代码】
【rknn板端部署C++代码】
1 模型训练
yolov13 训练参考官方代码。
2 导出 yolov13 onnx
导出onnx修改以下几处,和之前的导出yolov8、yolov11、yolov12等方式一样。
第一处:修改导出onnx的检测头
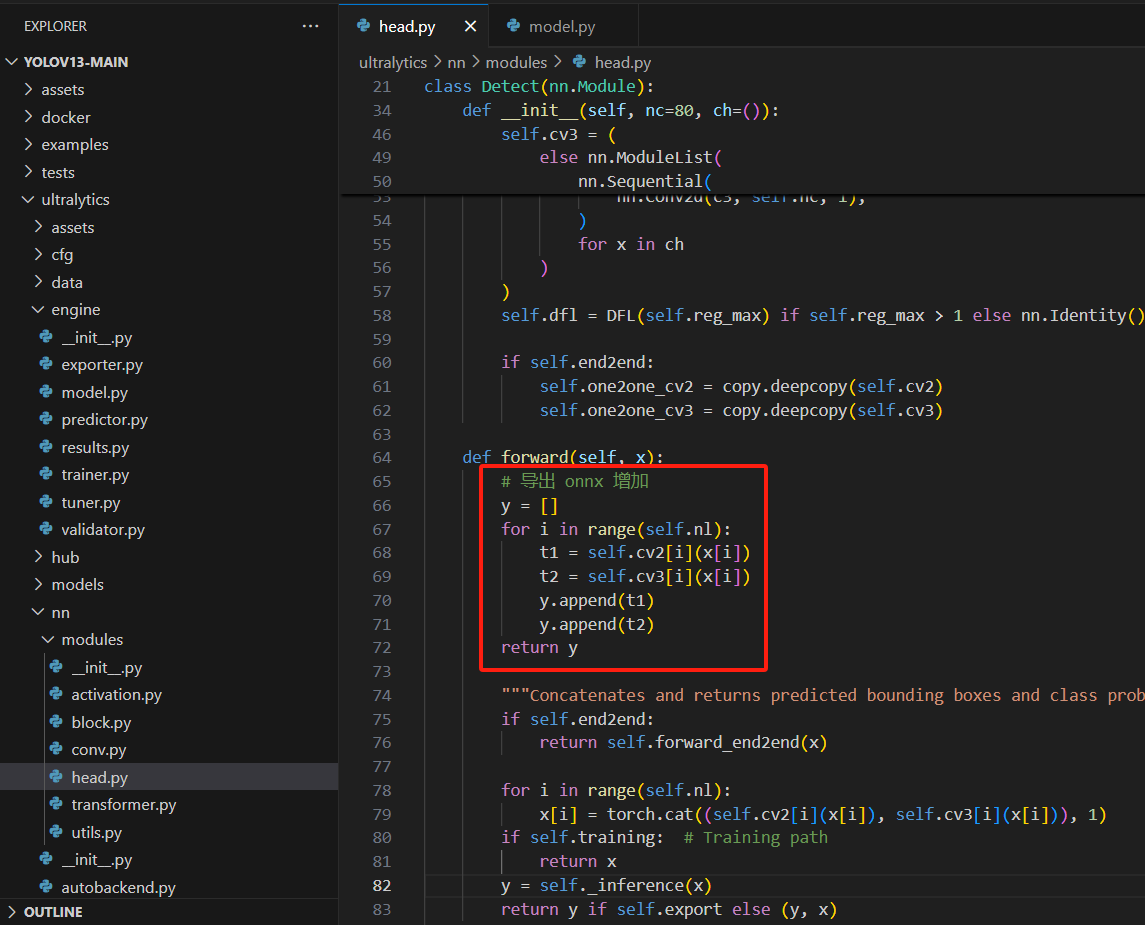
# 导出 onnx 增加
y = []
for i in range(self.nl):
t1 = self.cv2[i](x[i])
t2 = self.cv3[i](x[i])
y.append(t1)
y.append(t2)
return y
第二处:增加保存onnx代码
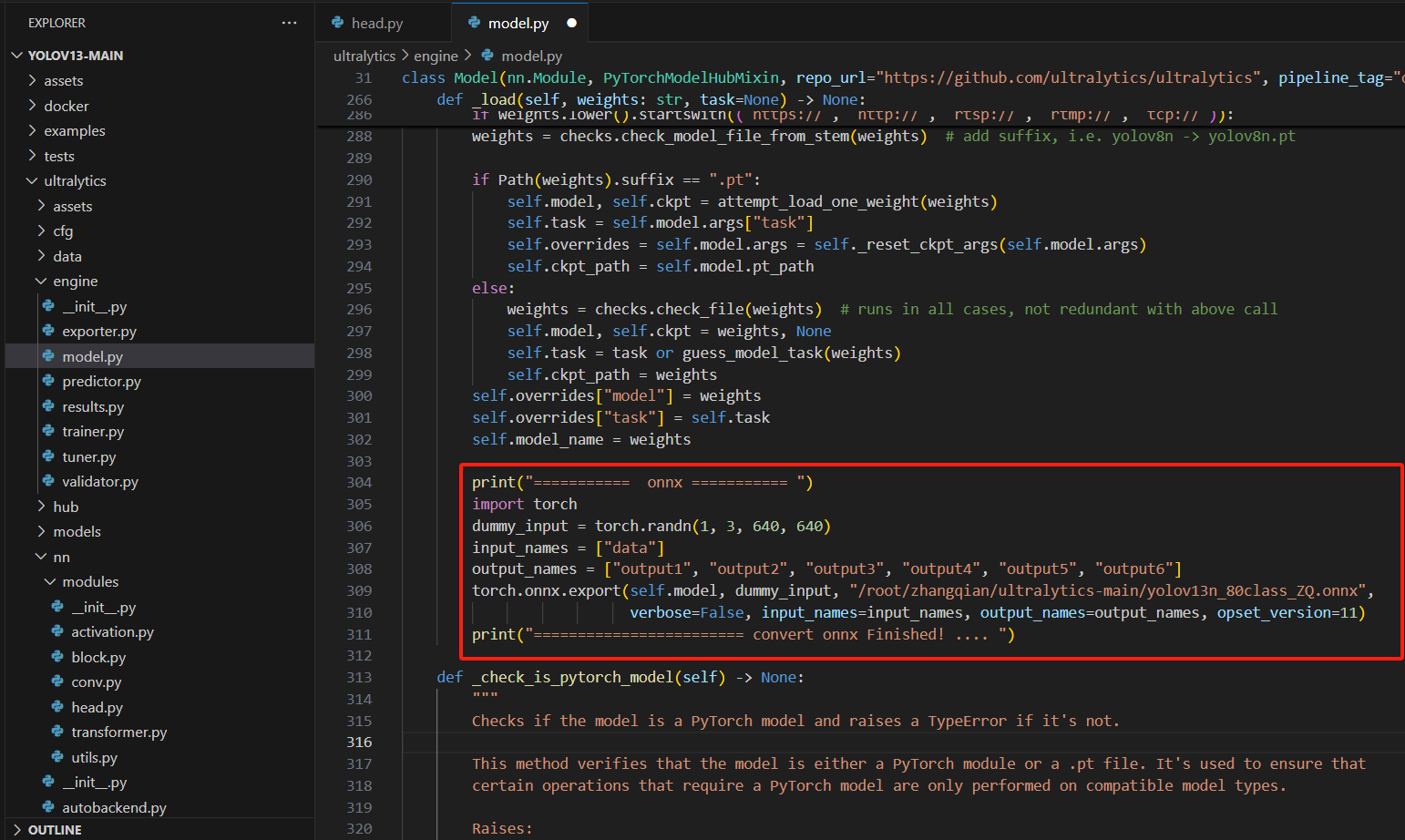
print("=========== onnx =========== ")
import torch
dummy_input = torch.randn(1, 3, 640, 640)
input_names = ["data"]
output_names = ["output1", "output2", "output3", "output4", "output5", "output6"]
torch.onnx.export(self.model, dummy_input, "/root/zhangqian/ultralytics-main/yolov13n_80class_ZQ.onnx",
verbose=False, input_names=input_names, output_names=output_names, opset_version=11)
print("======================== convert onnx Finished! .... ")
修改完以上两处,运行以下代码:
from ultralytics import YOLO
model = YOLO(model='yolov13n.pt') # load a pretrained model (recommended for training)
results = model(task='detect', source='./test.jpg', save=True) # predict on an image
特别说明: 修改完以上两处后运行会报错,但不影响onnx的生成;生成onnx后强烈建议用from onnxsim import simplify 处理一下再转rknn。
3 测试onnx效果
pytorch效果

onnx效果

4 onnx转rknn
onnx转rknn代码链接
转rknn后仿真结果

5 rk3588板子测试yolov11模型
使用的 rknn_toolkit 版本:rknn_toolkit2-2.2.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
C++代码中的库和工具链的版本注意对应适配。
1)编译
cd examples/rknn_yolov13_demo_dfl_open
bash build-linux_RK3588.sh
2)运行
cd install/rknn_yolo_demo_Linux
./rknn_yolo_demo
注意:修改模型、测试图像、保存图像的路径,修改文件为src下的main.cc
int main(int argc, char **argv)
{
char model_path[256] = "/home/zhangqian/rknn/examples/rknn_yolov13_demo_dfl_open/model/RK3588/yolov13n_80class_ZQ.rknn";
char image_path[256] = "/home/zhangqian/rknn/examples/rknn_yolov13_demo_dfl_open/test.jpg";
char save_image_path[256] = "/home/zhangqian/rknn/examples/rknn_yolov13_demo_dfl_open/test_result.jpg";
detect(model_path, image_path, save_image_path);
return 0;
}
3)板端效果和时耗

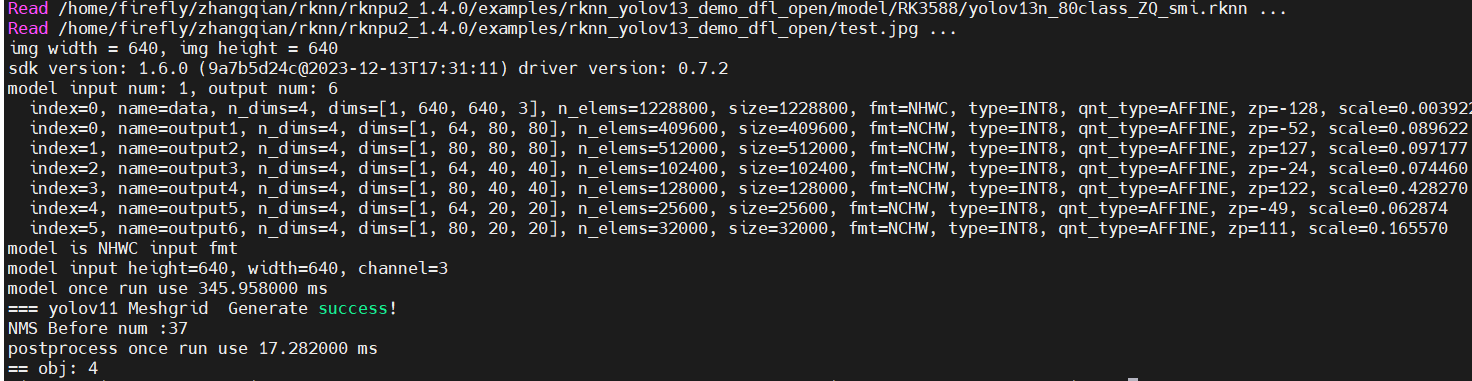
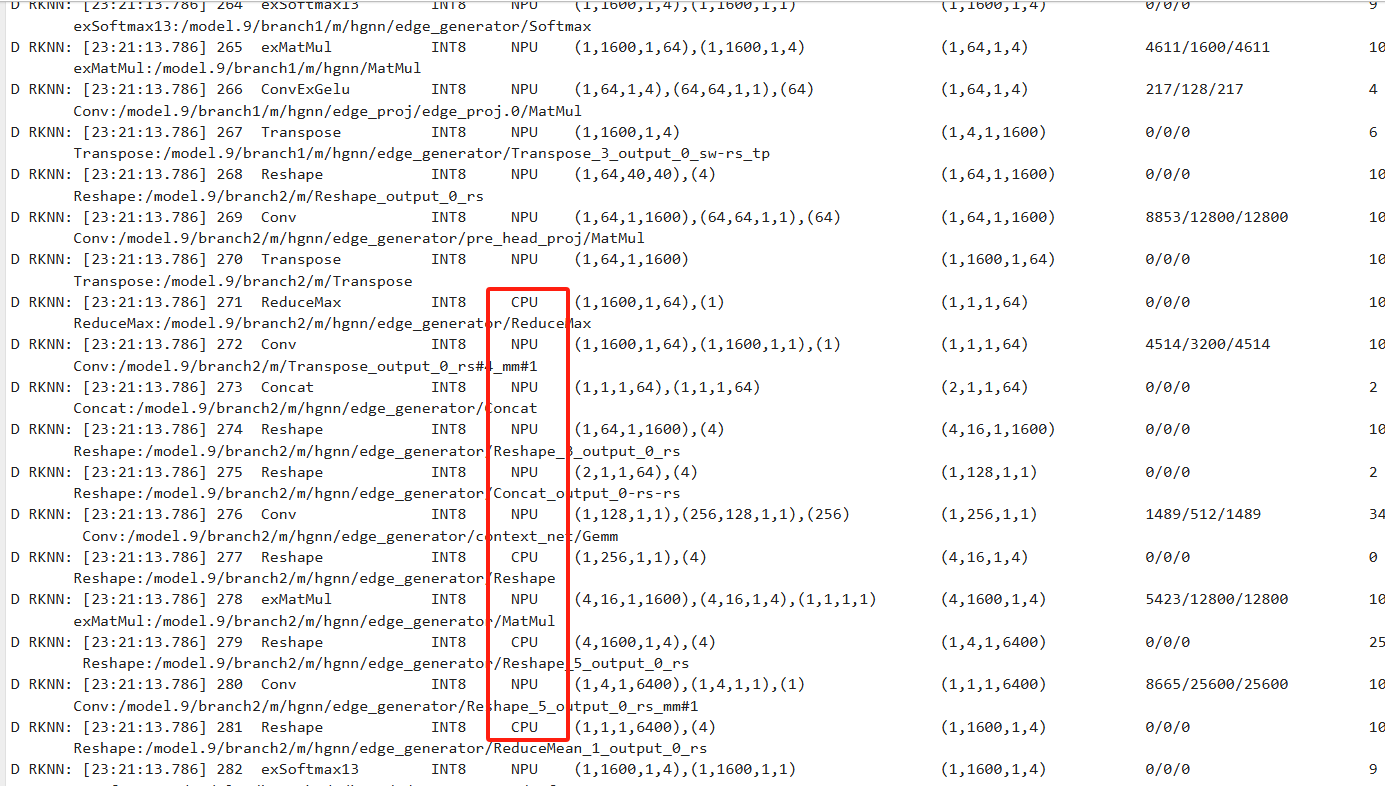
这个时耗比较长,毫无疑问很多算子切换到cpu上进行的。



















 1121
1121



 到【灌水乐园】发言
到【灌水乐园】发言








