



 该文章介绍了如何在瑞芯微RKNN平台上使用C++进行Yolov8模型的部署,包括模型转换、代码准备、后处理方法的详细步骤,并提供了开源代码和模型,便于读者验证和测试。在rk3588芯片上进行了实际部署,展示了板端效果和优化后的后处理时耗。
该文章介绍了如何在瑞芯微RKNN平台上使用C++进行Yolov8模型的部署,包括模型转换、代码准备、后处理方法的详细步骤,并提供了开源代码和模型,便于读者验证和测试。在rk3588芯片上进行了实际部署,展示了板端效果和优化后的后处理时耗。
上一篇博客 yolov8 瑞芯微RKNN和地平线Horizon芯片仿真测试部署 写了在rknn模型的转换与PC端仿真测试,有网友希望写一篇在板子上部署的博文和开源提供C++代码。这一篇基于rknn板子进行C++部署,并开源提供完整的源代码和模型,供网友自行进行测试验证。
特别说明:如有侵权告知删除,谢谢。
【完整代码】代码和模型
1、rknn模型准备
onnx转rknn模型这一步就不再赘述,请参考上一篇 ”yolov8 瑞芯微RKNN和地平线Horizon芯片仿真测试部署“ 。上一篇提供了完整的模型和代码,如果仅仅是想验证模型,可以直接拿提供的rknn模型进行后续的步骤,本篇也是基于上一篇转好的rknn模型进行的,在rk3588芯片部署测试。
2、C++代码准备
本篇中的 C++ 代码基于瑞芯微官方提供的 rknpu2_1.3.0 进行的。官方提供的开源示例参考 ,提取码:rknn .
3、C++ 代码说明
模型和图片读取部分参考官方提供的示例,主要说明后处理部分。定义了一个yolov8后处理类,将模型输出进行解码处理,解码结果装在一个vector中,装的格式按照 classId,score,xmin,ymin,xmax,ymax, classId,score,xmin,ymin,xmax,ymax … 进行,每六个数据为一个检测框,对 vector 进行遍历得到检测结。
// 后处理部分
std::vector<float> out_scales;
std::vector<int32_t> out_zps;
for (int i = 0; i < io_num.n_output; ++i)
{
out_scales.push_back(output_attrs[i].scale);
out_zps.push_back(output_attrs[i].zp);
}
int8_t *pblob[6];
for (int i = 0; i < io_num.n_output; ++i)
{
pblob[i] = (int8_t *)outputs[i].buf;
}
// 将检测结果按照classId、score、xmin1、ymin1、xmax1、ymax1 的格式存放在vector<float>中
GetResultRectYolov8 PostProcess;
std::vector<float> DetectiontRects;
PostProcess.GetConvDetectionResult(pblob, out_zps, out_scales, DetectiontRects);
for (int i = 0; i < DetectiontRects.size(); i += 6)
{
int classId = int(DetectiontRects[i + 0]);
float conf = DetectiontRects[i + 1];
int xmin = int(DetectiontRects[i + 2] * float(img_width) + 0.5);
int ymin = int(DetectiontRects[i + 3] * float(img_height) + 0.5);
int xmax = int(DetectiontRects[i + 4] * float(img_width) + 0.5);
int ymax = int(DetectiontRects[i + 5] * float(img_height) + 0.5);
char text1[256];
sprintf(text1, "%d:%.2f", classId, conf);
rectangle(src_image, cv::Point(xmin, ymin), cv::Point(xmax, ymax), cv::Scalar(255, 0, 0), 2);
putText(src_image, text1, cv::Point(xmin, ymin + 15), cv::FONT_HERSHEY_SIMPLEX, 0.7, cv::Scalar(0, 0, 255), 2);
}
imwrite(save_image_path, src_image);
后处理核心部分代码如下,其中后处理代码不一定是最优的,如果有更优的写法欢迎交流。完整代码请参本实例对应的github仓库,代码和模型 。
int GetResultRectYolov8::GetConvDetectionResult(int8_t **pBlob, std::vector<int> &qnt_zp, std::vector<float> &qnt_scale, std::vector<float> &DetectiontRects)
{
int ret = 0;
if (meshgrid.empty())
{
ret = GenerateMeshgrid();
}
int gridIndex = -2;
float xmin = 0, ymin = 0, xmax = 0, ymax = 0;
float cls_val = 0;
float cls_max = 0;
int cls_index = 0;
int quant_zp_cls = 0, quant_zp_reg = 0;
float quant_scale_cls = 0, quant_scale_reg = 0;
DetectRect temp;
std::vector<DetectRect> detectRects;
for (int index = 0; index < headNum; index++)
{
int8_t *reg = (int8_t *)pBlob[index * 2 + 0];
int8_t *cls = (int8_t *)pBlob[index * 2 + 1];
quant_zp_reg = qnt_zp[index * 2 + 0];
quant_zp_cls = qnt_zp[index * 2 + 1];
quant_scale_reg = qnt_scale[index * 2 + 0];
quant_scale_cls = qnt_scale[index * 2 + 1];
for (int h = 0; h < mapSize[index][0]; h++)
{
for (int w = 0; w < mapSize[index][1]; w++)
{
gridIndex += 2;
if (1 == class_num)
{
cls_max = sigmoid(DeQnt2F32(cls[0 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_cls, quant_scale_cls));
cls_index = 0;
}
else
{
for (int cl = 0; cl < class_num; cl++)
{
cls_val = cls[cl * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w];
if (0 == cl)
{
cls_max = cls_val;
cls_index = cl;
}
else
{
if (cls_val > cls_max)
{
cls_max = cls_val;
cls_index = cl;
}
}
}
cls_max = sigmoid(DeQnt2F32(cls_max, quant_zp_cls, quant_scale_cls));
}
if (cls_max > objectThresh)
{
xmin = (meshgrid[gridIndex + 0] - DeQnt2F32(reg[0 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
ymin = (meshgrid[gridIndex + 1] - DeQnt2F32(reg[1 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
xmax = (meshgrid[gridIndex + 0] + DeQnt2F32(reg[2 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
ymax = (meshgrid[gridIndex + 1] + DeQnt2F32(reg[3 * mapSize[index][0] * mapSize[index][1] + h * mapSize[index][1] + w], quant_zp_reg, quant_scale_reg)) * strides[index];
xmin = xmin > 0 ? xmin : 0;
ymin = ymin > 0 ? ymin : 0;
xmax = xmax < input_w ? xmax : input_w;
ymax = ymax < input_h ? ymax : input_h;
if (xmin >= 0 && ymin >= 0 && xmax <= input_w && ymax <= input_h)
{
temp.xmin = xmin / input_w;
temp.ymin = ymin / input_h;
temp.xmax = xmax / input_w;
temp.ymax = ymax / input_h;
temp.classId = cls_index;
temp.score = cls_max;
detectRects.push_back(temp);
}
}
}
}
}
std::sort(detectRects.begin(), detectRects.end(), [](DetectRect &Rect1, DetectRect &Rect2) -> bool
{ return (Rect1.score > Rect2.score); });
std::cout << "NMS Before num :" << detectRects.size() << std::endl;
for (int i = 0; i < detectRects.size(); ++i)
{
float xmin1 = detectRects[i].xmin;
float ymin1 = detectRects[i].ymin;
float xmax1 = detectRects[i].xmax;
float ymax1 = detectRects[i].ymax;
int classId = detectRects[i].classId;
float score = detectRects[i].score;
if (classId != -1)
{
// 将检测结果按照classId、score、xmin1、ymin1、xmax1、ymax1 的格式存放在vector<float>中
DetectiontRects.push_back(float(classId));
DetectiontRects.push_back(float(score));
DetectiontRects.push_back(float(xmin1));
DetectiontRects.push_back(float(ymin1));
DetectiontRects.push_back(float(xmax1));
DetectiontRects.push_back(float(ymax1));
for (int j = i + 1; j < detectRects.size(); ++j)
{
float xmin2 = detectRects[j].xmin;
float ymin2 = detectRects[j].ymin;
float xmax2 = detectRects[j].xmax;
float ymax2 = detectRects[j].ymax;
float iou = IOU(xmin1, ymin1, xmax1, ymax1, xmin2, ymin2, xmax2, ymax2);
if (iou > nmsThresh)
{
detectRects[j].classId = -1;
}
}
}
}
return ret;
}
4、编译运行
1)编译
cd examples/rknn_yolov8_demo_open
bash build-linux_RK3588.sh
2)运行
cd install/rknn_yolov8_demo_Linux
./rknn_yolov8_demo
注意:修改模型、测试图像、保存图像的路径,所在文件为 src 下main.cc文件。
5、板端效果
冒号“:”前的数子是coco的80类对应的类别,后面的浮点数是目标得分。(类别:得分)

(注:图片来源coco128)
说明:推理测试预处理没有考虑等比率缩放,激活函数 SiLU 用 Relu 进行了替换。由于使用的是coco128的128张图片数据进行训练的,且迭代的次数不多,效果并不是很好,仅供测试流程用。换其他图片测试检测不到属于正常现象,最好选择coco128中的图像进行测试。
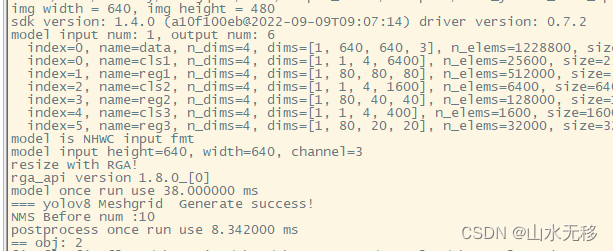
6、模型和后处理时耗
把模型和后处理时耗贴出来,供大家参考,使用芯片rk3588。

2024年1月12日:后处理代码有所优化,后处理时耗由21ms降低至8ms。(检测类别越多效果越明显,检测1个类别就没有优化效果,代码已同步到对应的代码仓中)



















 5702
5702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









