




 本文介绍了R语言的基础知识,包括R与RStudio的关系,工作目录设置,变量与赋值,数据类型及其转换,以及R中的数据结构(向量、列表、矩阵、数据框)和数据的导入导出方法。
本文介绍了R语言的基础知识,包括R与RStudio的关系,工作目录设置,变量与赋值,数据类型及其转换,以及R中的数据结构(向量、列表、矩阵、数据框)和数据的导入导出方法。
r语言作为一种常用于数据处理领域语言,较为广泛使用的是其对数据进行操作的功能,基础包括变量赋值、数据类型、数据导出和导入等,更深层次还包括统计相关函数、库函数调用、数据整合整理等,在r语言中也有很多第三方包,类似于python的库函数,在特定情况下可以被调用并完成特定操作。
接下来介绍一些r语言的基本知识和相关操作:
一、R 和R studio
r语言是一种解释的语言,类似于MATLAB,是按行步进运行的,同时也是统计计算和绘图的环境,它汇集了许多函数,能够提供强大的功能。
类似于Python和Pycharm、C/C++和visual studio,r语言有自己的idle(R)以及开源集成开发环境(R studio),R studio提供了一个具有很多功能的环境,使R更容易使用,是在终端中使用R的绝佳选择。值得注意的是R studio是英文编辑环境,使用时需要注意。
在编写r程序时,更建议使用R studio
具体的安装方式不再叙述,详细可见这篇文章:
R及RStudio下载安装教程(超详细)
二、工作目录的设置
工作目录会影响r运行过程中输出文件的位置以及读取文件的路径,所有的文件读取和写入操作都会默认在这个目录下进行,除非另有指定。
一般情况下使用setwd()函数设置工作目录
setwd("pathway")
例如设置工作路径为桌面文件夹:
setwd("C:/Users/zhang/Desktop")
值得注意的是,从Windows系统复制的文件地址
“C:\Users\zhang\Desktop”
分隔符使用的是反斜杠"“,但是r语言中要求使用正斜杠”/",要注意替换
设置工作目录后,可以用相对路径直接读取或写入该目录下的文件,而不需要提供完整的路径,这样可以简化代码,并且避免在每个文件操作中都指定完整的绝对路径。
如果想知道当前的工作目录是什么,可以使用getwd()获取,便会直接输出当前的目录
三、变量与变量赋值
变量名
与其他编程语言类似,r语言的变量名设置也有类似的规则:
变量名可以包含字母、数字、点号和下划线,不能包含其他符号,必须以字母或点号开头。变量名是区分大小写的。
变量赋值
在R中,通常使用 <- 或 = 运算符进行变量赋值。
例如:
x <- 10
y = 5
#这将把值10赋给变量x,把值5赋给变量y。
x <- 10
x <- x + 5 # x的值为15
删除变量
可以使用rm()函数删除已存在的变量。例如:
x <- 10
rm(x) # 删除变量x
特殊值
在R中,有一些特殊的值,如NA表示缺失值、Inf表示无穷大等。
变量值查看
每当存储完一个变量之后,R studio右侧的变量框中便会出现该变量的相关信息,类似MATLAB,①可以通过点击该变量显示该变量的详细信息,②也可以通过view(变量名)来查看一个变量的详细信息,③也可以直接变量名来查看该变量的值。
四、数据类型
R语言是基于对象的语言,R中一切事物都可以看做是对象
对象有四种基本类型:
- 数值型(numeric):用于存储数值,可以是整数或浮点数。例如:5、3.14。
- 字符型(character):用于存储文本或字符。字符型的值需要用引号括起来。例如:“Hello”、‘World’。
- 逻辑型(logical):用于存储逻辑值,即TRUE或FALSE。例如:TRUE(T)、FALSE(F)。
- 复数型(complex):用于存储复数,由实部和虚部组成。例如:1+2i、2-3i。
在某些函数中,还要求有一种类型——因子型:
因子型(factor):用于表示具有限定数量的离散取值的变量。
可以用class()查看变量的数据类型
在R中,可以使用不同的函数进行数据类型之间的转换。以下是一些常用的数据类型转换函数:
as.numeric():#将其他数据类型转换为数值型。
as.character():#将其他数据类型转换为字符型。
as.logical()#将其他数据类型转换为逻辑型。
as.complex()#将其他数据类型转换为复数型。
as.factor()#将其他数据类型转换为因子
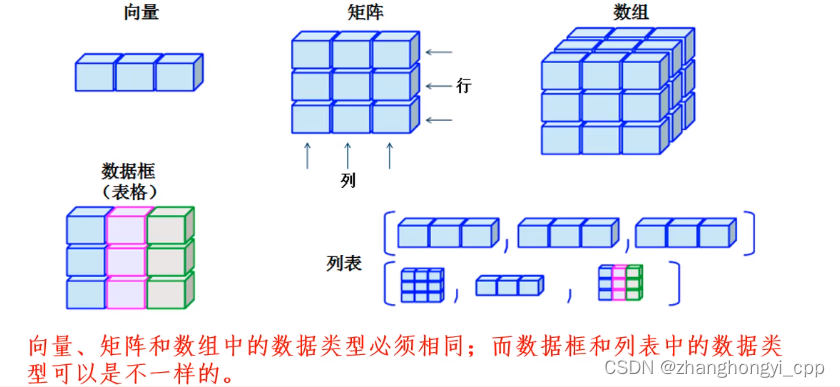
五、数据结构
R语言的数据结构包括向量(Vector)、列表(List)、矩阵(Matrix)、数据框(Data Frame)等。
1.向量(Vector):
向量是R语言中最基本的数据结构之一,是由一组相同类型的元素组成的一维数组。可以使用c()函数创建向量,例如:
x <- c(1, 2, 3, 4, 5)
R语言中的向量有以下几种类型:
- 逻辑向量(logical vector):包含TRUE或FALSE。
- 整数向量(integer vector):包含整数。
- 数值向量(numeric vector):包含浮点数。
- 字符串向量(character vector):包含字符型数据。
可以使用索引来访问向量中的元素,例如:x[1]表示访问向量x的第一个元素。
2.列表(List):
列表是由不同类型的元素组成的数据结构,可以包含向量、矩阵、数据框等。使用list()函数创建列表
例如:
list <- list(name = "John", age = 30, scores = c(80, 85, 90))
a <- c(1,2,3,4)
b <- c(“apple",“banana",“~rap e")
c <- matrix(1:10,nrow = 5)
d <-“Hello world”
mylist<- list(a,b,c,d)
列表中的元素可以通过名称或索引进行访问,例如:
my_list$name
#或
my_list[[1]]
3.矩阵(Matrix):
矩阵是二维的数据结构,包含相同类型的元素。可以使用matrix()函数创建矩阵
matrix(data, nrow, ncol, byrow = FALSE, dimnames = NULL)
其中:
data: 用来填充矩阵的数据。这可以是一个向量、列表或数组。
nrow: 矩阵的行数。
ncol: 矩阵的列数。
byrow: 一个逻辑值,指示矩阵是按行还是按列填充。默认值为 FALSE,表示按列填充。
dimnames: 一个包含两个元素的列表,用来指定行名和列名。如果提供了该参数,则必须是长度为2的列表,每个元素都是长度与相应维度相同的字符向量。
例如:
mat <- matrix(1:9, nrow = 3, ncol = 3)
可以通过行列索引来访问矩阵中的元素,例如:mat[1, 2]表示访问矩阵mat的第一行第二列的元素。m[m>30]代表m中所有大于30的元素。
数组可以视为一种多层矩阵,建立数组可以使用array()函数
array(data, dim = NULL, dimnames = NULL)
其中:
data: 用来填充数组的数据。这可以是一个向量、列表或矩阵。
dim: 数组的维度。可以是一个整数向量,指定每个维度的大小;也可以是一个具有维度属性的对象,例如矩阵或数组。
dimnames: 一个包含维度名称的列表。每个元素都是一个字符向量,指定相应维度的名称。
例如:
# 创建一个2x3x2的三维数组
arr1 <- array(1:12, dim = c(2, 3, 2))
print(arr1)
# 输出:
# , , 1
#
# [,1] [,2] [,3]
# [1,] 1 3 5
# [2,] 2 4 6
#
# , , 2
#
# [,1] [,2] [,3]
# [1,] 7 9 11
# [2,] 8 10 12
# 创建一个2x2x2的三维数组,并同时指定维度名称
arr2 <- array(1:8, dim = c(2, 2, 2), dimnames = list(c("row1", "row2"), c("col1", "col2"), c("depth1", "depth2")))
print(arr2)
# 输出:
# , , depth1
#
# col1 col2
# row1 1 3
# row2 2 4
#
# , , depth2
#
# col1 col2
# row1 5 7
# row2 6 8
4.数据框(Data Frame):
数据框是一种类似于电子表格的数据结构,由多个列组成,每一列可以是不同的类型。可以使用data.frame()函数创建数据框,每列可以是不同类型的数据(例如字符型、数值型、逻辑型等)
data.frame(...)
其中(…) 表示可以传入多个参数,每个参数对应数据框的一个列。
例如:
df <- data.frame(name = c("John", "Alice", "Bob"), age = c(30, 25, 35), score = c(80, 85, 90))
数据框中的列可以通过名称来访问,例如:df$name或df[["name"]]。
数据框也可以通过行列索引来访问,例如:df[1, 2]表示访问数据框df的第一行第二列的元素。
六、数据的导入和导出
r导入和导出数据分为二进制数据和其他常见的数据格式。
1. 二进制数据
导入二进制数据
# 使用load()函数加载二进制数据文件
load("data.RData")
导出二进制数据
# 使用save()函数将R对象保存为二进制数据文件
save(data, file = "data.RData")
2.txt 文件
导入 txt 文件
write.table(x, file, append = FALSE, quote = TRUE, sep = " ", eol = "\n", na = "NA", dec = ".", row.names = TRUE, col.names = TRUE, ...)
x: 要写入文件的数据框或矩阵。
file: 要写入的文件路径。
append: 一个逻辑值,指定是否在文件末尾追加内容,默认为 FALSE。
quote: 一个逻辑值,指定是否在字符型数据周围加上引号,默认为 TRUE。
sep: 字段之间的分隔符,默认为一个空格。
eol: 行末的分隔符,默认为换行符。
na: 指定如何表示缺失值,默认为 “NA”。
dec: 指定小数点的字符,默认为 “.”。
row.names 和 col.names: 逻辑值,指定是否写入行名和列名,默认为 TRUE。
…: 其他参数。
导出 txt 文件
3.CSV 文件
导入 CSV 文件
# 使用read.csv()函数导入CSV文件
data <- read.csv("data.csv", header = TRUE)
导出 CSV 文件
write.csv(x, file, append = FALSE, quote = TRUE, sep = ",", eol = "\n", na = "NA", row.names = TRUE, col.names = TRUE, ...)
其中参数含义与write.table()相似
4.Excel 文件
导入 Excel 文件
# 使用readxl包导入Excel文件
library(readxl)
data <- read_excel("data.xlsx", sheet = 1)
导出 Excel 文件
libary(openxlsx)
write.xlsx(x, file, asTable = FALSE, overwrite = TRUE, ...)
x: 数据框或一个(命名的)对象列表。
file: 要保存xlsx文件的文件路径。
asTable: 如果为TRUE,将使用writeDataTable()而不是writeData()来将x写入文件(默认值:FALSE)。
overwrite: 覆盖现有文件(默认为TRUE,与write.table一样)。

















 6639
6639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









